AIトレーニングデータセットの市場規模と見通し、2025-2033

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
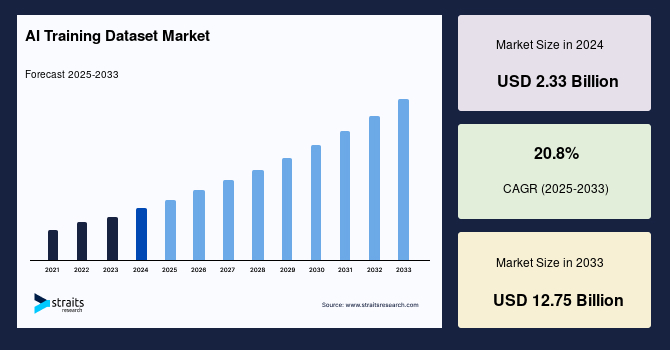
世界のAIトレーニングデータセット市場は、2024年に233億米ドルと評価され、2025年には281億米ドルから2033年には1275億米ドルに達する見込みで、予測期間(2025年-2033年)中に年平均成長率(CAGR)が20.8%で成長すると予測されています。人工知能(AI)は、機械が自らの誤りから学び、人間の行動を模倣し、環境に適応できる能力を与えます。これらの機械は、大量のデータを分析し、特定の活動を行うためのパターンを見つけるように訓練されています。特定のタスクを実行するためにこれらのロボットを導入するには、専門的なデータセットが必要です。AIトレーニングデータセットの必要性が高まっており、この需要に応えることが求められています。提供されるデータセットは、機械がどれだけ効果的に動作するかを決定し、AIの効果を向上させます。そのため、高品質なトレーニングデータセットを提供することが重要です。さらに、データ準備のスピードを上げ、予測精度を向上させる助けにもなります。市場のプレーヤーは、データ品質を向上させるのに役立つ企業の買収に注力しています。
ビッグデータの出現は、人工知能市場の拡大を助長すると予想されます。ビッグデータは、大量のデータを記録、保存、分析する必要があります。エンドユーザーは、ビッグデータに関連する計算モデルの監視と改善の必要性により、人工知能ソリューションの採用を加速させています。注釈付きデータは、音声認識や画像認識などの重要な領域でAIモデルや機械学習システムの訓練を促進するため、AIの採用はAIトレーニングデータセットの需要を大幅に増加させると予想されます。データ注釈は、将来の結果を予測し、意思決定を行うために必要なデータを明示的に提供することでAIを強化します。国防、詐欺検出、マーケティング、医療情報学、サイバーセキュリティなど、さまざまなアプリケーションからのデータを含むドメイン固有のデータが、多くの公的および私的組織によって収集されています。データ注釈は、こうした非構造化データと非管理データの各データの精度を継続的に向上させることを可能にします。
アジア太平洋地域では、個人情報保護に関する厳しい規制によってデータ収集が制約されると予想されています。また、データの誤った分類は市場の成長に対する障壁となります。データ注釈ツールにおける主な問題は出力精度です。データの不正確さなど、出力の品質に関する懸念は最小限に抑える必要があります。場合によっては、手動のラベリングが正しく行われず、これらのラベルを見つけるのに時間がかかることがあり、ビジネスのコストが増加します。しかし、自動化されたAIトレーニングデータセットツールの精度は、先進的なアルゴリズムの進化によって向上することが予想されており、手動の注釈とツールコストの需要を低下させるでしょう。
デジタルコンテンツの量は、特にスマートフォンに組み込まれたカメラを備えたデジタルキャプチャデバイスの増加に伴い、指数関数的に増加しています。視覚的およびデジタル情報が、さまざまなアプリケーション、ウェブサイト、ソーシャルネットワーク、その他のデジタルチャネルを通じて収集され、共有されています。データ注釈を通じて、いくつかの企業はこの自由にアクセスできるウェブコンテンツを利用して、顧客により革新的で良質なサービスを提供しています。電子健康記録(EHR)システムの使用が増加するにつれて、集められた非構造化テキスト記録は臨床研究における最も重要な資源の一つになっています。これらの要因は、予測期間中に市場成長の大きな機会を生み出すと予想されています。
アジア太平洋地域は、世界のAIトレーニングデータセット市場で最大のシェアを占め、予測期間中にCAGR21.5%で成長すると予想されています。インドなどの発展途上国の企業は、企業を近代化するために革新的な技術の採用率を大幅に向上させています。また、複数の主要なプレーヤーがアジア太平洋地域での影響力を拡大することに注力しています。これらのデータセットは、ローカリゼーション、屋内環境、ナビゲーションの研究と進展に役立ちます。さらに、マイクロソフトなどの主要なプレーヤーがこの地域での存在感を高めています。これらの要素は、地域でのデータセットの使用を増加させ、予測期間中に大きな成長をもたらすと予測されています。
ヨーロッパは、予測期間中にCAGR20.6%で成長し、1990.20百万米ドルを生み出すと予想されています。ワークフロー管理、ブランド広告、トレンド予測の技術を統合することにより、AIはヨーロッパの企業管理慣行を進化させています。これらの要因により、企業は機械学習や人工知能技術に多大な投資を行い、AIトレーニングデータセット市場の拡大を促進しています。企業の生産性を向上させるために、多くのテック企業や小規模なスタートアップがAIの導入に投資しています。AIトレーニングデータセットの需要増加は、人工知能の需要との直接的な関係によって加速されます。
北米は、予測期間中に大きな成長が期待されています。ベンダーは、新しいデータセットを提供し、北米の新興セクターでの人工知能技術の導入を加速させることに注力しています。これらの進展は、市場でのトレーニングデータセットの受け入れに影響を与え、トレーニングデータセット市場の大部分にサービスを提供します。ラテンアメリカの金融機関は、国際的な同業者と同様にAIなどの新技術を導入することが多いですが、特有の課題にも直面しています。しかし、これらの課題を克服することは次第に容易になっています。技術と投資の水準が北米の同業者よりも低いラテンアメリカ諸国は、優れたリソースを持ち、機会を利用し、問題を解決することを選択するかもしれません。この地域の国々は、急速な技術革新に注意を払い、機会を活かすための国家戦略を構築する必要があります。
画像/動画セグメントは市場への最大の貢献者であり、予測期間中にCAGR22.2%で成長すると予想されています。このプロセスでは、画像/動画に手動でメタデータをキャプションやキーワードとして割り当てるか、コンピュータシステムによって行われます。この大規模な成長は、主要なステークホルダーがさまざまなコンテキストで使用できる新しいデータセットを提供するための努力によるものです。テキストセグメントも、臨床研究やeコマースでの応用の増加により、大きなシェアを占めています。EHRシステムの導入が進む中、臨床データ、特に非構造化テキストドキュメントの蓄積は、臨床研究の貴重な資源の一つとなっています。統計的自然言語処理(NLP)モデルは、臨床テキストに埋め込まれた情報を解放するために開発されました。さまざまなソースからテキストデータセットを収集することは、人間の言語のテキスト表現を理解できる技術の開発に役立ちます。機械とアプリケーションは、この段階に進むために膨大な量のテキストデータを消費する必要があります。テキストラベリングは、ソーシャルメディアモニタリングで推奨システムを構築するのに広く使用されています。
自動車セグメントは市場シェアで最も大きく、予測期間中にCAGR21.1%で成長すると予測されています。このセグメントには、自動車製造、サプライチェーンビジネス、および自動運転車の開発が含まれます。自動車業界におけるデータ収集とラベリングの主要な使用例は、車内エンターテイメントのための音声およびスピーチ認識、ユーザー行動の理解と予測、自動運転車です。AIは、自動運転車から製造フロアの先進的ロボティクスに至るまで、自動車業界の運営方法を急速に変革しています。AIは、機械学習の革新的な可能性のおかげで、自動車セクターの新しい価値の未来を創造する主導的な役割を果たしています。自動運転車におけるAIの使用は広く認められ称賛されていますが、他の重点分野には、生産、エンジニアリング、サプライチェーン、顧客体験、モビリティサービスが含まれます。
ITセグメントも予測期間中に大きな成長が期待されています。このセグメントには、テクノロジー、ソフトウェア、関連サービス業界が含まれます。IT業界におけるデータ収集とラベリングの主要な使用例は、人間の言語をよりよく理解するための自動音声認識、顧客関係管理(CRM)/顧客体験管理(CEM)、コンサルティングサービス、機械翻訳、ソーシャルメディア分析、バーチャルアシスタント、チャットボットです。市場のさまざまなテクノロジー企業は、機械学習技術を利用してユーザー体験を向上させ、革新的な製品を開発しています。機械学習技術が効率的であるためには、高品質なトレーニングデータが必要であり、MLアルゴリズムが継続的に最適化されることを保証します。さらに、高品質なデータセットは、IT企業がコンピュータビジョン、クラウドソーシング、データ分析、バーチャルアシスタントなどのさまざまなソリューションを向上させるのに役立ちます。これらの要因は、セクターにおけるトレーニングデータセットの高い使用に寄与しています。
ガートナーによると、政府はデジタルイニシアティブの拡大に注力する必要があります。なぜなら、2023年までに全体的な体験戦略のない政府の85%以上がサービスの変革に失敗するからです。そのため、政府は企業の後に続いてAIに投資する準備が整っています。小売セグメントも、予測期間中にデータ収集とラベリング市場で大きな成長が見込まれています。小売業およびeコマースセグメントは、食料品店、eコマースプラットフォーム、小売チェーン/輸送店舗のデータ収集とラベリングプロセスを保持しています。画像ラベリングを用いることで、オンラインショッピングをする顧客は、選んだテクスチャ、プリント、色の写真を撮影することによって衣類やアクセサリーを検索できます。スマートフォンでキャプチャされた写真はアプリにアップロードされ、AI技術を使用して類似の商品を見つける商品在庫を検索します。
このレポートの詳細なセグメントデータ、予測、地域の洞察が含まれており、購入可能です。
Report Coverage & Structure
AIトレーニングデータセットの市場分析レポート構造の概要
本レポートはAIトレーニングデータセットの市場を包括的に分析したもので、多様なセクションに分かれています。以下にその構造を詳細にまとめます。
1. はじめに
レポートの冒頭では、AIトレーニングデータセットの市場の重要性とその背景について説明されており、読者に市場の全体像を理解させる内容になっています。
2. 調査方法論
このセクションでは、調査の目的、制限事項、仮定、通貨および価格設定の考慮点など、調査の枠組みが詳述されています。
3. 市場機会の評価
- 新興地域/国
- 新興企業
- 新興アプリケーション/エンドユーザー
市場の潜在的な機会を評価し、新たに登場する地域、企業、アプリケーションについて分析しています。
4. 市場動向
市場を取り巻くトレンド、ドライバー、警告要因、最新のマクロ経済指標、地政学的影響、技術的要因について説明しています。
5. 市場評価
ポーターのファイブフォース分析やバリューチェーン分析を用いて、競争環境を評価しています。
6. 規制フレームワーク
北米、ヨーロッパ、アジア太平洋地域、中東・アフリカ、ラテンアメリカにおける規制の枠組みについて詳述されています。
7. ESGトレンド
環境、社会、ガバナンスの観点からAIトレーニングデータセットの市場におけるトレンドが論じられています。
8. 地域別市場分析
- 北米市場分析
- ヨーロッパ市場分析
- アジア太平洋市場分析
- 中東・アフリカ市場分析
- ラテンアメリカ市場分析
それぞれの地域における市場の詳細な分析が行われ、タイプ別および業界別の評価が提供されています。
9. 総括
最後に、AIトレーニングデータセットの市場に対する総合的な見解と今後の展望が示されています。
このレポートは、AIトレーニングデータセットの市場を多角的に分析しており、業界関係者にとって有用な情報を提供する内容となっています。
*** 本調査レポートに関するお問い合わせ ***

AIトレーニングデータセットとは、人工知能(AI)モデルを学習させるために使用されるデータの集まりを指します。このデータセットは、モデルが特定のタスクを実行できるようになるために必要な情報を含んでおり、画像、音声、テキストなど、さまざまな形式のデータから構成されることがあります。AIの性能は、このトレーニングデータセットの質と量に大きく依存するため、適切なデータセットの選定と準備は非常に重要です。
トレーニングデータセットには、主に教師あり学習、教師なし学習、強化学習に関連するデータがあります。教師あり学習では、入力データに対して正しい出力が与えられ、モデルはその関係を学習します。例えば、画像認識タスクにおいて、特定の画像に対してそのラベル(猫、犬など)が付与されたデータが必要です。一方、教師なし学習では、入力データに対して正しい出力が存在せず、モデルはデータのパターンや構造を自ら見つけ出します。この場合、クラスタリングや次元削減などの手法が用いられます。さらに、強化学習では、エージェントが環境と相互作用しながら報酬を得ることを通じて学習を行うため、トレーニングデータセットはエージェントの行動と結果に基づく経験から構成されます。
AIトレーニングデータセットは、さまざまな用途に利用されます。例えば、自動運転車の開発においては、カメラで撮影した道路や障害物の画像データがトレーニングデータセットとして用いられ、車両が周囲の状況を理解し、適切に運転する能力を養います。また、自然言語処理の分野では、テキストデータセットが使用され、AIが人間の言葉を理解し、文章を生成したり、翻訳したりする能力を向上させるために役立ちます。音声認識システムや感情分析など、さまざまなAIアプリケーションがトレーニングデータセットによって支えられています。
関連技術としては、データの収集、前処理、アノテーションなどのプロセスがあります。データの収集は、インターネットからのクローリングやセンサーデータの取得など、さまざまな手法で行われます。前処理は、収集したデータをAIモデルに適した形式に変換する作業であり、ノイズの除去や正規化、特徴抽出などが含まれます。アノテーションは、データにラベルやメタデータを付与する作業であり、教師あり学習において非常に重要なステップです。これらのプロセスを通じて、高品質なトレーニングデータセットを作成することが、AIモデルの性能向上に貢献します。
最後に、AIトレーニングデータセットの質を向上させるためには、データの多様性や偏りを考慮することが重要です。多様なデータを使用することで、モデルはさまざまな状況に対応できるようになります。また、バイアスのないデータセットを作成することで、AIの公正さや信頼性を向上させることができます。このように、AIトレーニングデータセットは、AI技術の発展とその実用化において欠かせない要素であると言えるでしょう。