音声合成市場規模・シェア分析:成長動向と予測 (2025年 – 2030年)
音声合成市場は、コンポーネント(ソフトウェアおよびサービス)、導入形態(クラウドベース、オンプレミス、エッジ組み込み型)、音声タイプ(ニューラル/AIベース、標準連結型、ハイブリッド)、用途(消費者向けメディア・エンターテイメント、eラーニング・教育、顧客サービスなど)、言語(英語、スペイン語、ヒンディー語、中国語など)、および地域別に分類されます。市場予測は金額(米ドル)で提供されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
テキスト読み上げ(Text-to-Speech、TTS)市場の概要について、詳細をまとめさせていただきます。
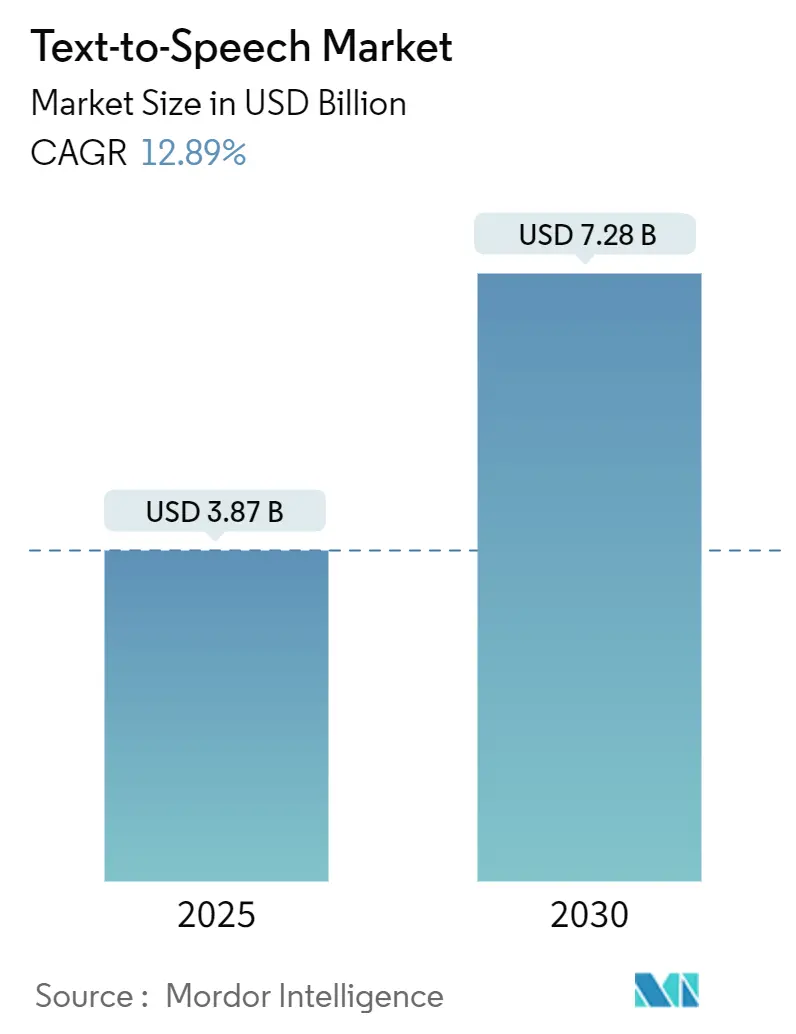
市場規模と成長予測
テキスト読み上げ市場は、2025年には38.7億米ドルと評価されており、2030年までに72.8億米ドルに達すると予測されています。この期間における年平均成長率(CAGR)は12.89%と見込まれています。地域別では、北米が最大の市場であり、アジア太平洋地域が最も急速に成長する市場となっています。市場の集中度は中程度です。
市場分析の概要
この堅調な成長見通しは、ニューラルネットワークのブレークスルー、厳格化するアクセシビリティ要件、および成熟したエッジAIハードウェアが、合成音声を単なる利便性機能から中核的なインターフェース戦略へと昇格させていることを反映しています。企業は、顧客サポート、車載アシスタント、適応型学習ツールにブランドの音声を組み込んでおり、ハイパースケールクラウドプラットフォームは言語カバー範囲と音声のリアリズムで競争しています。
データプライバシーを重視し、低遅延で組み込みチップ上での音声処理に対する需要が高まっており、自動車、産業用IoT、ヘルスケアデバイスがオフライン機能を必要とすることから、テキスト読み上げ市場の対象範囲がさらに拡大しています。また、合成音声IPのライセンスモデルは、同意を得た音声データを確保し、クローニングの悪用から保護できるベンダーに新たな収益源をもたらしています。
主要なレポートのポイント(セグメント分析)
* コンポーネント別: 2024年にはソフトウェアが市場シェアの76.30%を占めましたが、サービスは2030年までに13.20%のCAGRで拡大すると予測されています。
* 展開モード別: 2024年にはクラウドソリューションが市場規模の63.80%を占めましたが、エッジ組み込み型ソリューションは14.50%のCAGRで最も速く成長しています。
* 音声タイプ別: ニューラル/AI音声が2024年に67.90%の収益シェアを占め、他のすべてのタイプを上回る15.60%のCAGRで成長しています。
* アプリケーション別: 2024年には顧客サービス/IVRが市場規模の31.30%を占めましたが、自動車および交通機関は2030年までに14.80%のCAGRで成長しています。
* 言語別: 2024年には英語が52.40%のシェアを占めましたが、ヒンディー語は13.70%のCAGRで最も急速に増加すると予測されています。
* 地域別: 北米が2024年に37.20%のシェアで市場を支配しましたが、アジア太平洋地域は2030年までに15.30%のCAGRで最も急速に成長する地域です。
グローバルテキスト読み上げ市場のトレンドと洞察(推進要因)
* 音声対応デバイスとスマートスピーカーの普及: スマートスピーカーのOEMは、自然な音声出力に依存する大規模言語モデルを組み込み、デバイスのエンゲージメントを高めています。エッジ最適化モデルは、プライバシーと稼働時間のためにローカルで音声を生成する必要があるIoTセンサー、サーモスタット、ウェアラブルデバイスにも電力を供給しています。
* ニューラルTTSによる人間のような品質の急速な向上: ニューラルアーキテクチャは、イントネーション、ペース、感情をモデル化することを可能にし、20以上の言語で同時に自然さを向上させています。遅延もほとんどのクラウドAPIでリアルタイムに低下し、知覚できる遅延なしに会話型サポートやインタラクティブメディアを展開できるようになりました。
* eラーニングとデジタルコンテンツ消費の拡大: アジア太平洋地域のデジタル教室では、学生の81%が生成AIを使用しており、方言や学習者の好みに適応するナレーションへの需要が高まっています。多言語音声は、音声ナレーションの才能が不足している地域で出版社が視聴者にリーチするのに役立ちます。
* デジタルアクセシビリティの義務化(Section 508、WCAG): 連邦規則により、電子文書やウェブインターフェースは視覚障害者にとって利用可能である必要があり、米国政府機関に販売されるソフトウェアにはスクリーンリーダーとTTSサポートが義務付けられています。
* エッジAIアクセラレーターによるオフラインTTS: データプライベートで低遅延の音声処理を可能にし、自動車や産業用IoTなどの分野でオフライン機能の需要を拡大しています。
* 合成音声IPライセンス: 同意を得た音声データとクローニングの悪用に対する防御を確保できるベンダーに、新たな収益源をもたらしています。
阻害要因
* 声調言語およびリソースの少ない言語における精度の限界: アジア太平洋地域やアフリカ地域において、モデルアーキテクトは微妙なピッチの輪郭や形態論を持つ言語への対応に課題を抱えています。
* クラウドTTSにおけるデータプライバシーの懸念: GDPRやCISAの選挙セキュリティ勧告、消費者の意識の高まりにより、企業は音声をローカルで処理することを求めています。
* 音声クローニングの悪用による信頼の低下: 米国連邦取引委員会(FTC)は、生体認証セキュリティを損なう詐欺シナリオを強調し、クローニングのリスクに注目しています。OpenAIが15秒のサンプルから音声を複製できる能力や、スピーカーIDシステムに対する95-97%の攻撃成功率を示す研究は、生成と検出の技術的ギャップを浮き彫りにしています。
* GPUコンピューティングコストの増加: グローバルに影響を及ぼし、コスト効率が課題となっています。
セグメント分析の詳細
* コンポーネント別: ソフトウェアが市場の基盤を形成する一方で、カスタム音声、多言語展開、音声調整、文化的な検証、継続的な品質保証を求める企業の需要により、サービス収益が急速に拡大しています。
* 展開モード別: クラウドソリューションが依然として優勢ですが、データ主権とリアルタイムの信頼性への構造的な転換を反映し、エッジ組み込み型展開が最も速く成長しています。自動車のユースケースでは、携帯電話の電波が途切れても車載アシスタントが応答し、生体認証音声を同意なしに車外に送信しないことが求められます。
* 音声タイプ別: ニューラル音声は、話者の意図を学習し、強調を動的に調整することで、オーディオブックのリスナーがより長く再生するような物語の共鳴を提供します。GPUコストの低下と量子化の改善により、ニューラル音声は2030年よりかなり前に80%以上の普及率を超えると予想されています。
* アプリケーション別: 顧客サービス/IVRが最大のシェアを占めていますが、電気自動車のダッシュボードがナビゲーション、インフォテインメント、気候制御を音声中心のハブに統合することで、自動車アシスタントが最も速い成長を遂げています。
* 言語別: 英語が依然として最も使用されていますが、インドのデジタル公共財アジェンダに代表されるように、非英語圏のユーザーベースにサービスを提供する必要性から、ヒンディー語の成長が顕著です。
地域分析
* 北米: Section 508の調達フィルターにより、音声出力が連邦政府向けソフトウェアの必須項目となっていることが市場を牽引しています。米国のクラウドハイパースケーラーは、TTSを広範なAIスイートとバンドルし、スタートアップ企業の参入障壁を下げています。
* アジア太平洋: スマートフォンの普及と音声入力への消費者の慣れにより、最も急速な地域成長を遂げています。中国のAI刺激策やインドのデジタル公共インフラプロジェクトは、大規模な現地語サポートを必要とし、API消費を促進しています。
* ヨーロッパ: GDPRや各国のアクセシビリティ法規に支えられ、着実な導入が続いています。ドイツの自動車サプライヤーは、車載安全要件を満たすためにローカル音声処理を組み込み、フランスやスペインの放送局は多言語視聴者に対応するためにローカライゼーションに投資しています。
競争環境
テキスト読み上げ市場は中程度の断片化を示しています。Amazon、Google、Microsoftは、グローバルなクラウドフットプリントと継続的なモデル更新を活用して優位に立っています。一方、CerenceやiFlytekのような専門ベンダーは、自動車統合やネイティブ言語の専門知識で差別化を図っています。音声クローニングに関する規制圧力は参入障壁を高めており、ベンダーは同意確認、ウォーターマーク、悪用監視を提供する必要があります。
エッジファーストの挑戦者は、サブ1Wのマイクロコントローラー向けに量子化されたニューラルネットワークを最適化し、ネットワーク接続に依存できない産業用IoTや医療機器をターゲットにしています。Nvidiaは音声合成IPに投資し、チップパートナーにライセンス供与することでロイヤリティ収入と防御的障壁を構築しています。ElevenLabsのような成長段階の企業は、ポッドキャスターやゲームデザイナーにアピールするスタジオ品質のクローニングを提供するクリエイターエコノミーツールに焦点を当てていますが、今後の開示規則に対応する必要があります。
最近の業界動向
* 2025年2月: MicrosoftはAzure AI Speechを更新し、インドのキャラクターであるAartiとArjunを含む13の刷新されたHD音声と14の新しいHD音声を追加し、地域展開をサポートしました。
* 2025年1月: Consumer ReportsはAI音声クローニングレポートを発表し、6社のうち4社が非同意のクローニングに対する保護策を欠いていることを指摘し、FTCの新たな関心を促しました。
* 2024年10月: RenaultはCerenceと提携し、Renault 5 E-Tech EVに会話型で感情認識可能な車載音声アシスタント「Renoコンパニオン」を組み込みました。
* 2024年7月: NICTは21言語対応の高速ニューラルTTSシステムを発表し、高忠実度での多言語スケーラビリティを実証しました。
以上が、テキスト読み上げ市場の概要に関する詳細なまとめとなります。
レポート詳細の要約
本レポートは、グローバルなText-to-Speech(TTS)市場に関する包括的な分析を提供しています。TTS市場は、書かれた文字を知的で人間らしい音声に変換するソフトウェアおよび関連サービスから生じる収益として定義され、クラウド、オンプレミス、エッジ展開を対象としています。ハードウェアマイク、音声認識エンジン、生体認証は範囲外とされています。
市場規模と成長予測
TTS市場は、2025年には39.7億米ドルに達すると予測されており、2030年までに年平均成長率(CAGR)15.96%で成長し、83.2億米ドルに達すると見込まれています。サービス部門は、カスタム音声作成や多言語展開のアウトソーシング需要により、CAGR 13.20%で拡大しています。
市場の推進要因
市場成長の主な推進要因は以下の通りです。
* 音声対応デバイスやスマートスピーカーの普及。
* ニューラルTTS技術の急速な進歩による、ほぼ人間品質の音声生成。
* Eラーニングおよびデジタルコンテンツ消費の拡大。
* デジタルアクセシビリティに関する法的義務(Section 508、WCAGなど)。
* 組み込みIoTにおけるオフラインTTSを可能にするエッジAIアクセラレータの登場。
* 合成音声IPライセンスによる新たな収益源の創出。
市場の阻害要因
一方で、市場にはいくつかの課題も存在します。
* 声調言語やリソースの少ない言語における精度上の限界。
* クラウドベースTTSにおけるデータプライバシーに関する懸念。
* 音声クローンやディープフェイクの悪用によるユーザー信頼の低下。
* 小規模ベンダーにとってのGPUコンピューティングコストの高騰。
セグメンテーションの概要
市場は以下の要素で詳細に分析されています。
* コンポーネント別: ソフトウェア、サービス。
* 展開モード別: クラウドベース、オンプレミス、エッジ組み込み。エッジ展開はCAGR 14.50%で増加していますが、ローカルプライバシーとクラウドのスケーラビリティを組み合わせたハイブリッドモデルが2030年まで共存すると予測されています。
* 音声タイプ別: ニューラル/AIベース、標準連結型、ハイブリッド。
* アプリケーション別: 消費者向けメディア・エンターテイメント、Eラーニング・教育、視覚障害者向けアクセシビリティ、顧客サービス/IVR、自動車・交通、ヘルスケア支援、ロボティクス・IoT、その他。自動車分野は、安全で注意散漫にならないインタラクションのための低遅延・オンデバイス音声の必要性から、CAGR 14.80%で最も急速に成長しているアプリケーションです。
* 言語別: 英語、中国語、スペイン語、ヒンディー語、ドイツ語、フランス語、トルコ語、その他。
* 地域別: 北米、南米、ヨーロッパ、アジア太平洋、中東・アフリカ。
競争環境
レポートでは、市場集中度、戦略的動向、市場シェア分析、および主要ベンダー(Amazon Web Services、Google LLC、Microsoft Corporation、IBM Corporation、iFlytek Co., Ltd.、Baidu, Inc.など)の企業プロファイルが提供されています。
将来の展望と機会
規制はTTSの導入に大きな影響を与えています。Section 508や欧州のアクセシビリティ法は、音声対応コンテンツを義務付けており、これが企業におけるTTS統合の一貫した需要ドライバーとなっています。音声クローンは生体認証セキュリティを迂回し、消費者の信頼を損なうリスクがあるため、堅牢な同意および検出メカニズムを持つベンダーが有利になると考えられます。
調査方法論
本調査は、一次調査(クラウドプラットフォームアーキテクト、Eラーニングインテグレーター、支援技術販売業者へのインタビュー)と二次調査(ITU、WHO、OECDなどの公開データ、業界団体のホワイトペーパー、企業報告書など)を組み合わせた堅牢な方法論に基づいています。市場規模の算出と予測には、トップダウンモデルとボトムアップチェックが併用され、多変量回帰分析やシナリオ分析が適用されています。データは毎年更新され、重要なイベントに応じて中間パッチが適用されます。

1. はじめに
- 1.1 調査の前提と市場の定義
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
- 4.2 市場の推進要因
- 4.2.1 音声対応デバイスとスマートスピーカーの普及
- 4.2.2 人間に近い品質を実現するニューラルTTSの急速な進歩
- 4.2.3 eラーニングとデジタルコンテンツ消費の拡大
- 4.2.4 デジタルアクセシビリティの義務化(セクション508、WCAG)
- 4.2.5 エッジAIアクセラレータによる組み込みIoTでのオフラインTTSの実現
- 4.2.6 合成音声IPライセンスによる新たな収益源の開拓
- 4.3 市場の阻害要因
- 4.3.1 声調言語およびリソースの少ない言語における精度制限
- 4.3.2 クラウドベースTTSにおけるデータプライバシーの懸念
- 4.3.3 音声クローン/ディープフェイクの悪用増加によるユーザー信頼の低下
- 4.3.4 小規模ベンダーにとってのGPU計算コストの高騰
- 4.4 業界エコシステム分析
- 4.5 技術的展望
- 4.6 ポーターの5つの力分析
- 4.6.1 買い手の交渉力
- 4.6.2 供給者の交渉力
- 4.6.3 新規参入者の脅威
- 4.6.4 代替品の脅威
- 4.6.5 競争の激しさ
5. 市場規模と成長予測(数値)
- 5.1 コンポーネント別
- 5.1.1 ソフトウェア
- 5.1.2 サービス
- 5.2 展開モード別
- 5.2.1 クラウドベース
- 5.2.2 オンプレミス
- 5.2.3 エッジ組み込み
- 5.3 音声タイプ別
- 5.3.1 ニューラル/AIベース
- 5.3.2 標準連結型
- 5.3.3 ハイブリッド
- 5.4 アプリケーション別
- 5.4.1 コンシューマーメディアおよびエンターテイメント
- 5.4.2 Eラーニングおよび教育
- 5.4.3 視覚障害者向けアクセシビリティ
- 5.4.4 カスタマーサービス/IVR
- 5.4.5 自動車および輸送
- 5.4.6 ヘルスケア支援
- 5.4.7 ロボティクスおよびIoT
- 5.4.8 その他のアプリケーション
- 5.5 言語別
- 5.5.1 英語
- 5.5.2 中国語
- 5.5.3 スペイン語
- 5.5.4 ヒンディー語
- 5.5.5 ドイツ語
- 5.5.6 フランス語
- 5.5.7 トルコ語
- 5.5.8 その他の言語
- 5.6 地域別
- 5.6.1 北米
- 5.6.1.1 米国
- 5.6.1.2 カナダ
- 5.6.1.3 メキシコ
- 5.6.2 南米
- 5.6.2.1 ブラジル
- 5.6.2.2 アルゼンチン
- 5.6.2.3 その他の南米諸国
- 5.6.3 ヨーロッパ
- 5.6.3.1 イギリス
- 5.6.3.2 ドイツ
- 5.6.3.3 フランス
- 5.6.3.4 イタリア
- 5.6.3.5 スペイン
- 5.6.3.6 ロシア
- 5.6.3.7 その他のヨーロッパ諸国
- 5.6.4 アジア太平洋
- 5.6.4.1 中国
- 5.6.4.2 インド
- 5.6.4.3 日本
- 5.6.4.4 韓国
- 5.6.4.5 オーストラリアおよびニュージーランド
- 5.6.4.6 その他のアジア太平洋諸国
- 5.6.5 中東およびアフリカ
- 5.6.5.1 中東
- 5.6.5.1.1 サウジアラビア
- 5.6.5.1.2 アラブ首長国連邦
- 5.6.5.1.3 トルコ
- 5.6.5.1.4 その他の中東諸国
- 5.6.5.2 アフリカ
- 5.6.5.2.1 南アフリカ
- 5.6.5.2.2 ナイジェリア
- 5.6.5.2.3 その他のアフリカ諸国
6. 競合情勢
- 6.1 市場集中度
- 6.2 戦略的動向
- 6.3 市場シェア分析
- 6.4 企業プロファイル(グローバルレベルの概要、市場レベルの概要、主要セグメント、入手可能な財務情報、戦略情報、主要企業の市場ランキング/シェア、製品とサービス、および最近の動向を含む)
- 6.4.1 Amazon Web Services, Inc. (Amazon Polly)
- 6.4.2 Google LLC (Cloud TTS)
- 6.4.3 Microsoft Corporation (Azure Cognitive Services)
- 6.4.4 IBM Corporation (Watson TTS)
- 6.4.5 iFlytek Co., Ltd.
- 6.4.6 Baidu, Inc.
- 6.4.7 Nuance Communications (Microsoft)
- 6.4.8 ReadSpeaker B.V.
- 6.4.9 Acapela Group
- 6.4.10 CereProc Ltd.
- 6.4.11 NeoSpeech Inc.
- 6.4.12 Lovo Inc.
- 6.4.13 Murf AI
- 6.4.14 WellSaid Labs
- 6.4.15 Speechify Inc.
- 6.4.16 Synthesys.io
- 6.4.17 Veritone Inc.
- 6.4.18 Sensory Inc.
- 6.4.19 Descript Inc.
- 6.4.20 SoundHound AI, Inc. (Houndify)
7. 市場機会と将来の見通し
*** 本調査レポートに関するお問い合わせ ***

音声合成とは、テキスト情報(文字データ)を人間の音声に変換する技術を指します。この技術の究極的な目標は、単に文字を読み上げるだけでなく、人間が話すような自然さ、抑揚、感情、そして個性を持った音声を生成することにあります。初期の音声合成は、機械的で不自然な音声が主流でしたが、長年の研究開発と技術革新を経て、現在では非常に高品質で人間と区別がつきにくいレベルの音声生成が可能になっています。これは、情報伝達の手段を多様化し、私たちの生活や社会活動に深く貢献する基盤技術の一つとして位置づけられています。
音声合成の技術は、その進化の過程でいくつかの主要な方式に分類されます。まず、連結型音声合成があります。これは、事前に録音された大量の音声データから、音素(母音や子音の最小単位)、ダイフォン(音素の連結部分)、トライフォンといった小さな音声単位を切り出し、それらを適切に連結して音声を生成する方式です。この方式は、データベースの品質に依存するため、高品質なデータベースがあれば非常に自然な音声が得られやすいという利点がありますが、データベースの構築には多大なコストと労力がかかり、また、感情表現や話速の柔軟な調整が難しいという課題も抱えていました。次に、パラメトリック型音声合成が登場しました。この方式では、音声のピッチ、フォルマント、スペクトルといった音響特徴を数学的なパラメータとしてモデル化し、これらのパラメータを操作することで音声を生成します。代表的なものにHMM(隠れマルコフモデル)ベースの音声合成があり、データ量が少なく、話速やピッチなどの音声特徴を比較的柔軟に操作できるという利点がありました。しかし、連結型に比べて、生成される音声がやや機械的で自然さに欠ける傾向があるという課題がありました。そして、近年主流となっているのが、ニューラルネットワーク型音声合成、あるいはエンドツーエンド型音声合成と呼ばれる方式です。これは、深層学習(ディープラーニング)技術を基盤としており、テキスト情報から直接、または中間表現を介して音声を生成します。Tacotron、WaveNet、Transformer-TTS、VITSといったモデルが代表的で、大量のテキストと音声のペアデータを学習することで、従来の方式では実現が難しかった、非常に自然で人間らしい抑揚やリズムを持った音声を生成できるようになりました。さらに、特定の人物の声を模倣する音声クローニングや、多様な感情表現、歌声の合成なども可能になり、その表現力は飛躍的に向上しています。この方式は、データ駆動型であるため、高品質な音声データと膨大な計算資源が必要ですが、その性能は目覚ましく、今後のさらなる進化が期待されています。
音声合成技術は、私たちの日常生活からビジネス、エンターテイメントまで、非常に幅広い分野で活用されています。最も身近な例としては、スマートフォンのAIアシスタント(Siri、Alexa、Google Assistantなど)やスマートスピーカーが挙げられます。これらは、ユーザーの質問に音声で応答することで、情報検索やデバイス操作をサポートしています。また、アクセシビリティの分野では、視覚障害者向けのスクリーンリーダーや、ウェブサイトの読み上げ機能として不可欠な技術です。これにより、情報へのアクセスが困難な人々が、より多くの情報に触れる機会を得ています。ナビゲーションシステムでは、カーナビゲーションや公共交通機関の車内アナウンス、駅構内の案内放送などで、目的地までの道案内や運行状況を音声で提供し、利用者の利便性を高めています。カスタマーサービスの領域では、IVR(Interactive Voice Response)システムやチャットボットの音声応答として導入され、顧客からの問い合わせ対応や情報提供を自動化し、業務効率の向上に貢献しています。エンターテイメント分野では、オーディオブックの朗読、ゲームキャラクターのセリフ、バーチャルYouTuber(VTuber)の音声、動画コンテンツのナレーションなど、多様なコンテンツ制作に利用され、表現の幅を広げています。教育分野では、語学学習アプリでの発音モデルや、教材の読み上げ、eラーニングコンテンツの作成に活用されています。その他にも、工場での作業指示や警告音、医療現場での患者への情報提供、リハビリテーション支援など、多岐にわたる産業や社会インフラにおいて、音声合成は重要な役割を担っています。
音声合成は単独で機能するだけでなく、他の様々な技術と密接に連携することで、その真価を発揮します。最も重要な関連技術の一つが自然言語処理(NLP)です。音声合成はテキストを音声に変換するため、入力されたテキストがどのような意味を持ち、どのように発音されるべきかを正確に理解する必要があります。NLPは、テキストの形態素解析、構文解析、意味解析を行い、適切な発音記号やアクセント、ポーズ情報を生成する役割を担います。また、音声合成と対をなす技術として音声認識(ASR)があります。音声認識は人間の音声をテキストに変換する技術であり、スマートスピーカーやAIアシスタントでは、ユーザーの音声入力を音声認識でテキスト化し、そのテキストに対する応答を音声合成で生成するという形で、両者が連携して機能しています。機械学習や深層学習(ML/DL)は、特にニューラルネットワーク型音声合成の基盤となる技術であり、大量のデータから音声の特徴やパターンを学習し、より自然で高品質な音声を生成するために不可欠です。音声信号処理(DSP)は、音声の分析、合成、加工を行うための基本的な技術であり、音声合成の各段階で利用されます。さらに、感情認識技術は、テキストや文脈から感情を推定し、その感情を反映した音声を合成するために重要です。話者認識や話者分離の技術は、特定の人物の声を識別したり、複数の話者の音声を分離したりする際に用いられ、音声クローニング技術と組み合わせることで、特定の人物の声質や話し方を模倣した音声を生成することが可能になります。これらの技術が複合的に作用することで、より高度でパーソナライズされた音声体験が実現されています。
音声合成市場は、近年、目覚ましい成長を遂げており、その背景にはいくつかの要因があります。最も大きな推進力となっているのは、AI技術、特に深層学習の飛躍的な進歩です。これにより、生成される音声の品質が劇的に向上し、人間と区別がつかないほどの自然さを実現できるようになりました。この技術革新が、新たな応用分野の開拓と既存サービスの高度化を加速させています。また、クラウドベースの音声合成サービスの普及も市場拡大に大きく貢献しています。Amazon Web Services (AWS) のPolly、Google Cloud Text-to-Speech、Microsoft Azure Cognitive Services Speechといった大手クラウドプロバイダーが提供するサービスは、開発者が手軽に高品質な音声合成機能をアプリケーションに組み込めるようにし、導入障壁を大幅に下げました。これにより、中小企業やスタートアップでも音声合成技術を活用しやすくなっています。市場の需要面では、多言語対応や多様な話者スタイル、感情表現へのニーズが高まっています。グローバルなビジネス展開や、よりパーソナライズされたユーザー体験の提供が求められる中で、単一の機械的な声ではなく、様々な言語、性別、年齢、感情を表現できる音声合成が重視されています。アクセシビリティの向上、スマートデバイスの普及、そしてコンテンツ制作の多様化も市場を牽引する重要な要素です。視覚障害者支援、スマートスピーカーやAIアシスタントの普及、オーディオブックや動画コンテンツの増加は、音声合成技術の利用機会を拡大させています。一方で、音声合成技術の悪用、例えばディープフェイク音声による詐欺や誤情報の拡散、著作権やプライバシーに関する倫理的な課題も浮上しており、技術の発展と並行して、これらの問題への対応が求められています。
音声合成技術の将来は、さらなる進化と多様な応用可能性に満ちています。最も期待されるのは、生成される音声のさらなる自然さの追求です。現在の技術でも非常に高品質な音声が生成できますが、人間が話す際の微細な息遣いや間、感情の揺らぎといった要素を完全に再現し、人間と区別がつかないレベルの音声を実現することが究極の目標となるでしょう。感情表現の高度化も重要なテーマです。喜び、悲しみ、怒り、驚きといった基本的な感情だけでなく、より複雑で微妙な感情のニュアンスを音声に込める技術が発展することで、より豊かなコミュニケーションが可能になります。また、話者スタイルの多様化も進み、特定の話し方やアクセント、さらには歌声の合成など、個性的で表現力豊かな音声が生成できるようになるでしょう。リアルタイム性の向上は、インタラクティブな会話システムにおいて不可欠です。遅延なく、自然な会話のテンポで応答できる音声合成は、AIアシスタントやチャットボットのユーザー体験を劇的に向上させます。パーソナライゼーションも進み、ユーザー個人の好みや状況に合わせて、声質、話し方、感情表現をカスタマイズできる機能が一般的になるかもしれません。将来的には、音声合成は多モーダルAIとの融合を深めていくと考えられます。視覚、聴覚、触覚など複数の情報を統合的に処理するAIシステムの中で、音声合成は重要な出力手段の一つとして機能し、より人間らしいインタラクションを実現するでしょう。一方で、技術の進化に伴う倫理的課題への対応も不可欠です。ディープフェイク音声の悪用防止策、生成された音声の透明性確保、著作権やプライバシー保護に関するガイドラインの策定など、社会的な側面からの議論と対策が求められます。これらの課題を克服しつつ、医療、教育、エンターテイメント、そして新たな産業分野において、音声合成技術は私たちの生活をより豊かで便利なものに変えていく可能性を秘めています。