自然言語生成市場:規模・シェア分析ー成長トレンドと予測 (2025年~2030年)
自然言語生成市場レポートは、コンポーネント(ソフトウェア、およびサービス)、展開モード(オンプレミス、およびクラウド)、組織規模(大企業、および中小企業)、産業分野(BFSI、ヘルスケア・ライフサイエンス、小売・Eコマース、メディア・エンターテイメント、製造業、およびその他の産業分野)、ならびに地域によって分類されます。市場予測は、金額(米ドル)で提供されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
自然言語生成(NLG)市場の概要:2030年までの成長トレンドと予測
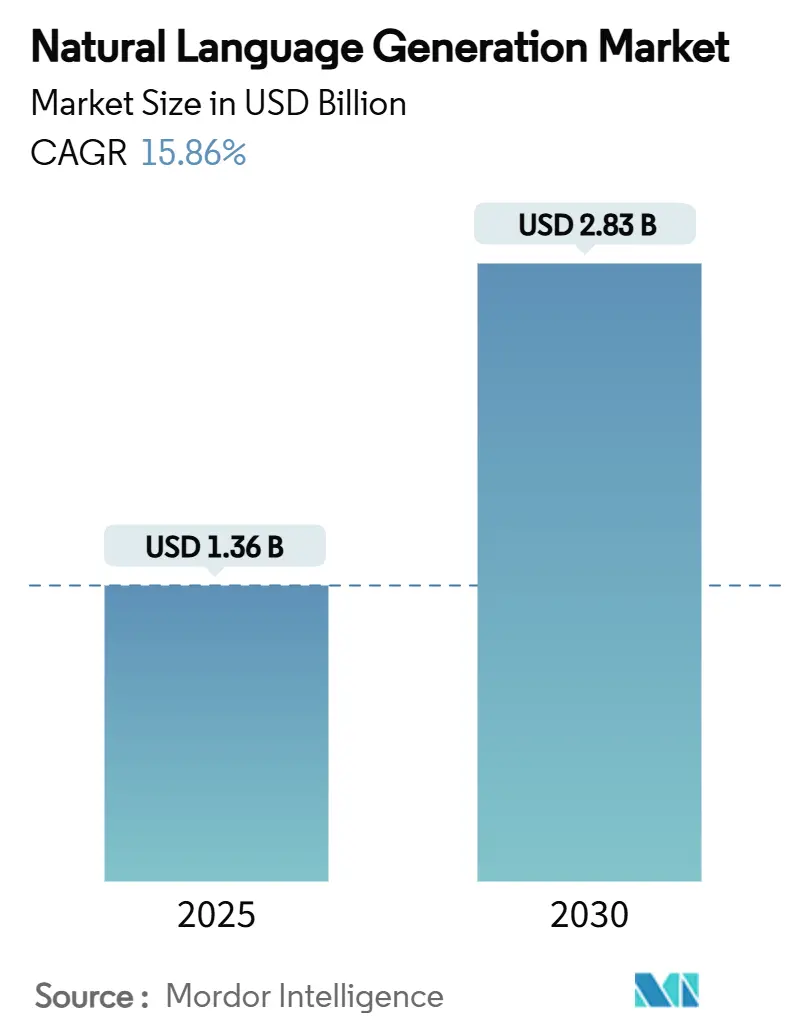
自然言語生成(NLG)市場は、2025年には13.6億米ドルに達し、2030年には28.3億米ドルに成長すると予測されており、予測期間中の年平均成長率(CAGR)は15.86%と見込まれています。この成長は、文脈に応じた多言語コンテンツに対する企業需要の増加、大規模言語モデル(LLM)の推論コストの低下、そしてクラウドとエッジ展開オプションの拡大によって支えられています。小売、金融サービス、ヘルスケアといった分野の早期導入企業は、ハイパーパーソナライズされたコンテンツの自動化から具体的な利益を上げており、API価格の低下は中小企業にとっての参入障壁を低くしています。また、IoTや自動車アプリケーションにおける自律エージェント向けに、エッジ最適化された軽量モデルがリアルタイムのナラティブ生成を可能にしています。EU AI法のような規制枠組みは、説明可能なAIを奨励し、規制の厳しいセクターにおいて透明性と言語的洗練さを両立させるハイブリッドNLGアーキテクチャへの移行を促しています。
# 主要なレポートのポイント
* コンポーネント別: ソフトウェアが2024年に69.04%の市場シェアを占めましたが、サービスは2030年までに19.35%のCAGRで最も速く成長すると予測されています。
* 展開モード別: クラウドソリューションが2024年に62.87%の市場規模を占めましたが、エッジ対応のハイブリッドアーキテクチャは17.28%のCAGRで進展しています。
* 組織規模別: 大企業が2024年に57.61%の市場シェアを占めましたが、中小企業は2025年から2030年にかけて19.05%のCAGRで成長しています。
* 業界垂直別: BFSI(銀行・金融サービス・保険)が2024年に23.47%の収益シェアでリードしましたが、ヘルスケア・ライフサイエンスは2030年までに18.62%のCAGRで成長すると予測されています。
* 地域別: 北米が2024年に38.51%の収益シェアで市場を支配しましたが、アジア太平洋地域は2030年までに20.09%のCAGRで最も速く成長すると予測されています。
# グローバルNLG市場のトレンドと洞察
促進要因
1. ハイパーパーソナライズされたコンテンツによるROI向上:
NLGをマーケティング、サービス、運用に導入する企業は、コンバージョン率が最大25%向上し、ROIが3倍以上になることを報告しています。リアルタイムのパーソナライゼーションエンジンは、顧客行動のシグナルを動的な製品説明や投資概要に統合し、何百万ものインタラクションでブランドの一貫性を保ちます。非技術者でもテンプレート設計ツールを利用できるようになり、採用が加速しています。
2. Gen-AIコパイロットと自律エージェントのためのリアルタイムナラティブ生成:
コパイロットのサブ秒単位の遅延要件により、メモリ効率の高いモデル量子化と高スループットのエッジ推論スタックへのアーキテクチャの優先順位がシフトしています。顧客サービスエージェントは、クラウドへの往復なしに文脈に応じた説明、行動理由、フォローアップ指示を生成する必要があり、人間による監視と規制監査の両方をサポートします。自動車OEMは、車載インフォテインメントユニットに小型言語モデルを組み込み、音声案内や車両ヘルス概要を提供しています。
3. LLM推論コストの急速な低下による中小企業での採用拡大:
APIプロバイダーは2024年から2025年にかけてトークン料金を最大50%削減し、企業グレードのNLGをリソースが限られた企業でも手頃な価格で利用できるようにしました。ボリュームディスカウントや従量課金制により、最低契約額のハードルが取り除かれ、多言語ベースモデルはTier-2言語にも対応しています。これにより、中小企業は自動化された製品説明、ナレッジベース記事、顧客サポートスクリプトを数週間で統合できるようになり、特に新興国市場でのNLG市場浸透が加速しています。
4. 説明可能なAIに対する規制圧力:
EU AI法やSECの予測分析規則は、アルゴリズム出力に対する監査可能な根拠を要求しており、金融機関やヘルスケア機関はテンプレートベースまたはハイブリッドNLGシステムに傾倒しています。ルールベースの足場層は、生成出力を事前定義されたドメインに制限し、ハルシネーションのリスクを最小限に抑え、コンプライアンス報告を簡素化します。
5. 新興市場における多言語CX自動化の需要:
新興市場では、Tier-2言語を含む多言語カスタマーエクスペリエンス(CX)自動化への需要が高まっています。
6. IoTデバイスや自動車における軽量NLGモデルのエッジ展開:
IoTデバイスや自動車における軽量NLGモデルのエッジ展開は、ネットワーク混雑を回避し、サービス継続性を確保するために重要です。
抑制要因
1. 高品質なドメイン固有の学習データの不足:
キュレーションされた業界データセットは依然として不足しており、企業はデータクレンジングとアノテーションに予算の最大90%を費やすため、プロジェクトのタイムラインが長くなります。ヘルスケア分野ではHIPAAの下でのプライバシー上のハードルがあり、正確な要約に不可欠な臨床記録へのアクセスが制限されます。新興市場では、現地語の技術コーパスの不足が同様に展開を遅らせ、NLG市場の成長軌道を抑制しています。
2. AI生成の誤情報と法的責任に関する懸念の増大:
フォーチュン500企業は2022年以降、AIリスク開示を4倍に増やしており、コンテンツの正確性と下流の責任に関する不確実性の高まりを反映しています。メディア企業は意図しない事実誤認による評判の損害を懸念し、保険会社はAI関連の請求に対する新しい保険カテゴリの価格設定に苦慮しています。
3. レガシーコンテンツ管理スタックとの統合の複雑さ:
既存のコンテンツ管理システムとの統合は複雑であり、特に確立されたITインフラを持つ大企業にとっては課題となります。
4. 独自のモデルエコシステムによるベンダーロックイン:
独自のモデルエコシステムに起因するベンダーロックインは、企業が特定のプロバイダーに依存するリスクを高めます。
# セグメント分析
* コンポーネント別: ソフトウェアが市場シェアの大部分を占めていますが、プロンプトエンジニアリング、ワークフロー統合、継続的なモデルガバナンスにおける専門知識の需要が高まっているため、サービス収益は19.35%のCAGRで増加しています。この変化は、NLG市場の対象範囲を広げ、コンサルティング会社をソフトウェアベンダーと並ぶ主要な価値創造者として位置付けています。
* 展開モード別: クラウドプラットフォームが2024年にNLG市場規模の62.87%を占めましたが、クラウドトレーニングとエッジ推論を組み合わせたハイブリッドアーキテクチャは17.28%のCAGRで拡大しています。組織は、高複雑度クエリをクラウドモデルにルーティングしつつ、低遅延タスクをローカルで処理することで、データレジデンシー要件へのコンプライアンスを達成しています。
* 組織規模別: 大企業はオムニチャネルの顧客コミュニケーションスイートや規制報告パイプラインにNLGを組み込むことで、2024年に57.61%の市場シェアを占めました。しかし、中小企業は低コミットメントのAPI価格設定とローコードオーケストレーションダッシュボードを背景に、19.05%のCAGRで最も速く成長している層です。
* 業界垂直別: BFSIは2024年に23.47%の収益シェアで最大の採用者でしたが、ヘルスケア・ライフサイエンスは、病院が臨床文書、退院サマリー、保険コーディングナラティブを自動化するにつれて、全垂直市場の中で最も速い18.62%のCAGRで成長すると予測されています。製造業は多言語安全データシートやメンテナンスマニュアルにNLGを使用し、小売業はコンバージョン率を高める動的な製品コンテンツに注力しています。
# 地域分析
* 北米: 2024年に38.51%のNLG市場シェアを占め、生成AIへの140億米ドルのベンチャー資金と連邦機関内の明確な調達経路に支えられています。クロスインダストリーのクラウドパートナーシップが展開を加速させていますが、少数の基盤モデルプロバイダーへの集中リスクは戦略的なサプライチェーンの懸念を引き起こしています。
* ヨーロッパ: 主権AIと説明可能性を優先し、国内ベンダーとオープンソースコンソーシアムを奨励しています。EU AI法は、グローバルな製品設計に影響を与える厳格な基準を設定しており、追跡可能な出力を提供できるサプライヤーに利益をもたらしています。
* アジア太平洋: 2030年までに20.09%の地域CAGRを記録し、中国の国家資金プログラムが国内モデル開発に数十億ドルを投入していることに支えられています。東南アジア全体でローカライズされた言語サポートが不可欠であり、クラウドハイパースケーラーと地域の通信事業者とのパートナーシップを促進しています。
* 南米、中東、アフリカ: 政府のデジタル化アジェンダと接続インフラの改善に支えられ、未発達ながらも有望な市場として残っています。
# 競合状況
NLG市場は中程度に断片化されており、単一のベンダーが15%を超えるシェアを支配しているわけではありません。テクノロジー大手はモデル性能とエコシステム幅で競争し、エンタープライズソフトウェアプロバイダーはドメインに特化したワークフローとコンプライアンスツールで差別化を図っています。2023年までに特許出願は14,000件を超え、知的財産権の競争が激化していることを示しています。IBM GraniteモデルとSalesforce Einsteinの最近の統合は、プラットフォームの収束を示しており、顧客にポイントソリューションではなく統合されたツールチェーンを提供しています。
新興のチャレンジャーは、テンプレートが豊富でノーコードのインターフェースを持つ中小企業セグメントをターゲットにしており、エッジネイティブのスタートアップはハードウェア制約のある環境向けにランタイムを最適化しています。戦略的パートナーシップは、データ共有、主権展開、共同市場投入プログラムに焦点を当てています。大規模な買収に対する継続的な規制の監視は、統合を遅らせ、NLG業界内のニッチな専門家や地域チャンピオンのためのイノベーションの道を維持する可能性があります。
# 主要プレイヤー
* Alphabet Inc. (Google)
* Microsoft Corporation
* International Business Machines Corporation (IBM)
* Amazon Web Services, Inc.
* Salesforce, Inc.
# 最近の業界動向
* 2025年7月: Zhipu AIは、モデルの商業化を加速しIPOに備えるため、上海の政府系投資家から1.4億米ドルを調達し、中国の主権AIへの野心を強化しました。
* 2025年3月: SalesforceはAgentforce 2dxを発表し、企業ワークフローにシームレスに組み込まれるプロアクティブなマルチモーダルエージェントを追加しました。これは、会話型コパイロットから自律型プロセスオーケストレーターへのシフトを示唆しています。
* 2025年1月: OpenAIはMicrosoft Azure上でChatGPT Govを導入し、米国政府機関がFedRAMP認証環境内で安全なNLGサービスを展開できるようにしました。
* 2024年10月: SAPはJouleコパイロットを共同エージェントとナレッジグラフバックボーンで強化し、規制の厳しいヨーロッパの顧客に対する価値提案を強化しました。
本レポートは、自然言語生成(NLG)市場に関する詳細な分析を提供しています。市場の定義、調査範囲、調査方法から始まり、市場の現状、成長要因、阻害要因、競争環境、将来の展望までを網羅しています。
市場は2030年までに28.3億米ドルに達すると予測されており、年平均成長率(CAGR)は15.86%と高い成長が見込まれています。
主な成長要因としては、デジタルファースト企業におけるハイパーパーソナライズされたコンテンツの大規模生成による投資収益率(ROI)の向上、Gen-AIコパイロットや自律エージェントに必要なリアルタイムのナラティブ生成が挙げられます。また、大規模言語モデル(LLM)の推論コストの急速な低下が中小企業(SME)の導入を拡大させています。規制分野では、説明可能なAIに対する規制圧力が高まっており、テンプレート駆動型NLGが有利に働いています。さらに、新興市場における多言語顧客体験(CX)自動化の需要や、IoTデバイスや自動車における軽量NLGモデルのエッジ展開も市場を牽引しています。
一方で、市場の阻害要因としては、高品質なドメイン特化型学習データの不足、AIが生成する誤情報や法的責任に関する懸念の高まり、レガシーなコンテンツ管理システムとの統合の複雑さ、そして独自のモデルエコシステムによるベンダーロックインが挙げられます。
コンポーネント別に見ると、展開において最も急速に成長しているのはプロフェッショナルサービスであり、統合、コンプライアンス、継続的な最適化に関する専門知識の需要が高まっているため、19.35%のCAGRで拡大しています。組織規模別では、中小企業(SME)によるNLGソリューションの導入が増加しており、これはトークンベースのAPI価格設定とローコードオーケストレーションツールにより、多額の初期費用が不要となり、コンテンツ作成を迅速に自動化できるためです。業界別では、NLGベンダーにとって最も高い成長潜在力を持つのはヘルスケアおよびライフサイエンス分野であり、臨床文書の自動化と厳格なコンプライアンス要件により、18.62%のCAGRを示しています。規制の影響としては、EU AI法などの規制フレームワークが説明可能性を重視しており、金融およびヘルスケア組織は、透明性の高い監査証跡を持つテンプレート駆動型またはハイブリッドNLGシステムへと移行しています。新たな展開トレンドとして、ハイブリッドクラウド・エッジモデルがNLGアーキテクチャを再構築しており、トレーニングをクラウドで実行しつつ、レイテンシーに敏感な推論をローカルデバイスで実行することで、帯域幅を削減し、データ主権要件を満たすものです。
市場は、コンポーネント(ソフトウェア、サービス)、展開モード(オンプレミス、クラウド)、組織規模(大企業、中小企業)、業界垂直(BFSI、ヘルスケア・ライフサイエンス、小売・eコマース、メディア・エンターテイメント、製造、その他)、および地域(北米、ヨーロッパ、アジア太平洋、南米、中東・アフリカ)にわたって詳細に分析されています。
競争環境では、Alphabet (Google)、Microsoft、Amazon Web Services、IBM、Salesforce、SAP、SAS Instituteといった大手テクノロジー企業に加え、ARRIA NLG、Automated Insights、AX Semantics、Yseop、OpenAI、Grammarly、Jasperなど、多数の専門NLGベンダーが名を連ねています。市場の集中度、戦略的動向、市場シェア分析、主要企業のプロファイルが提供されています。
レポートでは、市場の機会と将来の展望についても言及されており、未開拓の分野や満たされていないニーズの評価が行われています。

1. はじめに
- 1.1 調査の前提条件と市場の定義
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
-
4.2 市場の推進要因
- 4.2.1 大規模な超パーソナライズされたコンテンツが、デジタルファースト企業のROIを向上させる
- 4.2.2 Gen-AIコパイロットと自律エージェントに必要なリアルタイムのナラティブ生成
- 4.2.3 大規模言語モデル(LLM)の推論コストの急速な低下が中小企業の導入を拡大
- 4.2.4 説明可能なAIに対する規制圧力により、規制分野でテンプレート駆動型NLGが有利に
- 4.2.5 新興市場における多言語CX自動化の需要(Tier-2言語)
- 4.2.6 IoTデバイスおよび自動車における軽量NLGモデルのエッジ展開
-
4.3 市場の制約
- 4.3.1 高品質なドメイン固有のトレーニングデータの不足
- 4.3.2 AI生成の誤情報と法的責任に対する懸念の高まり
- 4.3.3 レガシーコンテンツ管理スタックとの統合の複雑さ
- 4.3.4 独自のモデルエコシステムによるベンダーロックイン
- 4.4 バリューチェーン分析
- 4.5 規制環境
- 4.6 技術的展望
-
4.7 ポーターの5つの力分析
- 4.7.1 新規参入者の脅威
- 4.7.2 供給者の交渉力
- 4.7.3 買い手の交渉力
- 4.7.4 代替品の脅威
- 4.7.5 競争上の対抗関係
5. 市場規模と成長予測(数値)
-
5.1 コンポーネント別
- 5.1.1 ソフトウェア
- 5.1.2 サービス
-
5.2 展開モード別
- 5.2.1 オンプレミス
- 5.2.2 クラウド
-
5.3 組織規模別
- 5.3.1 大企業
- 5.3.2 中小企業
-
5.4 業界別
- 5.4.1 BFSI
- 5.4.2 ヘルスケアおよびライフサイエンス
- 5.4.3 小売およびEコマース
- 5.4.4 メディアおよびエンターテイメント
- 5.4.5 製造業
- 5.4.6 その他の業界
-
5.5 地域別
- 5.5.1 北米
- 5.5.1.1 米国
- 5.5.1.2 カナダ
- 5.5.1.3 メキシコ
- 5.5.2 ヨーロッパ
- 5.5.2.1 イギリス
- 5.5.2.2 ドイツ
- 5.5.2.3 フランス
- 5.5.2.4 イタリア
- 5.5.2.5 スペイン
- 5.5.2.6 ロシア
- 5.5.2.7 その他のヨーロッパ
- 5.5.3 アジア太平洋
- 5.5.3.1 中国
- 5.5.3.2 日本
- 5.5.3.3 韓国
- 5.5.3.4 インド
- 5.5.3.5 オーストラリア
- 5.5.3.6 シンガポール
- 5.5.3.7 その他のアジア太平洋
- 5.5.4 南米
- 5.5.4.1 ブラジル
- 5.5.4.2 アルゼンチン
- 5.5.4.3 チリ
- 5.5.4.4 その他の南米
- 5.5.5 中東およびアフリカ
- 5.5.5.1 中東
- 5.5.5.1.1 イスラエル
- 5.5.5.1.2 トルコ
- 5.5.5.1.3 サウジアラビア
- 5.5.5.1.4 アラブ首長国連邦
- 5.5.5.1.5 カタール
- 5.5.5.1.6 その他の中東
- 5.5.5.2 アフリカ
- 5.5.5.2.1 南アフリカ
- 5.5.5.2.2 ナイジェリア
- 5.5.5.2.3 ケニア
- 5.5.5.2.4 その他のアフリカ
6. 競合状況
- 6.1 市場集中度
- 6.2 戦略的動向
- 6.3 市場シェア分析
-
6.4 企業プロファイル(グローバルレベルの概要、市場レベルの概要、コアセグメント、利用可能な財務情報、戦略情報、主要企業の市場ランク/シェア、製品とサービス、および最近の動向を含む)
- 6.4.1 Alphabet Inc. (Google)
- 6.4.2 Microsoft Corporation
- 6.4.3 Amazon Web Services, Inc.
- 6.4.4 International Business Machines Corporation (IBM)
- 6.4.5 Salesforce, Inc.
- 6.4.6 SAP SE
- 6.4.7 SAS Institute Inc.
- 6.4.8 ARRIA NLG plc
- 6.4.9 Automated Insights, Inc.
- 6.4.10 AX Semantics GmbH
- 6.4.11 Yseop SA
- 6.4.12 Narrativa AI, SL
- 6.4.13 Persado, Inc.
- 6.4.14 Phrasee Ltd.
- 6.4.15 Retresco GmbH
- 6.4.16 Phrasia Ltd.
- 6.4.17 OpenAI, L.L.C.
- 6.4.18 Cohere Technologies Inc.
- 6.4.19 Grammarly, Inc.
- 6.4.20 Writer, Inc.
- 6.4.21 Jasper, Inc.
- 6.4.22 Anyword Ltd.
- 6.4.23 QuillBot LLC
- 6.4.24 StoryStream Ltd.
7. 市場機会と将来展望
*** 本調査レポートに関するお問い合わせ ***

自然言語生成(Natural Language Generation、NLG)は、コンピュータが人間が理解できる自然言語のテキストを自動的に生成する技術を指します。これは、自然言語処理(Natural Language Processing、NLP)の一分野であり、コンピュータが人間の言語を理解する自然言語理解(Natural Language Understanding、NLU)と対をなす重要な技術です。構造化されたデータや非構造化データから、意味のある文章、レポート、記事などを生成することで、人間が情報を効率的に理解し、コミュニケーションを円滑にすることを目的としています。
NLGの技術は、そのアプローチによっていくつかの種類に分類されます。最も基本的なものは、テンプレートベースの生成です。これは、あらかじめ定義された文章のテンプレートに、特定のデータを埋め込むことでテキストを生成する方法で、シンプルで実装が容易ですが、生成される文章の多様性や柔軟性に限界があります。次に、ルールベースの生成があります。これは、文法規則、語彙選択ルール、文脈に応じた表現ルールなどを事前に設定し、それに基づいてテキストを生成する方法です。テンプレートベースよりも複雑な文章構造に対応できますが、ルール設計に多大な労力が必要であり、網羅性や柔軟性の確保が課題となります。さらに、統計的NLGは、大規模なテキストデータから統計モデルを学習し、単語やフレーズの出現確率に基づいてテキストを生成します。機械翻訳などで利用されてきましたが、文脈の一貫性や自然さの点で限界がありました。そして、近年最も注目されているのが、ディープラーニング、特にTransformerモデルを基盤とするニューラルNLGです。これは、膨大なテキストデータから言語のパターンや文脈を学習し、人間が書いたような自然で流暢な文章を生成する能力に優れています。GPTシリーズに代表される大規模言語モデル(LLM)の登場により、その性能は飛躍的に向上しました。
NLGの用途は多岐にわたります。最も一般的なものとしては、コンテンツ生成が挙げられます。ニュース記事、財務レポート、製品説明、マーケティングコピー、ブログ記事、SNS投稿など、様々な種類のテキストコンテンツを自動で作成できます。これにより、コンテンツ作成の効率化とコスト削減が実現されます。また、大量のデータやドキュメントから重要な情報を抽出し、簡潔な要約を生成するデータ要約も重要な用途です。カスタマーサービスにおいては、チャットボットや仮想アシスタントがユーザーの質問に対して適切な応答を生成し、会話を継続するためにNLGが不可欠です。機械翻訳もNLGの一種であり、ある言語から別の言語へテキストを変換します。さらに、個々のユーザーの行動や好みに合わせてパーソナライズされたメール、通知、レコメンデーションメッセージを生成することで、顧客エンゲージメントの向上に貢献します。視覚障害者向けの画像や動画の音声記述生成、さらには自然言語の指示からプログラミングコードを生成する用途も登場しており、その応用範囲は拡大の一途を辿っています。
NLGを支える関連技術としては、まずその上位概念である自然言語処理(NLP)全体が挙げられます。特に、テキストの構造を解析する構文解析、意味を理解する意味解析、文脈を把握する談話解析といったNLUの技術は、高品質なテキスト生成の前提となります。また、機械学習、特にディープラーニングはNLGの進化を牽引する中核技術です。リカレントニューラルネットワーク(RNN)、長・短期記憶(LSTM)、そしてTransformerといったモデルが、より複雑な言語パターンを学習し、人間らしい文章を生成する能力を向上させました。中でも、GPT-3/4、BERT、PaLMなどの大規模言語モデル(LLM)は、膨大なデータで事前学習されており、汎用的なNLGタスクにおいて驚異的な性能を発揮します。生成されるテキストの事実的正確性を担保するためには、知識グラフやデータベースから情報を取得する技術も重要です。さらに、生成の元となるデータを効率的に収集・整理するためのデータマイニングや情報抽出技術も密接に関連しています。
NLGの市場背景は、デジタルコンテンツの爆発的な増加と、それに伴うコンテンツ作成の需要増大によって特徴づけられます。企業は顧客とのパーソナライズされたコミュニケーションを求めるようになり、NLGはその実現のための強力なツールとなっています。また、大規模言語モデルの登場により、生成されるテキストの品質が飛躍的に向上し、実用レベルでの導入が加速しています。これにより、スタートアップから大手IT企業まで、NLG技術の研究開発と製品化への投資が活発化しています。一方で、市場には課題も存在します。生成されたテキストの倫理的な問題(フェイクニュース、著作権侵害、バイアス)、事実誤認(ハルシネーション)、そしてモデルの運用コストなどが挙げられます。これらの課題に対し、技術的な改善や倫理的ガイドラインの策定が進められています。
将来の展望として、NLGはさらなる高品質化と自然さを追求し、人間が書いたものと区別がつかないレベルに到達すると予測されています。多言語対応や、テキストだけでなく画像、音声、動画といった複数のモダリティ(多モーダル)を組み合わせた生成も進化するでしょう。医療、法律、金融といった特定の専門分野に特化したNLGモデルの開発も進み、より正確で信頼性の高い情報生成が可能になります。また、AIが下書きを作成し、人間が最終的な調整や創造的な要素を加えるといった、人間とAIが協調するハイブリッドなワークフローが一般的になるでしょう。これにより、人間の創造性が拡張され、より効率的で質の高いコンテンツ制作が実現されます。倫理的な側面では、責任あるAI開発と利用のための国際的なガイドラインや規制の確立が不可欠となり、透明性、公平性、プライバシー保護が重視されるようになります。最終的には、詩、物語、脚本といった、より高度な創造性を要するコンテンツ生成においても、NLGが重要な役割を果たす可能性を秘めています。