AIインフラ市場:市場規模・シェア分析 – 成長動向と予測 (2025年~2030年)
AIインフラ市場は、提供(ハードウェアおよびソフトウェア)、展開(オンプレミスおよびクラウド)、エンドユーザー(政府・防衛など)、プロセッサアーキテクチャ(CPU、GPUなど)、および地域別にセグメント化されています。市場予測は金額(米ドル)で提供されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
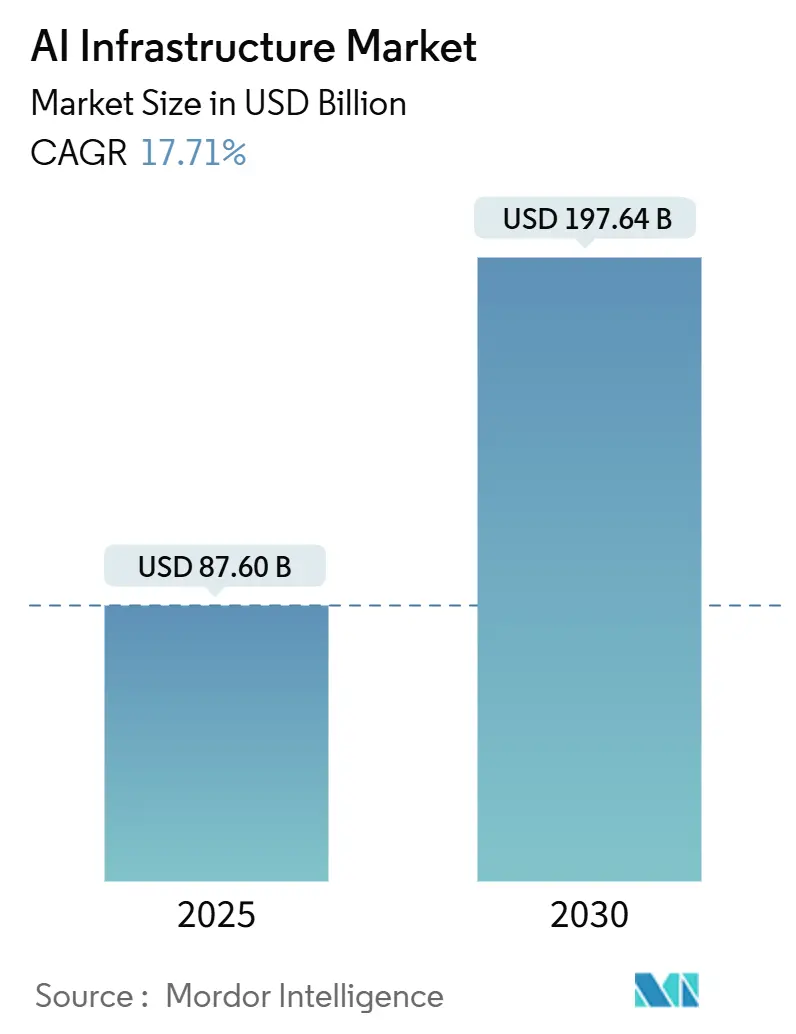
AIインフラ市場は、2025年には876億米ドルと推定され、2030年までに1,976億4,000万米ドルに達すると予測されており、予測期間(2025年~2030年)中の年平均成長率(CAGR)は17.71%です。最も成長が速い市場はアジア太平洋地域であり、最大の市場は北米です。市場の集中度は中程度です。
市場分析
この市場の成長は、限定的なパイロット段階から本番規模の展開への決定的な移行を反映しています。特に、ハイパースケーラー、企業、公共部門の機関は、大規模言語モデルや生成AIモデルを実行するために、専用のコンピューティング、高帯域幅ファブリック、高度な熱管理に依存しています。クラウドネイティブなアクセラレーターの迅速な利用可能性は、初期投資の障壁を下げています。上位3社のハイパースケーラーによる2025年のハードウェア、ソフトウェア、設備への投資は3,150億米ドルを超え、規模の必要性を強調しています。
2024年にはハードウェアが72.1%のシェアを占めていますが、ソフトウェアのCAGRが19.7%であることは、個別のコンピューティングアイランドではなく、統合されたプラットフォームへの移行を示しています。地域別では、北米が47.7%のシェアを占めていますが、アジア太平洋地域のCAGRが19.1%であることは、国家AI戦略と製造業のデジタル化イニシアチブが地域の需要を加速させていることを示唆しています。エンドユーザーのパターンもこの変革を反映しており、クラウドサービスプロバイダーが支出の51.3%を占める一方、エンタープライズセグメントのCAGRが21%であることは、AIが研究活動ではなく、中核的な運用能力になりつつあることを示しています。
主要なレポートのポイント
* 提供形態別: 2024年にはハードウェアが収益シェアの72.1%を占め、ソフトウェアは2030年までに19.7%のCAGRで拡大すると予測されています。
* 展開形態別: 2024年にはオンプレミス導入がAIインフラ市場シェアの56.4%を占め、クラウドソリューションは2030年までに20.6%のCAGRで成長すると予測されています。
* エンドユーザー別: 2024年にはクラウドサービスプロバイダーがAIインフラ市場規模の51.3%を占め、エンタープライズ需要は同期間に21%のCAGRで増加すると予測されています。
* プロセッサアーキテクチャ別: 2024年にはGPUがAIインフラ市場収益の67.4%を占め、2030年までに17.9%のCAGRで進展すると予測されています。
* 地域別: 2024年には北米が世界のAIインフラ支出の47.7%を占め、アジア太平洋地域は2030年までに最速の19.1%のCAGRを記録する見込みです。
世界のAIインフラ市場のトレンドと洞察
成長要因:
* ハイパースケーラーにおけるH100/G100 GPUの需要急増: ハイパースケーラーは数十億ドル規模の事前購入契約により、希少なH100および次世代G100アクセラレーターへの優先アクセスを確保しています。これにより、GPUの割り当てが競争上の優位性となり、資金力のあるプロバイダーが有利になっています。CoreWeaveのようなGPU-as-a-service専門企業も台頭し、オンデマンドのコンピューティング能力を提供しています。AMD MI300XやIntel Gaudi 3のような代替アーキテクチャも注目を集めていますが、エコシステムの成熟度は依然としてCUDA互換性に依存しています。
* AI特化型ネットワークファブリックの急速な進化: モデルサイズが兆単位のパラメータに達し、データセンターネットワークはノード間の遅延障壁を取り除く必要に迫られています。NVIDIA Quantum-X800 InfinibandおよびSpectrum-X800 Ethernetは、以前のバージョンと比較して5倍の帯域幅を提供する800 Gb/sリンクを実現し、大規模な同期GPUトレーニングを可能にしています。Microsoft AzureやOracle Cloud Infrastructureなどの初期採用企業がこれらのスイッチを導入しており、Corning EDGE8のような光ケーブルのアップグレードは、高密度GPUポッドのロスレススループットを保証しています。
* エネルギー効率の高い液冷技術の採用: 40 kWを超えるラック電力密度は、従来の空冷システムの能力を超え、直接チップ冷却や液浸冷却ソリューションが主流になりつつあります。これらの導入により、空冷と比較して10~30%のエネルギー節約が報告されており、データセンターがEUやカリフォルニア州の厳格なScope-2目標を達成するのに役立っています。Microsoftのゼロ水冷却へのコミットメントやGoogleの高度な液冷システムは、液冷技術の大規模な検証を強調しています。
* クラウドネイティブAIアクセラレーターインスタンスによるアクセスの民主化: AWS、Microsoft Azure、Google Cloud全体で50種類以上のGPU対応インスタンスタイプが提供されており、企業はトレーニングと推論の両方のワークロードに対してH100クラスターへの弾力的なアクセスが可能になっています。このモデルは、予算を設備投資から運用費用にシフトさせ、ソリューションまでの時間を短縮し、特定のワークロードに対して大手プロバイダーよりも30~50%低い価格で提供するニッチなクラウドの波を引き起こしています。
* 政府によるAIファブへのCHIPS型補助金やオープンソースAIフレームワークの最適化も、市場成長に貢献しています。
抑制要因:
* AIクラスGPUの慢性的な供給不足(2026年まで): 地震によるウェハー生産の混乱やTSMCの先進ノード容量の制限により、GPUの納期は12~18ヶ月に延びています。ハイパースケーラーが数年先の事前支払いで自社を保護しているため、この不均衡は悪化し、小規模な購入者はRTX 5090のようなデバイスに30~50%のプレミアムを支払うことになっています。競合他社はAMD MI300Xの生産を拡大し、IntelはGaudi 3を準備していますが、CUDAエコシステムのロックインは依然としてNVIDIAデバイスへの選好を偏らせています。
* レガシーデータセンターにおける400V/48V電力変換の限界: 10kWラック向けに設計された従来のデータセンターは、最大120kWを必要とするAIクラスターに対応する際に15%を超える効率損失に直面しています。800V高電圧直流バックプレーンへのアップグレードは、施設あたり数百万ドルの費用がかかる可能性があり、多くのプロジェクトを遅らせています。Open Compute Projectはラックあたり最大1MWの電力エンベロープを提唱していますが、採用はまだ均一ではありません。
* 国家AI輸出規制やScope-2コンプライアンスコストの増加も、市場の成長を抑制する要因となっています。
セグメント分析
* 提供形態別:ハードウェアの優位性とソフトウェアの加速
* ハードウェア: 2024年の支出の72.1%を占め、GPUクラスター、高帯域幅メモリ、特殊ネットワークの設備投資の集中度を強調しています。プロセッサへの支出が最大の項目であり、H100クラスターが数千ノード規模で拡大しています。ストレージアーキテクチャは、I/Oスタールを回避するために、統合されたHBMキャッシュを備えたNVMe over Fabricsへと移行し続けています。
* ソフトウェア: 規模は小さいものの、19.7%のCAGRで最も急速に拡大しているカテゴリです。クロスベンダーのオーケストレーションスタック、Tritonのようなコンパイラツールチェーン、MLOpsスイートは、より高い利用率を可能にし、組織が単なるデバイスではなく統合プラットフォームを重視するよう促しています。結果として、総所有コスト(TCO)の計算では、ソフトウェア主導の最適化が、AIインフラ市場における増分的なハードウェア性能よりも、期待されるROIの3分の1を占めるようになっています。
本レポートは、AIインフラ市場に関する包括的な分析を提供しており、その調査範囲、市場動向、成長予測、競合状況、および詳細な調査方法論を網羅しています。
1. 調査範囲と市場定義
本調査におけるAIインフラ市場は、機械学習ワークロードのトレーニングと推論を大規模に可能にする特殊なハードウェア、システムレベルソフトウェア、および高性能データセンターソリューションから生じる全ての収益を対象としています。具体的には、GPU、AIアクセラレータ、関連するストレージとメモリ、オーケストレーション層、そしてクラウドまたはオンプレミスでの提供モデルが含まれます。一方で、消費者向けエッジデバイスや、AIワークロードを直接加速しない汎用ITサービスは対象外とされています。
2. 市場の動向
市場は複数の要因によって推進されています。ハイパースケーラーにおけるH100/G100 GPUのバックログ急増、Infiniband NDRやEthernet 800GといったAI特化型ネットワークファブリックの急速な発展、エネルギー効率の高い液冷技術の採用拡大、AIファブに対する政府のCHIPS型補助金、クラウドネイティブAIアクセラレータインスタンスによるアクセス機会の民主化、そしてTritonやTVMなどのオープンソースAIフレームワークの最適化が挙げられます。
一方で、市場にはいくつかの阻害要因も存在します。AIクラスGPUは2026年まで慢性的な供給不足が続く見込みであり、レガシーデータセンターにおける400V/48V電力変換の制限、米中やEUにおけるソブリンAI輸出規制、そしてScope-2排出量コンプライアンスコストの上昇が課題となっています。
その他、サプライチェーン分析、規制状況、技術的展望、ポーターのファイブフォース分析、マクロ経済トレンドが市場に与える影響についても詳細に評価されています。
3. 市場規模と成長予測
AIインフラ市場は、2025年に876億米ドルと評価され、2030年までに1,976.4億米ドルに達すると予測されており、年平均成長率(CAGR)17.71%を記録する見込みです。
* 地域別: 北米は、ハイパースケーラーの拠点、半導体研究開発、政府の支援策により、世界の支出の47.7%を占めています。
* セグメント別: ソフトウェアはハードウェアよりも市場規模は小さいものの、オーケストレーション、コンパイラ、MLOpsプラットフォームがハードウェア利用率を向上させるため、年平均成長率19.7%で最も速く拡大しています。
* 提供形態別: ハードウェア(プロセッサ、ストレージ、メモリ)とソフトウェア(システム最適化、AIミドルウェア/MLOps)に分類されます。
* 展開形態別: オンプレミスとクラウドの二つのモデルがあります。
* エンドユーザー別: 企業、政府・防衛、クラウドサービスプロバイダーが主要なエンドユーザーです。
* プロセッサアーキテクチャ別: CPU、GPU、FPGA/ASIC(TPU、Inferentia、Gaudi、Cerebrasなど)、その他に分けられます。
4. GPU供給不足の状況
現在のGPU不足は深刻であり、業界のリードタイムは12~18ヶ月に及びます。価格は2026年以降に新たな生産能力が立ち上がるまで、メーカー希望小売価格(MSRP)を最大50%上回る可能性があります。
5. 競合状況
市場の競合状況では、NVIDIA Corporation、Intel Corporation、Advanced Micro Devices (AMD)、Amazon Web Services, Inc.、Microsoft Corporation、Google LLC、IBM Corporation、Cisco Systems, Inc.、Hewlett Packard Enterprise、Dell Technologies, Inc.、Samsung Electronics Co., Ltd.、Micron Technology, Inc.、Arm Holdings plc、Synopsys, Inc.、Baidu, Inc.、Alibaba Cloud、Tencent Cloud、Cerebras Systems、Graphcore、Huawei Technologies Co., Ltd.といった主要企業のプロファイルが提供されています。これには、各社のグローバルおよび市場レベルの概要、主要セグメント、財務情報、戦略情報、市場ランク/シェア、製品とサービス、最近の動向が含まれます。また、戦略的動向と市場シェア分析も行われています。
6. 市場機会と将来展望
レポートでは、AIインフラ市場における新たな機会と将来の展望についても詳細に分析されており、今後の市場成長を牽引する可能性のある分野が特定されています。
7. 調査方法論の信頼性
Mordor Intelligenceの調査方法論は、その信頼性の高さが強調されています。一次調査では、データセンター設計者、ハイパースケールクラウドアーキテクト、半導体ロードマップ管理者、調達責任者などへのインタビューを通じて、GPU密度の高いサーバーの平均販売価格、リフレッシュサイクル、液冷改修の現実的なペースなどの情報が収集されました。デスク調査では、米国エネルギー情報局、半導体工業会、OECD AI政策オブザーバトリーなどの一次情報源に加え、Open Compute Project、AI Infrastructure Alliance、Uptime Instituteといった業界団体からのデータ、企業の10-K提出書類、投資家向け資料などが活用されています。
市場規模の算出と予測は、国のデータセンター在庫とAI関連の年間設備投資から始まるトップダウンアプローチと、GPU出荷記録やサーバーの平均販売価格を組み合わせたボトムアップアプローチを統合して行われます。主要変数には、ラックあたりのGPU搭載率、サーバーのASP中央値、世界のクラウド設備投資成長率、液冷浸透率、電力使用効率の変化などが含まれ、これらは2030年までトレンド分析されます。予測には多変量回帰分析が用いられ、エネルギー価格の急騰やシリコン供給ショックなどのシナリオ分析も実施されます。
データ検証は、二段階のピアレビュー、第三者指標との異常スキャン、および経営陣による承認を経て行われます。モデルは毎年更新され、大規模なファブ生産能力の変更やクラウド支出の変動があった場合には、中間更新が実施されます。
Mordor IntelligenceのAIインフラベースラインは、AI加速に直接関連するハードウェアとシステムソフトウェアに焦点を当て、最新の出荷データや設備投資データに基づいて更新されるため、市場の動向を正確に把握するための信頼できる情報源となっています。

1. はじめに
- 1.1 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
-
4.1 市場の推進要因
- 4.1.1 ハイパースケーラーにおけるH100/G100 GPUのバックログ急増
- 4.1.2 急速なAI特化型ネットワークファブリック(Infiniband NDR、Ethernet 800 G)
- 4.1.3 エネルギー効率の高い液冷の採用
- 4.1.4 AIファブに対する政府のCHIPS型補助金
- 4.1.5 クラウドネイティブAIアクセラレーターインスタンスによるアクセスの民主化
- 4.1.6 オープンソースAIフレームワークの最適化(例:Triton、TVM)
-
4.2 市場の阻害要因
- 4.2.1 2026年まで続くAIクラスGPUの慢性的な供給不足
- 4.2.2 レガシーDCにおける400 V / 48 V電力変換の制限
- 4.2.3 ソブリンAI輸出規制(米中、EU)
- 4.2.4 増加するスコープ2排出量コンプライアンスコスト
- 4.3 サプライチェーン分析
- 4.4 規制環境
- 4.5 技術的展望
-
4.6 ポーターの5つの力分析
- 4.6.1 買い手の交渉力
- 4.6.2 供給者の交渉力
- 4.6.3 新規参入の脅威
- 4.6.4 代替品の脅威
- 4.6.5 競争上の対抗関係
- 4.7 市場に対するマクロ経済トレンドの評価
5. 市場規模と成長予測(金額)
-
5.1 提供別
- 5.1.1 ハードウェア
- 5.1.1.1 プロセッサ
- 5.1.1.2 ストレージ
- 5.1.1.3 メモリ
- 5.1.2 ソフトウェア
- 5.1.2.1 システム最適化
- 5.1.2.2 AIミドルウェア / MLOps
-
5.2 展開別
- 5.2.1 オンプレミス
- 5.2.2 クラウド
-
5.3 エンドユーザー別
- 5.3.1 企業
- 5.3.2 政府および防衛
- 5.3.3 クラウドサービスプロバイダー
-
5.4 プロセッサアーキテクチャ別
- 5.4.1 CPU
- 5.4.2 GPU
- 5.4.3 FPGA/ASIC (TPU, Inferentia, Gaudi, Cerebras)
- 5.4.4 その他
-
5.5 地域別
- 5.5.1 北米
- 5.5.1.1 米国
- 5.5.1.2 カナダ
- 5.5.1.3 メキシコ
- 5.5.2 南米
- 5.5.2.1 ブラジル
- 5.5.2.2 アルゼンチン
- 5.5.2.3 南米のその他の地域
- 5.5.3 ヨーロッパ
- 5.5.3.1 イギリス
- 5.5.3.2 ドイツ
- 5.5.3.3 フランス
- 5.5.3.4 スウェーデン
- 5.5.3.5 ヨーロッパのその他の地域
- 5.5.4 アジア太平洋
- 5.5.4.1 中国
- 5.5.4.2 日本
- 5.5.4.3 インド
- 5.5.4.4 オーストラリア
- 5.5.4.5 韓国
- 5.5.4.6 アジア太平洋のその他の地域
- 5.5.5 中東およびアフリカ
- 5.5.5.1 サウジアラビア
- 5.5.5.2 アラブ首長国連邦
- 5.5.5.3 トルコ
- 5.5.5.4 南アフリカ
- 5.5.5.5 中東およびアフリカのその他の地域
6. 競合状況
- 6.1 戦略的動き
- 6.2 市場シェア分析
-
6.3 企業プロファイル(グローバルレベルの概要、市場レベルの概要、主要セグメント、利用可能な財務情報、戦略情報、市場ランク/シェア、製品とサービス、最近の動向を含む)
- 6.3.1 NVIDIA Corporation
- 6.3.2 Intel Corporation
- 6.3.3 Advanced Micro Devices (AMD)
- 6.3.4 Amazon Web Services, Inc.
- 6.3.5 Microsoft Corporation
- 6.3.6 Google LLC
- 6.3.7 IBM Corporation
- 6.3.8 Cisco Systems, Inc.
- 6.3.9 Hewlett Packard Enterprise
- 6.3.10 Dell Technologies, Inc.
- 6.3.11 Samsung Electronics Co., Ltd.
- 6.3.12 Micron Technology, Inc.
- 6.3.13 Arm Holdings plc
- 6.3.14 Synopsys, Inc.
- 6.3.15 Baidu, Inc.
- 6.3.16 Alibaba Cloud
- 6.3.17 Tencent Cloud
- 6.3.18 Cerebras Systems
- 6.3.19 Graphcore
- 6.3.20 Huawei Technologies Co., Ltd.
7. 市場機会と将来展望
*** 本調査レポートに関するお問い合わせ ***

AIインフラとは、人工知能(AI)の開発、学習、推論、そして運用に必要なあらゆる基盤を指す包括的な概念でございます。具体的には、高性能なハードウェア、効率的なソフトウェア、安定したネットワーク、そして大量のデータを管理するシステムなど、AIモデルのライフサイクル全体を支えるための技術要素の総体を意味します。AI技術が社会の様々な分野で活用されるにつれて、その基盤となるAIインフラの重要性は飛躍的に高まっております。
AIインフラは、主に以下の要素で構成されます。
第一に、ハードウェアでございます。AIの学習、特に深層学習においては、膨大な計算処理能力が求められます。このため、グラフィックス処理ユニット(GPU)が中心的な役割を果たします。NVIDIA社のH100やA100といった高性能GPUは、並列計算に特化しており、AIモデルの学習時間を大幅に短縮します。また、Googleが開発したテンソル処理ユニット(TPU)や、エッジデバイス向けのニューラル処理ユニット(NPU)なども、特定のAI処理に最適化されたハードウェアとして利用されています。これらの計算資源を効率的に連携させるためには、InfiniBandやRoCEといった高速ネットワーク技術が不可欠です。さらに、学習データや推論結果を迅速に読み書きするための高速ストレージ(SSD、並列ファイルシステムなど)も重要な要素となります。
第二に、ソフトウェアでございます。AIモデルの開発には、TensorFlow、PyTorch、JAXといった深層学習フレームワークが広く利用されます。これらのフレームワークは、モデルの構築、学習、評価を効率的に行うための機能を提供します。また、AIモデルの開発からデプロイ、運用、監視までの一連のプロセスを管理するMLOps(Machine Learning Operations)プラットフォームも重要です。KubeflowやMLflowなどがその代表例で、AI開発の生産性と信頼性を向上させます。さらに、DockerやKubernetesといったコンテナ技術は、AIアプリケーションのポータビリティとスケーラビリティを確保し、リソースの効率的な管理を可能にします。データ管理においては、データベース、データレイク、データウェアハウスといったツールが、AI学習に必要な大量のデータを収集、保存、処理するために用いられます。オペレーティングシステムとしてはLinuxが主流であり、GPUを最大限に活用するためのCUDAやcuDNNといったライブラリも不可欠です。
第三に、クラウドサービスでございます。AIインフラの構築と運用には多大なコストと専門知識が必要となるため、多くの企業がAmazon Web Services (AWS)、Google Cloud Platform (GCP)、Microsoft Azureといったクラウドプロバイダーが提供するサービスを利用しています。これらのクラウドサービスは、高性能なGPUインスタンス(IaaS)、AI/MLプラットフォーム(PaaS)、特定のAI機能を提供するサービス(SaaS)など、多様な形態でAIインフラを提供しております。これにより、企業は必要な時に必要なだけ計算資源を利用でき、初期投資を抑えながらAI開発を進めることが可能になります。
AIインフラの主な用途は多岐にわたります。
最も重要な用途の一つは、AIモデルの開発と学習でございます。特に、大規模言語モデル(LLM)や画像認識モデルといった深層学習モデルの学習には、膨大なデータと計算資源が不可欠です。AIインフラは、これらのモデルが複雑なパターンを学習し、高い精度を発揮するための基盤を提供します。
次に、AIモデルの推論とデプロイでございます。学習済みのAIモデルを実際のビジネス環境やアプリケーションで利用する際には、リアルタイムでの高速な推論処理や低レイテンシが求められることが多くございます。AIインフラは、クラウド上での推論サービスや、エッジデバイス上での推論(エッジAI)を可能にし、AIの社会実装を支えます。
また、AI学習の質を左右するデータ管理と前処理も重要な用途です。AIインフラは、学習データの収集、アノテーション(注釈付け)、クレンジング、変換といった前処理を効率的に行い、高品質なデータセットをAIモデルに供給するための仕組みを提供します。
さらに、AIアルゴリズムやモデルの新たな可能性を探る研究開発、そして自動運転、医療診断、金融予測、顧客サービス、製造業の品質管理など、多岐にわたる産業でのAI活用を支える基盤としても機能します。
関連技術としては、高性能コンピューティング(HPC)が挙げられます。AIの学習は、HPCの一種として位置づけられ、その技術的進歩がAIインフラの発展を牽引しています。クラウドコンピューティングは、AIインフラ提供の主要な形態であり、その柔軟性とスケーラビリティがAI開発を加速させています。ビッグデータ技術は、AI学習に必要な大量のデータを効率的に処理するために不可欠であり、HadoopやSparkといったフレームワークが活用されます。コンテナ・オーケストレーション技術であるKubernetesは、AIワークロードのリソース管理とスケーリングを自動化し、運用効率を高めます。MLOpsは、AIモデルのライフサイクル全体を管理し、開発から運用までのプロセスを標準化・自動化する重要なアプローチです。エッジコンピューティングは、推論処理をデータ発生源に近い場所で行うことで、リアルタイム性やプライバシー保護のニーズに応えます。長期的には、量子コンピューティングが将来のAI計算に革新をもたらす可能性も秘めています。
市場背景としましては、近年、生成AIや大規模言語モデル(LLM)の登場により、AI技術への需要が爆発的に増加しております。これにより、高性能な計算資源、特にGPUの需要が供給を大きく上回り、ボトルネックが生じている状況です。AIインフラの構築と運用には高額なコストがかかるため、クラウドプロバイダー各社はAIインフラサービスの強化に注力し、激しい競争を繰り広げています。一方で、セキュリティ、コスト、データ主権といった観点から、オンプレミス環境とクラウド環境を組み合わせたハイブリッドなAIインフラの需要も高まっています。また、AIインフラの電力消費量が増大する中で、サステナビリティへの意識も高まり、省電力化や効率化が重要な課題となっております。
将来展望としましては、AIインフラはさらなる高性能化と効率化を追求していくでしょう。GPUの進化はもちろんのこと、特定のAIワークロードに特化した新たなAIチップ(ASIC)の開発が進み、計算能力は飛躍的に向上すると予想されます。同時に、環境負荷低減と運用コスト削減のため、省電力化技術の開発も加速するでしょう。ソフトウェアスタックにおいては、MLOpsの標準化と自動化がさらに進展し、AIモデルの開発から運用までのプロセスがよりシームレスになることが期待されます。IoTデバイスの普及に伴い、エッジAIの活用が拡大し、AIインフラはクラウドからエッジへと分散化していく傾向が強まるでしょう。これにより、より多くの企業や開発者がAIインフラを利用しやすくなり、AIの民主化が進むと考えられます。また、AIモデルやデータの保護を目的としたセキュリティ技術の強化も不可欠です。長期的には、量子AIといった革新的な技術がAIインフラのあり方を根本から変える可能性もございます。AIインフラは、専門知識がなくてもAIを開発・運用できるサービスとして、今後も進化し続けることでしょう。