データOps市場規模・シェア分析 – 成長動向と予測 (2025年~2030年)
データオプス市場は、コンポーネント(プラットフォーム、サービス)、展開形態(クラウド、オンプレミス)、企業規模(大企業、中小企業)、エンドユーザー産業(BFSI、IT・通信など)、アプリケーション(データ統合・ETLなど)、および地域別に分類されます。市場予測は、金額(米ドル)で提供されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
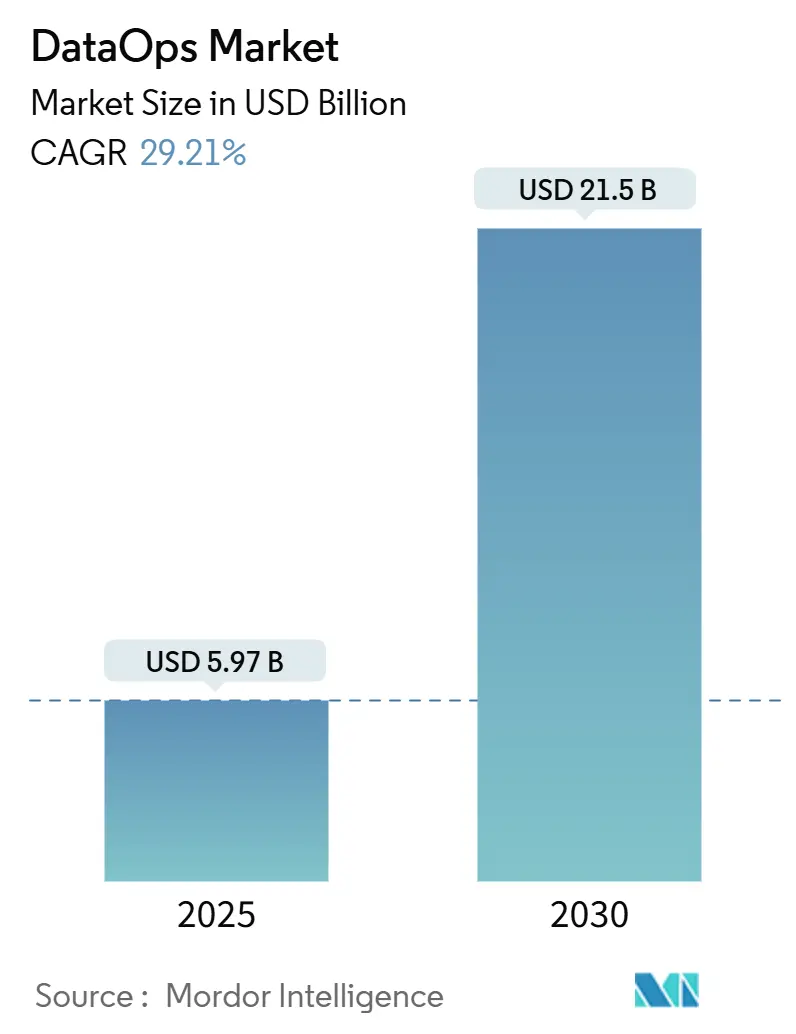
DataOps市場は、2019年から2030年を調査期間とし、2025年には59.7億米ドル、2030年には215億米ドルに達すると予測されており、2025年から2030年にかけて年平均成長率(CAGR)29.91%という高い成長が見込まれています。地域別では北米が最大の市場であり、アジア太平洋地域が最も急速に成長する市場とされています。市場の集中度は中程度です。主要なプレイヤーとしては、Amazon Web Services, Inc.、International Business Machines Corporation、Oracle Corporation、Microsoft Corporation、Informatica LLCなどが挙げられます。
市場概要と主要な動向
DataOps市場は、クラウドネイティブなデータプラットフォーム、リアルタイム分析の要件、および人工知能(AI)への取り組みが融合し、ニッチなエンジニアリングプラクティスから企業の核となる能力へと進化しています。主権データ規制の強化やイベントストリーム量の増加に伴い、自動化されたパイプラインオーケストレーション、データオブザーバビリティ、リネージトラッキングが必須機能となっています。ベンダー間の競争は、低遅延、低所有コスト、迅速な展開サイクルを約束する統合型レイクハウスやメッシュ対応アーキテクチャへと移行しています。同時に、マネージドサービスモデルやローコードツールは、特に中堅企業や規制の厳しい業界において、深いエンジニアリングリソースを持たない組織の導入を促進しています。
このレポートは、DataOps市場に関する包括的な分析を提供しています。DataOpsは、技術的実践、ワークフロー、文化的規範、およびアーキテクチャパターンを組み合わせたものであり、顧客に新たな洞察をより速く提供し、迅速なイノベーションと実験を可能にするものです。本レポートでは、市場の定義、調査範囲、調査方法、エグゼクティブサマリー、市場の状況、市場規模と成長予測、競争環境、市場機会と将来の展望について詳細に記述されています。
市場の状況に関する章では、まず市場の概要が示され、その後に市場を牽引する主要な要因が挙げられています。これには、データ量の爆発的な増加、リアルタイム分析への需要の高まり、クラウドネイティブデータスタックの急速な採用、信頼性の高いデータパイプラインを必要とするAI/MLイニシアチブの増加、データメッシュアーキテクチャへの移行、そして主権データ法による自動化されたデータリネージの推進などが含まれます。
一方で、市場の成長を阻害する要因も分析されています。具体的には、高い導入およびツールコスト、熟練したDataOpsエンジニアの不足、ツールチェーンの断片化とそれに伴うセキュリティギャップ、そして規制の厳しい分野における文化的な抵抗などが挙げられます。さらに、バリューチェーン分析、規制環境、技術的展望、ポーターのファイブフォース分析、マクロ経済的影響評価、投資分析といった多角的な視点から市場が評価されています。
市場規模と成長予測の章では、市場が様々なセグメントにわたって詳細に分析されています。コンポーネント別ではプラットフォームとサービス、展開モデル別ではクラウドとオンプレミス、企業規模別では大企業と中小企業、最終用途産業別ではBFSI、IT・通信、製造、小売・Eコマース、ヘルスケア、政府・公共部門、エネルギー・公益事業、アプリケーション別ではデータ統合とETL、パイプラインオーケストレーション、データ品質と可観測性、データガバナンス/コンプライアンス、リアルタイム分析に分類されています。地理的分析では、北米、南米、ヨーロッパ、アジア太平洋、中東・アフリカの各地域が、さらに詳細な国別セグメントに分けられて評価されています。
特に、本レポートの主要な質問への回答として、DataOps市場は2025年に59.7億米ドルと評価され、2030年までに215.0億米ドルに達すると予測されています。地域別では、アジア太平洋地域がデジタルトランスフォーメーションプログラムと政府のクラウド義務化により、2030年まで年平均成長率34.90%で最も速い成長を示すと予想されています。コンポーネント別では、人材不足を補うためのマネージド実装への需要が高まることから、サービスセグメントが年平均成長率30.40%で最も急速に拡大すると見込まれています。最終用途産業では、リアルタイム患者分析と規制遵守の自動化が推進力となり、ヘルスケア分野が年平均成長率35.50%で最速の成長を遂げると予測されています。展開モデルに関しては、クラウドが2024年の収益の63.13%を占め、スケーリング、可観測性、セキュリティを簡素化することで、多くの企業がハイブリッドまたはマルチクラウドのDataOpsアーキテクチャを採用するきっかけとなっています。
競争環境の章では、市場集中度、戦略的動向、市場シェア分析が行われ、Amazon Web Services, Inc.、International Business Machines Corporation、Microsoft Corporation、Oracle Corporation、Google LLC、Databricks, Inc.、Cloudera, Inc.、Informatica LLC、Talend, Inc.、Collibra NV、Teradata Corporation、Snowflake Inc.、Wipro Limited、SAP SE、DataKitchen, Inc.、Acceldata, Inc.、Monte Carlo Data, Inc.、StreamSets, Inc.、Unravel Data Systems, Inc.、Grafana Labs, Inc.といった主要企業のプロファイルが詳細に記述されています。
最後に、市場機会と将来の展望の章では、未開拓の分野や満たされていないニーズの評価を通じて、今後の成長機会が特定されています。このレポートは、DataOps市場の現状と将来の動向を理解するための貴重な情報源となるでしょう。

1. はじめに
- 1.1 調査の前提条件と市場の定義
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
-
4.2 市場の推進要因
- 4.2.1 データ量の爆発的増加
- 4.2.2 リアルタイム分析の需要
- 4.2.3 クラウドネイティブデータスタックの急速な採用
- 4.2.4 信頼性の高いパイプラインを必要とするAI / MLイニシアチブ
- 4.2.5 データメッシュアーキテクチャへの移行
- 4.2.6 自動化されたリネージを推進する主権データ法
-
4.3 市場の阻害要因
- 4.3.1 高い実装およびツール費用
- 4.3.2 熟練したDataOpsエンジニアの不足
- 4.3.3 ツールチェーンの断片化とセキュリティギャップ
- 4.3.4 規制分野における文化的な抵抗
- 4.4 バリューチェーン分析
- 4.5 規制環境
- 4.6 技術的展望
-
4.7 ポーターの5つの力分析
- 4.7.1 供給者の交渉力
- 4.7.2 買い手の交渉力
- 4.7.3 新規参入の脅威
- 4.7.4 代替品の脅威
- 4.7.5 競争の激しさ
- 4.8 マクロ経済影響評価
- 4.9 投資分析
5. 市場規模と成長予測 (価値、10億米ドル)
-
5.1 コンポーネント別
- 5.1.1 プラットフォーム
- 5.1.2 サービス
-
5.2 展開別
- 5.2.1 クラウド
- 5.2.2 オンプレミス
-
5.3 企業規模別
- 5.3.1 大企業
- 5.3.2 中小企業
-
5.4 エンドユーザー産業別
- 5.4.1 BFSI
- 5.4.2 IT・通信
- 5.4.3 製造業
- 5.4.4 小売・Eコマース
- 5.4.5 ヘルスケア
- 5.4.6 政府・公共部門
- 5.4.7 エネルギー・公益事業
-
5.5 アプリケーション別
- 5.5.1 データ統合・ETL
- 5.5.2 パイプラインオーケストレーション
- 5.5.3 データ品質・可観測性
- 5.5.4 データガバナンス・コンプライアンス
- 5.5.5 リアルタイム分析
-
5.6 地域別
- 5.6.1 北米
- 5.6.1.1 米国
- 5.6.1.2 カナダ
- 5.6.1.3 メキシコ
- 5.6.2 南米
- 5.6.2.1 ブラジル
- 5.6.2.2 アルゼンチン
- 5.6.2.3 その他の南米諸国
- 5.6.3 欧州
- 5.6.3.1 英国
- 5.6.3.2 ドイツ
- 5.6.3.3 フランス
- 5.6.3.4 イタリア
- 5.6.3.5 スペイン
- 5.6.3.6 ロシア
- 5.6.3.7 その他の欧州諸国
- 5.6.4 アジア太平洋
- 5.6.4.1 中国
- 5.6.4.2 日本
- 5.6.4.3 インド
- 5.6.4.4 韓国
- 5.6.4.5 オーストラリア・ニュージーランド
- 5.6.4.6 東南アジア
- 5.6.4.7 その他のアジア太平洋諸国
- 5.6.5 中東・アフリカ
- 5.6.5.1 中東
- 5.6.5.1.1 サウジアラビア
- 5.6.5.1.2 アラブ首長国連邦
- 5.6.5.1.3 トルコ
- 5.6.5.1.4 その他の中東諸国
- 5.6.5.2 アフリカ
- 5.6.5.2.1 南アフリカ
- 5.6.5.2.2 ナイジェリア
- 5.6.5.2.3 エジプト
- 5.6.5.2.4 その他のアフリカ諸国
6. 競合情勢
- 6.1 市場集中度
- 6.2 戦略的動き
- 6.3 市場シェア分析
-
6.4 企業プロファイル(グローバルレベルの概要、市場レベルの概要、主要セグメント、利用可能な財務情報、戦略情報、市場ランク/シェア、製品とサービス、最近の動向を含む)
- 6.4.1 Amazon Web Services, Inc.
- 6.4.2 International Business Machines Corporation
- 6.4.3 Microsoft Corporation
- 6.4.4 Oracle Corporation
- 6.4.5 Google LLC
- 6.4.6 Databricks, Inc.
- 6.4.7 Cloudera, Inc.
- 6.4.8 Informatica LLC
- 6.4.9 Talend, Inc.
- 6.4.10 Collibra NV
- 6.4.11 Teradata Corporation
- 6.4.12 Snowflake Inc.
- 6.4.13 Wipro Limited
- 6.4.14 SAP SE
- 6.4.15 DataKitchen, Inc.
- 6.4.16 Acceldata, Inc.
- 6.4.17 Monte Carlo Data, Inc.
- 6.4.18 StreamSets, Inc.
- 6.4.19 Unravel Data Systems, Inc.
- 6.4.20 Grafana Labs, Inc.
7. 市場機会と将来展望
*** 本調査レポートに関するお問い合わせ ***

データOps(データオプス)は、データ分析のライフサイクル全体を効率化し、高品質なデータを迅速かつ継続的に提供するための文化、プラクティス、およびテクノロジーの集合体です。これは、ソフトウェア開発におけるDevOpsの原則をデータと分析の領域に適用したものであり、アジャイル開発、継続的インテグレーション(CI)、継続的デリバリー(CD)といった概念を取り入れています。データOpsの究極の目的は、データエンジニア、データサイエンティスト、ビジネスアナリストといったデータに関わる全てのステークホルダー間のコラボレーションを促進し、データドリブンな意思決定を加速させることにあります。データ収集から変換、分析、モデルのデプロイ、そして監視に至るまでの一連のプロセスを自動化し、エラーを最小限に抑えながら、ビジネス価値を最大化することを目指します。
データOpsは特定のツールや製品を指すものではなく、むしろデータ管理と分析に対するアプローチや哲学を意味します。その主要な構成要素としては、まず「アジャイル開発」が挙げられます。これは、短いサイクルで反復的にデータパイプラインや分析モデルを開発し、迅速なフィードバックを取り入れることで、変化するビジネス要件に柔軟に対応することを可能にします。次に、「継続的インテグレーション(CI)」は、データパイプラインのコードや分析モデルの変更を頻繁に統合し、自動テストを実行することで、早期に問題を検出し、品質を保証します。さらに、「継続的デリバリー/デプロイメント(CD)」は、テスト済みのデータ製品や分析モデルを本番環境に自動的にリリースするプロセスを指し、市場投入までの時間を大幅に短縮します。また、「監視とアラート」は、データ品質、パイプラインのパフォーマンス、モデルの精度などをリアルタイムで監視し、異常を検知した際に迅速に対応するための重要な要素です。その他、「バージョン管理」によるデータ、コード、モデル、インフラストラクチャの変更履歴の管理と再現性の確保、そして「コラボレーション」によるチーム間の円滑なコミュニケーションと連携強化も、データOpsの成功には不可欠です。最後に、「データガバナンスとセキュリティ」は、データ品質、プライバシー、セキュリティに関するポリシーを適用し、コンプライアンスを確保する上で重要な役割を果たします。
データOpsを導入することには、多くの利点があります。第一に、「データ分析の迅速化」が挙げられます。データパイプラインの構築とデプロイを自動化することで、分析結果をより早くビジネスに提供し、意思決定のスピードを向上させることができます。第二に、「データ品質の向上」です。自動テストと継続的な監視により、データの正確性、一貫性、完全性を維持し、信頼性の高い分析基盤を構築します。第三に、「エラーの早期発見と修正」です。パイプラインの問題やモデルの劣化をリアルタイムで検知し、迅速に対応することで、ビジネスへの影響を最小限に抑えます。第四に、「コスト削減」です。手作業によるエラーを減らし、運用効率を高めることで、リソースの最適化と運用コストの削減に貢献します。第五に、「再現性と信頼性の向上」です。バージョン管理と自動化により、分析結果の再現性を保証し、データ製品に対する信頼を高めます。第六に、「チーム間の連携強化」です。データエンジニア、データサイエンティスト、ビジネスユーザー間のコミュニケーションを円滑にし、共通の目標に向かって協力する文化を醸成します。これらの利点を通じて、企業はデータからより大きなビジネス価値を引き出し、競争優位性を確立することが可能になります。
データOpsを実装するためには、様々な技術が組み合わされます。データパイプラインの構築とオーケストレーションには、Apache Airflow、Prefect、Dagster、Azure Data Factory、Google Cloud Dataflow、AWS Glueなどのツールが利用されます。データの保存と分析基盤としては、Snowflake、Databricks、Google BigQuery、Amazon Redshift、Azure Synapse Analyticsといったデータウェアハウスやデータレイクが活用されます。コード、設定、モデルのバージョン管理には、Git(GitHub、GitLab、Bitbucket)が広く用いられます。自動テストとデプロイメントを管理するCI/CDツールとしては、Jenkins、CircleCI、GitHub Actions、GitLab CI/CD、Azure DevOpsなどが一般的です。データ品質のテスト、プロファイリング、監視には、Great Expectations、dbt(data build tool)、Monte Carlo、Datafoldといった専用ツールが利用されます。また、データパイプラインや分析アプリケーションのポータビリティとスケーラビリティを向上させるために、DockerやKubernetesといったコンテナ技術も重要な役割を果たします。さらに、機械学習モデルのライフサイクル管理(MLOps)と統合される形で、MLflow、Kubeflow、SageMakerなどのMLOpsプラットフォームも関連技術として挙げられます。
データOpsの登場は、現代のビジネス環境におけるいくつかの重要なトレンドによって推進されています。まず、「データ量の爆発的増加」です。ビッグデータの時代において、企業は膨大なデータを効率的に処理し、そこから価値を引き出す必要に迫られています。次に、「データドリブン経営の重要性」です。競争力を維持・向上させるため、迅速かつ正確なデータに基づいた意思決定が不可欠となっています。また、「データチームの複雑化」も背景にあります。データエンジニア、データサイエンティスト、アナリストなど、専門性の異なるチーム間の連携が課題となっており、データOpsはこれらのサイロを解消する手段として期待されています。さらに、ソフトウェア開発におけるDevOpsの成功が、データと分析の領域にも同様のプラクティスを求める動きを生み出しました。「クラウド技術の普及」も大きな要因です。クラウドベースのデータプラットフォームやサービスが、データパイプラインの構築と運用を容易にし、データOpsの実現を後押ししています。最後に、「AI/MLの進化」です。機械学習モデルの運用(MLOps)の複雑さが増す中で、データOpsの原則がモデルのライフサイクル管理にも適用され、その重要性が高まっています。
将来的に、データOpsはデータとAIの活用を加速させる上で不可欠なアプローチとして、さらなる進化を遂げると予想されます。まず、「自動化のさらなる進化」が挙げられます。AIを活用したデータ品質チェック、異常検知、パイプライン最適化など、より高度な自動化が進み、人間の介入を最小限に抑える方向へと向かうでしょう。次に、「MLOpsとの融合」が加速します。データOpsとMLOpsは密接に連携し、データからモデルのデプロイ、監視までを一貫して管理する統合プラットフォームが主流になることで、AIモデルの信頼性と運用効率が向上します。また、「データガバナンスの強化」も重要なテーマです。データプライバシー規制(GDPR、CCPAなど)の厳格化に伴い、データOpsにおけるデータガバナンスとセキュリティの側面がさらに重要になり、コンプライアンスを自動的に確保する仕組みが求められるでしょう。さらに、「セルフサービス化の推進」も進むと見られます。ビジネスユーザーがより簡単にデータにアクセスし、分析を行えるよう、データOpsの原則に基づいたセルフサービス型データプラットフォームが普及し、データ活用の民主化が進むでしょう。分散型データアーキテクチャである「データメッシュとの連携」も注目されます。データメッシュの概念とデータOpsが組み合わされることで、大規模な組織におけるデータ管理と活用が効率化される可能性があります。最後に、「人材育成の重要性」は今後も高まります。データOpsの文化とプラクティスを組織に浸透させるためには、技術的なスキルだけでなく、コラボレーションを重視し、継続的な改善に取り組む人材の育成が不可欠となります。データOpsは、企業がデータから最大限の価値を引き出し、持続的な成長を実現するための基盤として、その重要性を増していくことでしょう。