学術研究・出版向けAIデータセットおよびライセンス市場規模と展望、2025-2033年

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
**学術研究・出版向けAIデータセットおよびライセンス市場の詳細分析**
**市場概要**
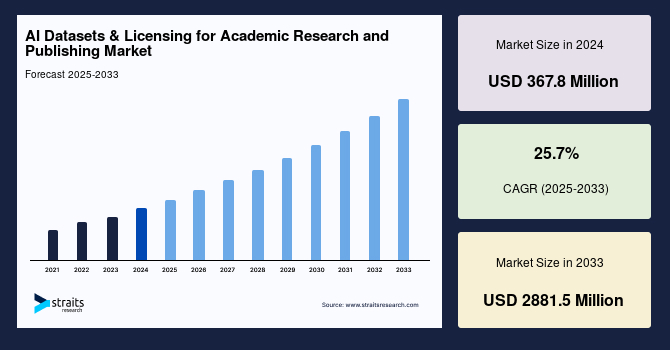
世界の学術研究・出版向けAIデータセットおよびライセンス市場は、AIモデルのトレーニング、検証、テストに不可欠な構造化および非構造化データの需要増加と、それらのデータの利用を管理するライセンス契約の必要性により、急速な成長を遂げています。2024年には3億6,780万米ドルの市場規模であった本市場は、2025年には4億6,232万米ドルに達すると推定されており、予測期間である2025年から2033年にかけて年平均成長率(CAGR)25.7%で成長し、2033年までに28億8,150万米ドルに達すると予測されています。
AIデータセットは、自然言語処理、コンピュータービジョン、機械学習など、様々なドメインにおけるAIモデルの機能開発と最適化に用いられる、多種多様なデータを指します。これらのデータセットは、モデルが現実世界の複雑なパターンを学習し、高精度な予測や分類を行うための基盤となります。一方、学術研究および出版におけるライセンスは、これらのデータセットの利用を法的に規定するものであり、知的財産権の保護、倫理的考慮事項の遵守、およびデータプライバシー規制への準拠を保証します。オープンアクセスデータセットは、クリエイティブ・コモンズ(CC)やオープンデータ・コモンズ(ODC)のような比較的寛容なライセンスが適用されることが多いですが、プロプライエタリなデータセットは、特定の利用規約や契約を必要とします。適切なライセンス供与は、研究者が合法的にデータを利用・共有できるだけでなく、データ提供者の権利を尊重し、AI開発における透明性を維持するために不可欠です。
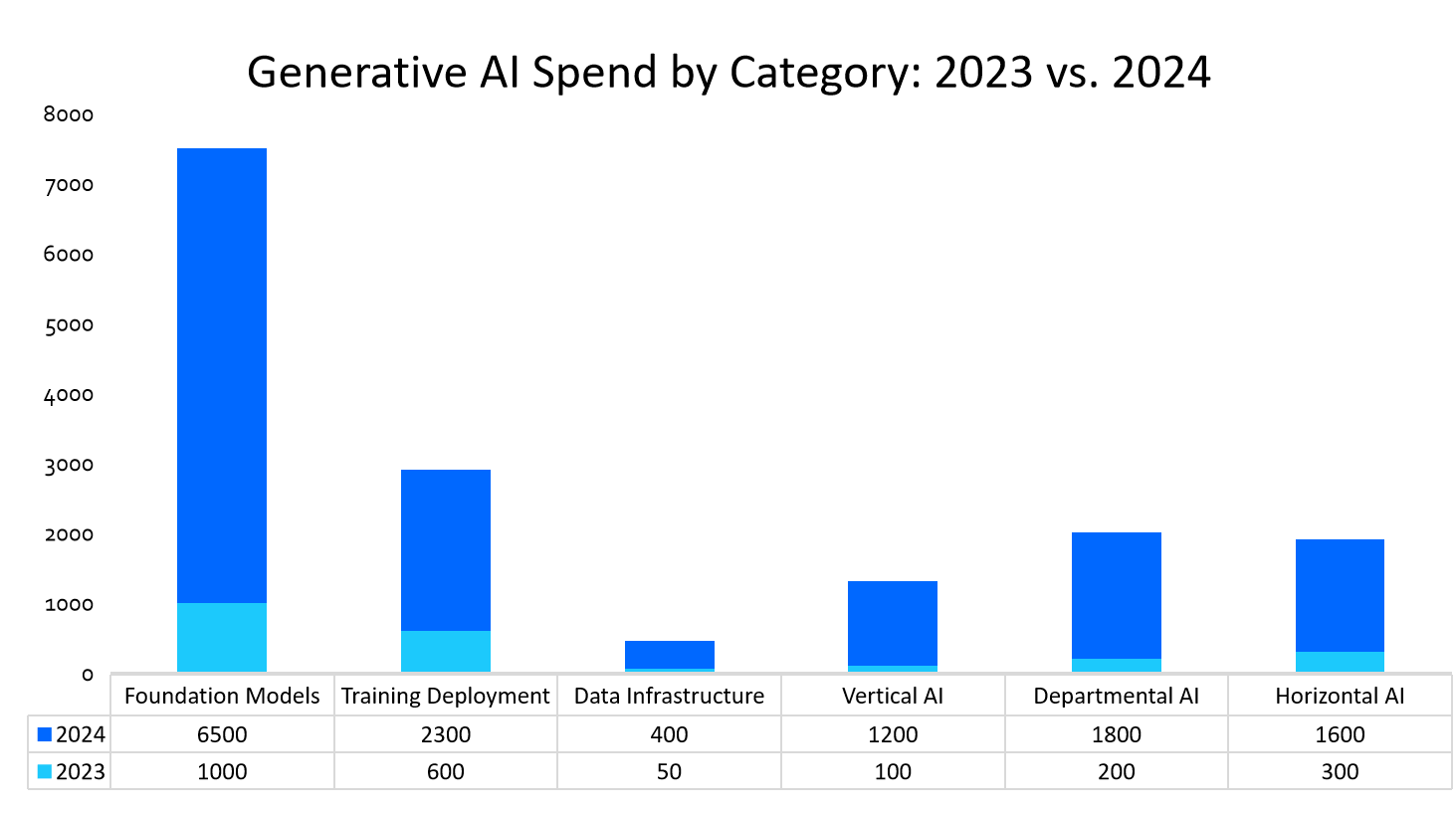
この市場の拡大は、特に学術研究分野において、AIモデルのトレーニングに必要な包括的なデータセットに対する需要が高まっていることに直接起因しています。大学、テクノロジー企業、研究機関間の協力関係は、データセットへのアクセスとライセンスフレームワークを改善し、研究者が多様なデータソースに触れる機会を増やしています。AIの予測分析やブロックチェーン技術の革新は、データライセンスのセキュリティと信頼性を向上させ、市場の成長をさらに加速させています。また、生成AIへの支出が2023年から2024年にかけて大幅に増加していることも、市場成長の強力な推進力となっています。この支出増は主に基盤モデルとトレーニング展開に向けられており、学術機関がモデルの精度と学術アプリケーションの革新を達成するために、堅牢なデータインフラストラクチャと垂直型AIソリューションを求めていることを示しています。
**市場の成長要因**
学術研究・出版向けAIデータセットおよびライセンス市場の成長は、複数の強力な要因によって推進されています。
1. **高品質なAIデータセットの需要増大**: AIモデルの精度と信頼性を高めるためには、多様で包括的、かつ高品質なデータセットが不可欠です。学術機関や研究者は、AIアプリケーションの性能向上を目指し、テキスト、画像、音声、動画など、様々な形式のデータを含む大規模なデータセットを求めています。特に、新しいAI技術、例えば生成AIの発展には、膨大で高品質なトレーニングデータが必須であり、これがデータセット市場を強く牽引しています。学術研究におけるAIの利用拡大は、予測分析、自然言語処理、画像認識などの高度なAIソリューションの需要を創出し、これらのソリューションの開発には質の高いデータセットが不可欠です。
2. **学術機関と産業界の連携強化**: 大学、テクノロジー企業、その他の研究機関間の協力関係が活発化しています。これらのパートナーシップは、学術界がこれまでアクセスできなかったプロプライエタリなデータセットを利用できるようにするだけでなく、産業界が学術的な洞察や研究成果から恩恵を受けることを可能にします。このような協力は、最先端のAI技術の開発を促進し、研究者に研究結果を検証するための実世界アプリケーションを提供します。結果として、データセットへのアクセスが改善され、ライセンスフレームワークが強化されることで、市場全体の成長が加速しています。
3. **AI技術革新と新たな利用事例の登場**: AIベースの予測分析やブロックチェーンを活用した透明性の高いソリューションなどの革新は、データライセンスのセキュリティと信頼性を劇的に向上させています。ブロックチェーン技術は、データセットの利用履歴を不変の形で記録し、データの改ざん防止と透明性の確保に貢献します。また、AIの進化は、学術分野における新たなアプリケーション、例えば自動コンテンツ要約、セマンティック検索、インテリジェントな個別指導システムなどを生み出し、これらのシステムを開発するためには、膨大で専門的なデータセットが必要となります。
4. **政府の政策と法整備の進展**: 世界各国の政府は、AI研究開発を支援するための政策や法的枠組みの更新に積極的に取り組んでいます。これにより、AI研究への投資が促進され、データ共有やライセンス供与に関する明確なガイドラインが提供されることで、市場の健全な成長が支援されています。政府によるAI戦略の推進は、研究機関や企業がAI関連技術に投資しやすい環境を醸成し、結果として学術研究・出版向けAIデータセットおよびライセンス市場の拡大に寄与しています。
5. **パブリックドメインデータセットの増加**: AI研究の民主化を目的として、パブリックドメインのデータセットの公開が大幅に増加しています。例えば、ハーバード大学は、マイクロソフトとOpenAIの資金提供を受けて、Googleブックスプロジェクトから約100万冊に及ぶパブリックドメインの書籍を含む包括的なデータセットを公開しました。この取り組みは、シェイクスピアやディケンズの作品からチェコ語の数学教科書、ウェールズ語の辞書に至るまで、多様なテキストへのアクセスを研究者に提供し、AIモデルのトレーニングに利用可能なデータの量を飛躍的に増やしています。これにより、特にリソースが限られている研究者も、高品質なデータにアクセスしやすくなっています。
6. **業界標準の確立への動き**: データセットのライセンス供与に関する業界標準の確立は、透明性と信頼性を促進し、より多くの機関がデータ共有とライセンス供与に参加することを奨励しています。2024年にDPAがAIデータライセンスに関する包括的なポジションペーパーを発表したことは、この分野における明確なガイドラインを確立しようとする努力の一例であり、市場の健全な発展に寄与しています。明確な標準は、ライセンスの複雑さを軽減し、データエコシステム全体での協力とイノベーションを促進します。
**市場の阻害要因**
学術研究・出版向けAIデータセットおよびライセンス市場は大きな成長を遂げていますが、いくつかの重要な阻害要因に直面しています。
1. **データ利用における倫理的懸念と著作権問題**: AIトレーニングにおけるデータの倫理的な利用は、これまで以上に厳しく精査されています。野生動物写真家のティム・フラック氏の画像が、彼の同意なしにAI研究者が使用するデータセットに含まれ、商業AI企業がロイヤリティを支払うことなく彼の作品を複製できるようになった事例は、著作権で保護されたコンテンツの無許可利用に関する深刻な懸念を浮上させました。このような状況は、AIモデルが学習するデータの出所と利用方法に対する監視を強化させ、研究者や企業がデータセットを利用する際に、著作権侵害のリスクや倫理的な配慮をより厳格に行う必要性を示しています。これにより、データセットの自由な利用や配布が妨げられる可能性があります。
2. **データプライバシー規制への対応の複雑さ**: 学術研究におけるAIの統合は、しばしば機密情報を含む膨大なデータセットへのアクセスを必要とします。一般データ保護規則(GDPR)のような厳格なデータ保護規制への準拠は、研究者にとって大きな課題です。特に、個人情報を含むデータセットを扱う場合、複雑な同意取得プロセスをナビゲートし、堅牢な匿名化技術を導入して倫理基準を維持する必要があり、これがデータ収集と利用を複雑化させています。機密性の高いデータを取り扱う研究分野、例えば医療や社会科学においては、データの匿名化と擬名化が不十分な場合、法的な問題や倫理的な批判に直面するリスクが高まります。
3. **進化する倫理ガイドラインへの適合とデータ取得の複雑化**: 大学や学術機関は、AI研究が常に進化する倫理ガイドラインに合致していることを確認しなければなりません。これは、データ取得と利用のプロセスをさらに複雑にします。研究者は、データの収集、保存、処理、共有の各段階において、潜在的な偏見、公平性、説明責任などの倫理的側面を考慮する必要があり、これがデータセットのキュレーションとライセンス供与にかかる時間とコストを増加させる可能性があります。規制当局による個人情報やプロプライエタリなデータの利用に対する監視強化も、研究者がAIトレーニングデータセットに自由にアクセスしたり配布したりすることを困難にしています。
これらの課題は、市場参加者がデータセットの品質、アクセシビリティ、および利用可能性を確保するために、より慎重かつ戦略的なアプローチを取ることを促しています。
**市場の機会**
学術研究・出版向けAIデータセットおよびライセンス市場は、複数の魅力的な機会に恵まれています。
1. **マルチモーダルデータセットの開発とライセンス供与**: AIアプリケーションの複雑性が増すにつれて、テキスト、画像、音声、動画など、様々なデータタイプを網羅するデータセットの必要性が高まっています。これは、学術研究向けに特化した包括的なマルチモーダルデータセットを開発し、ライセンス供与を行うための大きな機会を提供します。マルチモーダルデータセットは、AIシステムが現実世界の相互作用をより良く理解することを可能にし、音声認識、コンピュータービジョン、自然言語処理の分野における進歩を促進します。このようなデータセットの成長は、生成AIの革新を強力に支援し、学術研究者がAIアプリケーションの限界を押し広げることを可能にします。例えば、異なるモダリティのデータを統合することで、より人間らしい対話型AIや、複雑な科学現象を理解するAIの開発が期待されます。
2. **倫理的に調達された高品質データセットへの注力**: 規制基準への準拠とデータの多様性を維持するため、機関やAI企業は、倫理的に調達された高品質なデータセットのキュレーションに注力しています。これは、信頼性と透明性の高いデータセットを求める市場のニーズに応えるものであり、データセットプロバイダーにとって、独自の価値提案を構築する機会となります。倫理的なデータセットは、AIモデルにおけるバイアスを軽減し、より公平で信頼性の高いAIシステムを開発するために不可欠です。この傾向は、データセットの品質と出所の透明性を重視する新しいビジネスモデルの出現を促進するでしょう。
3. **学術機関とAI企業間の協力の深化**: 世界中の学術研究機関は、公正なライセンス契約と高品質なデータセットへの幅広いアクセスを確保するために、AI企業との連携を強化しています。これらの協力は、データ共有の障壁を低減し、研究コミュニティ全体で利用可能なリソースを拡大します。AI企業にとっては、学術界の専門知識を活用し、研究開発を加速させる機会となり、学術機関にとっては、産業界の資金と技術リソースにアクセスできるメリットがあります。このような戦略的パートナーシップは、新たなデータセットの共同開発や、既存データセットの利用範囲拡大を可能にし、市場全体のイノベーションを促進します。
これらの機会は、市場参加者が革新的なデータソリューションを開発し、戦略的パートナーシップを形成し、AI研究エコシステム全体の成長を促進するための肥沃な土壌を提供します。
**地域分析**
学術研究・出版向けAIデータセットおよびライセンス市場は、地域によって異なる成長パターンと市場特性を示しています。
1. **北米**: 世界の学術研究・出版向けAIデータセットおよびライセンス市場において、北米は支配的な地位を確立しています。このリーダーシップは、同地域の高度な技術インフラ、スタンフォード大学やMITといった世界的に著名な研究機関の存在、そしてAIイノベーションに対する政府からの多大な支援に起因しています。特に米国では、国防高等研究計画局(DARPA)や国立科学財団(NSF)などの機関がAI研究に多額の資金を投入しており、これが高品質で専門的なデータセットの需要を刺激しています。大学、民間企業、政府機関間の強力な協力関係は、データセットの作成と共有において極めて重要な役割を果たしてきました。シリコンバレーを中心としたテクノロジーハブの存在は、AI研究と開発を加速させ、データセットの需要を刺激しています。また、知的財産権保護とデータプライバシーに関する比較的明確な法的枠組みが整備されていることも、市場の安定的な成長を支える要因となっています。
2. **アジア太平洋地域**: アジア太平洋地域は、世界の学術研究・出版向けAIデータセットおよびライセンス市場において最も急速に成長している地域です。急速なデジタルトランスフォーメーションとAI技術への多大な投資が、この地域の成長を牽引しています。モバイル技術の普及率の高さとeコマース部門の大幅な増加は、パーソナライズされたマーケティング、顧客サービス、コンテンツ生成におけるAIの採用に豊富な機会をもたらしています。これにより、これらのAIアプリケーションを開発・改善するためのデータセットの需要が急増しています。特に中国、インド、韓国、日本などの国々は、AI研究開発への積極的な投資と、大規模なデータ生成能力により、市場の成長に大きく貢献しています。中国の「次世代AI発展計画」や韓国の「AI国家戦略」など、各国政府によるAI戦略の推進や、研究機関と産業界の連携強化も、この地域の市場拡大を後押ししています。データセンターのインフラ整備やクラウドサービスの利用拡大も、データセットの収集・処理・配布を容易にし、市場成長を加速させています。
**セグメント分析**
学術研究・出版向けAIデータセットおよびライセンス市場は、様々なセグメントにわたって分析され、それぞれに独自の動向と支配的な特性が見られます。
1. **アプリケーション/ユースケース別セグメント:トレーニング**
* **トレーニングセグメントの優位性**: 市場において、トレーニングセグメントが圧倒的な優位を占めています。これは、小売、セキュリティ、エンターテイメント産業におけるコンピュータービジョンなどのアプリケーションで、視覚データが広範に利用されているためです。AIソリューション、例えば予測分析、自然言語処理、画像認識の開発には、高品質なデータセットが不可欠であり、これらは研究および出版のワークフローで広く活用されています。例えば、学術論文の自動分類、研究データのパターン認識、新しい科学的仮説の生成など、AIが関与するあらゆる研究活動の根幹には、モデルを効果的に訓練するための大規模なデータセットが存在します。ゲノミクス、社会科学、言語学などの分野では、大規模なデータがイノベーションを推進するため、トレーニング用データセットに対する需要は非常に堅調です。AIモデルが学習し、性能を向上させるためには、継続的に新しい、より多様なデータセットが必要とされるため、このセグメントの需要は今後も高まると予想されます。
2. **エンドユーザー/購入者別セグメント:大規模言語モデル(LLM)開発者**
* **LLM開発者の優位性**: 学術研究・出版向けAIデータセットおよびライセンス市場において、大規模言語モデル(LLM)開発者が支配的な地位を占めています。これらのエンティティは、Google、OpenAI、Metaなどの大手テクノロジー企業や、世界中の主要な研究機関を含み、高度な言語モデルを構築するために膨大で高品質なテキストデータセットに依存しています。LLM開発者はこれらのデータセットを使用して、自動コンテンツ要約、セマンティック検索、インテリジェント個別指導システム、論文作成支援ツールなど、様々な学術アプリケーションをサポートする基盤モデルをトレーニングします。LLMの機能が進化し続けるにつれて、そのトレーニングに必要なデータセットの規模と多様性も増大し、ウェブデータ、書籍、学術論文、コーディングデータなど、多岐にわたるデータソースが求められるため、このセグメントの市場シェアをさらに拡大させています。
3. **ライセンスタイプ別セグメント:プロプライエタリ・ライセンス**
* **プロプライエタリ・ライセンスの優位性**: 市場ではプロプライエタリ・ライセンスセグメントが優位を占めています。組織がこれらのライセンスを好むのは、特定の学術的および研究ニーズに合わせて調整された、独占的で高品質なデータセットを提供するからです。オープンアクセスデータセットが増加しているにもかかわらず、多くの企業や研究機関は、競合他社との差別化を図るため、あるいは独自の研究開発のために、排他的なデータセットを求めています。このアプローチは、データのプライバシーと法的および倫理的基準への準拠を保証し、ヘルスケア(患者データ)、気候科学(機密性の高い地理空間データ)、工学(産業秘密を含む設計データ)などの重要な研究分野にとって理想的です。プロプライエタリ・ライセンスは、データセットの利用を厳密に管理し、競争上の優位性を維持したい企業や研究機関にとって特に魅力的です。
4. **産業垂直セグメント:ライフサイエンスおよび製薬**
* **ライフサイエンスおよび製薬セグメントの優位性**: ライフサイエンスおよび製薬セグメントは、世界の学術研究・出版向けAIデータセットおよびライセンス市場を支配しています。このセグメントがデータ駆動型の手法に大きく依存していることが、創薬(新薬候補の特定)、ゲノム解析(疾患の遺伝的基盤の理解)、臨床試験の最適化(患者選択と結果予測)におけるイノベーションを促進しています。特に、次世代シーケンシング、電子カルテ、オミックスデータなどの大規模で複雑な生物学的データセットが不可欠であり、これらのデータセットはしばしば機密性が高く、厳格な規制要件の下で扱われます。ライセンス供与されたAIデータセットを利用することで、HIPAA(医療保険の携行性と説明責任に関する法律)などの厳格な規制基準への準拠を確保しつつ、高いデータ品質とセキュリティを維持することができます。この分野における継続的な研究開発投資とデータ量の爆発的な増加が、データセット需要を強く推進しています。
**競争環境と主要プレイヤー**
学術研究・出版向けAIデータセットおよびライセンス市場の主要プレイヤーは、市場での存在感を高めるために、高度な学術研究・出版向けAIデータセットおよびライセンス技術への投資や、コラボレーション、買収、パートナーシップなどの戦略を追求しています。これらの戦略は、製品ポートフォリオの拡大、技術力の強化、そして新たな市場セグメントへの浸透を目的としています。
* **Elsevier**: エルゼビアは、学術研究・出版向けAIデータセットおよびライセンス市場における新興プレイヤーです。エルゼビアの戦略は、研究体験を向上させるAI駆動型ソリューションの開発と展開に焦点を当てています。同社は、その広範な科学データリポジトリ(数百万の学術論文、書籍、研究データを含む)を活用することで、研究者が効率的なデータ分析と知識発見を促進する洗練されたツールを提供することを目指しています。例えば、AIを活用して関連性の高い研究を特定したり、データの傾向を分析したりするサービスを提供しています。これは、同社が長年にわたり培ってきた学術出版の専門知識と、最新のAI技術を融合させることで、研究者コミュニティに新たな価値を提供しようとする意欲を示しており、今後の市場における影響力拡大が期待されます。
**アナリストの見解と将来展望**
当アナリストによると、世界の学術研究・出版向けAIデータセットおよびライセンス市場は、AIモデルのトレーニングを支援するための最高品質のデータセットに対する需要の増加により、現在、急速な成長を遂げています。AI駆動の研究が進化するにつれて、多様なデータセットへのアクセスと、適切な倫理的利用の下での強固なライセンスフレームワークが不可欠となるでしょう。
将来的には、より高度なAIモデルの開発、特に生成AIの普及に伴い、データセットの量だけでなく、その質、多様性、そして倫理的な側面がこれまで以上に重要になります。データセットのキュレーション、アノテーション、検証のプロセスがより洗練され、自動化されることで、研究者はより迅速かつ効率的に高品質なデータにアクセスできるようになるでしょう。また、ブロックチェーン技術のような透明性の高いライセンス管理システムは、データ提供者と利用者の間の信頼を構築し、データ共有エコシステムをさらに強化する可能性があります。戦略的な投資と協力関係が、この市場の将来を形作り、データアクセシビリティの向上と倫理的課題への対処が含まれると予測されます。
この市場の参加者は、技術革新に投資し、学術機関、産業パートナー、政府機関との戦略的な提携を積極的に模索することで、競争力を維持し、新たな成長機会を捉えることができるでしょう。同時に、データプライバシー、著作権、AI倫理に関する規制の進化に常に注意を払い、それらに準拠したソリューションを提供することが成功の鍵となります。
Report Coverage & Structure
“`html
- エグゼクティブサマリー
- 調査範囲とセグメンテーション
- 調査目的
- 制限事項と仮定
- 市場範囲とセグメンテーション
- 考慮される通貨と価格設定
- 市場機会評価
- 新興地域/国
- 新興企業
- 新興アプリケーション/最終用途
- 市場トレンド
- 推進要因
- 市場の警告要因
- 最新のマクロ経済指標
- 地政学的影響
- テクノロジー要因
- 市場評価
- ポーターの5つの力分析
- バリューチェーン分析
- 規制の枠組み
- 北米
- 欧州
- アジア太平洋
- 中東およびアフリカ
- 中南米
- ESGトレンド
- 学術研究・出版向けAIデータセットおよびライセンスの世界市場規模分析
- 学術研究・出版向けAIデータセットおよびライセンスの世界市場概要
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 用途別
- 学術研究・出版向けAIデータセットおよびライセンスの世界市場概要
- 北米市場分析
- 概要
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 米国
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 用途別
- カナダ
- 欧州市場分析
- 概要
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 英国
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 用途別
- ドイツ
- フランス
- スペイン
- イタリア
- ロシア
- 北欧
- ベネルクス
- その他の欧州
- アジア太平洋市場分析
- 概要
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 中国
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 用途別
- 韓国
- 日本
- インド
- オーストラリア
- 台湾
- 東南アジア
- その他のアジア太平洋
- 中東およびアフリカ市場分析
- 概要
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- アラブ首長国連邦
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 用途別
- トルコ
- サウジアラビア
- 南アフリカ
- エジプト
- ナイジェリア
- その他のMEA
- 中南米市場分析
- 概要
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- ブラジル
- 用途別
- 概要
- 用途別(金額)
- トレーニング
- 金額別
- ファインチューニング
- 金額別
- 検索拡張生成 (RAG)
- 金額別
- 推論
- 金額別
- 顧客タイプ別
- 概要
- 顧客タイプ別(金額)
- 大規模言語モデル (LLM) 開発者
- 金額別
- アプリケーション開発者
- 金額別
- 企業
- 金額別
- 研究機関および学術機関
- 金額別
- ライセンスタイプ別
- 概要
- ライセンスタイプ別(金額)
- 独自ライセンス
- 金額別
- サブスクリプションベース
- 金額別
- オープンアクセスおよびパブリックライセンス
- 金額別
- 使用量ベースライセンス
- 金額別
- カスタム/エンタープライズライセンス
- 金額別
- 最終用途別
- 概要
- 最終用途別(金額)
- ライフサイエンスおよび医薬品
- 金額別
- 健康科学
- 金額別
- 食品科学
- 金額別
- 化学
- 金額別
- 工学
- 金額別
- 材料科学
- 金額別
- その他
- 金額別
- 用途別
- メキシコ
- アルゼンチン
- チリ
- コロンビア
- その他のラテンアメリカ
- 競合情勢
- 学術研究・出版向けAIデータセットおよびライセンス市場におけるプレイヤー別シェア
- M&A契約と提携分析
- 市場プレイヤー評価
- エルゼビア
- 概要
- 事業情報
- 収益
- 平均販売価格 (ASP)
- SWOT分析
- 最近の動向
- シュプリンガー・ネイチャー
- 電気電子学会 (IEEE)
- ウォルターズ・クルーワー N.V.
- テイラー&フランシス (インフォーマplcの一部門)
- アメリカ化学会
- クラリベイト
- プロクエスト (クラリベイトの一部)
- デジタルサイエンス
- セージ出版
- エルゼビア
- 調査方法
- 調査データ
- 二次データ
- 主要な二次情報源
- 二次情報源からの主要データ
- 一次データ
- 一次情報源からの主要データ
- 一次調査の内訳
- 二次および一次調査
- 主要な業界インサイト
- 市場規模推定
- ボトムアップアプローチ
- トップダウンアプローチ
- 市場予測
- 調査の仮定
- 仮定
- 制限事項
- リスク評価
- 調査データ
- 付録
- 議論ガイド
- カスタマイズオプション
- 関連レポート
- 免責事項
“`
*** 本調査レポートに関するお問い合わせ ***

「学術研究・出版向けAIデータセットおよびライセンス」とは、人工知能(AI)モデルの訓練、評価、検証、あるいは応用を目的として、学術分野の研究活動や出版業界の業務に特化して収集・整理されたデータセットと、その利用条件を定める法的枠組みであるライセンスの総称を指します。これらのデータセットは、一般的なAI開発用データとは異なり、高い専門性、正確性、信頼性が求められる学術的な文脈での利用を前提として構築されており、その利用には厳格な倫理的・法的な配慮が伴います。
この種のデータセットは、その情報源や形式によって多岐にわたります。例えば、自然言語処理(NLP)分野では、国内外の学術論文、専門書、学会発表資料、特許情報、歴史的文献、コーパスなどがテキストデータとして利用されます。これらは特定の専門用語、記述様式、論理構造を持っており、AIが学術的な文章を理解、生成、分析するための基盤となります。画像認識やコンピュータビジョン分野では、医学画像(MRI、CTスキャン)、生物学的標本画像、天文学的観測データ、地理空間情報、歴史的絵画や写真などがデータセットとして活用されます。また、音声認識や音声合成の分野では、研究者の講演録、インタビュー音声、特定の言語や方言の音声データなどが用いられることがあります。さらに、実験結果データ、アンケート調査データ、遺伝子情報などの構造化データも、学術研究における予測モデル構築やデータマイニングに不可欠なデータセットと言えるでしょう。これらのデータは、単一のモダリティに留まらず、テキストと画像を組み合わせたマルチモーダルデータセットとして提供されることも増えています。
これらの学術・出版向けAIデータセットの主な用途は、多岐にわたります。学術研究においては、AIモデルを用いて既存の大量の文献から特定の情報を抽出し、新たな研究テーマの発見や仮説生成を支援したり、研究の再現性を検証したりすることが挙げられます。例えば、特定の疾患に関する論文を網羅的に分析し、治療法や薬剤の傾向を自動で特定するシステムや、科学論文の査読プロセスを支援するAIの開発などが進められています。また、学術論文の自動要約、キーワード抽出、関連論文推薦システム、さらには多言語での学術コミュニケーションを促進するための専門分野に特化した機械翻訳モデルの訓練にも利用されます。出版業界においては、原稿の剽窃チェック、校正支援、論文のトピック分類、読者へのパーソナライズされたコンテンツ推薦、学術書の自動インデックス生成、アクセシビリティ向上のための画像説明文の自動生成などに活用されています。これにより、出版プロセスの効率化と品質向上が期待されています。
これらのデータセットを利用する上で不可欠なのが「ライセンス」です。学術データは、その性質上、著作権、プライバシー、倫理的配慮が強く求められるため、一般的なデータセットよりも厳格なライセンス契約が適用されることが多くあります。ライセンスは、データセットの利用範囲(研究目的のみか、商用利用も可能か)、改変の可否、再配布の条件、帰属表示の義務、そしてプライバシー保護や倫理的利用に関する条項などを明確に定めます。オープンライセンス(例:Creative Commons Attribution-NonCommercial-ShareAlikeなど)が適用される場合もあれば、特定の研究機関や企業との間で個別に締結されるプロプライエタリなライセンスも存在します。特に、個人情報や機密性の高い医療データ、未公開の研究成果などが含まれる場合には、厳重なデータガバナンスと、差分プライバシーや連合学習といったプライバシー保護技術の適用がライセンス条件として明記されることもあります。これにより、データの不正利用や情報漏洩を防ぎつつ、学術的な進歩を促進するバランスが図られています。
関連する技術としては、まずデータセットの大規模な保存と処理を可能にするクラウドコンピューティングプラットフォーム(AWS, Azure, GCPなど)が挙げられます。これらのプラットフォームは、AIモデルの訓練に必要な計算資源も提供します。次に、データセットの品質を確保するためのアノテーション(注釈付け)ツールや、データクリーニング、前処理技術も重要です。また、データセットのバージョン管理システム(DVCなど)は、研究の再現性を保証し、データセットの更新履歴を追跡するために不可欠です。さらに、AIモデルの訓練には、GPUやTPUといった高性能な計算ハードウェアが用いられ、大規模なデータセットから複雑なパターンを学習する能力を支えています。倫理的な側面からは、AIモデルがデータセットから学習したバイアスを特定し、軽減するための公平性評価ツールや、モデルの意思決定プロセスを説明可能にするXAI(Explainable AI)技術も、学術研究の信頼性を高める上で注目されています。これらの技術は、学術研究・出版向けAIデータセットの価値を最大限に引き出し、安全かつ倫理的なAI開発を推進するための基盤を形成しています。