データ収集とラベリングの市場規模と展望、2025-2033

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
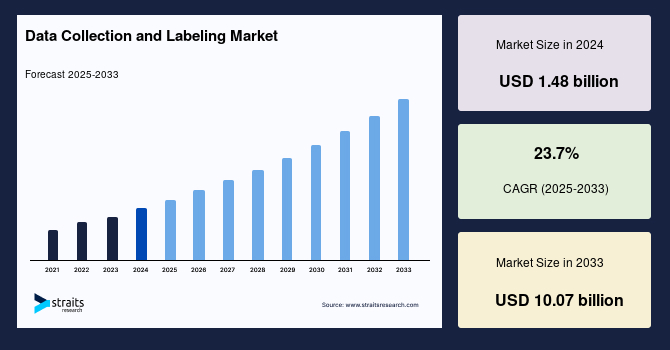
世界のデータ収集およびラベリング市場の規模は、2024年には14.8億米ドルと評価され、2025年には18.4億米ドルから成長し、2033年までに100.7億米ドルに達すると予測されています。予測期間(2025年から2033年)において、年平均成長率は23.7%です。データ収集およびラベリングとは、機械学習アプリケーションのために生データを体系的に収集し、注釈を加えてその意義と使いやすさを向上させるプロセスを指します。このプロセスには、画像、テキスト、センサーのデータセットをキュレーションし、文脈と意義を提供するために注釈やラベルを追加することが含まれます。これらの注釈付きデータセットの利用は、機械学習モデルのトレーニングの過程で重要であり、その精度と効率を向上させます。データ収集とラベリングは、自動運転車、ヘルスケア、電子商取引などの複数のセクターで重要です。これは、優れた注釈付きデータセットを提供することで人工知能技術の進歩と向上を可能にします。
市場シェアの成長は、社会的に共有された画像からビジネスインサイトを抽出し、タグ付けされていない写真コレクションを自動的に整理するなどの利点に起因しています。また、条件モニタリング、地形検出、摩耗検出、緊急車両検出などの高度な安全機能を開発するのにも役立ちます。AIアプリケーションは、診断、治療計画、患者ケアを改善するためにヘルスケアでますます使用されています。重要な要素は、AIアルゴリズムがX線、MRI、CTスキャンなどの複雑な医療画像を解読する医療画像の分析です。モルガン・スタンレーの最近の報告によれば、ヘルスケア企業の予算におけるAIおよび機械学習(ML)の割り当ては、2022年の5.5%から翌年には10.5%に増加する見込みです。投資銀行によると、ヘルスケア企業のほとんど、正確には94%が、AIとMLをさまざまなオペレーションで利用しています。
さらに、ヘルスケア業界は機械学習技術を利用して、特定のケースで組織化されたデータセットを作成しています。これは、組織のデータの保存と保護を支援し、労働負荷が高い時期、スタッフの不足、患者の流入中にワークフローを合理化するために使用できる堅牢な機械学習データの管理を可能にします。したがって、ヘルスケアでのAIの使用、特に医療画像の分析における、正確に注釈を付けられたデータセットの重要性が強調されます。市場のトレンドは、データセットの開発を大きく進展させ、AIアプリケーションを通じてヘルスケアの診断と治療計画の進展を促進します。
データ収集とラベリングは、特にプライバシーが最重要の業界において敏感なデータを扱う際に課題を抱えています。個人情報を保護し、GDPR(一般データ保護規則)や世界中の類似のプライバシー法などの規制を遵守するためには厳格な措置が必要です。2023年のインドの最新のデータ保護法であるデジタル個人データ保護(DPDP)法は、個人の明示的な同意がない限り、個人データを処理してはならないと規定しています。この法律はまた、個人データが「合法的な目的」であれば許可なしに処理できることも規定しています。
国際プライバシー専門家協会(IAPP)が2023年に実施した調査では、ヨーロッパの組織の平均プライバシー予算は110万ユーロであることが明らかとなりました。また、EUのプライバシー専門家の年間基本給は98,893ユーロであり、プライバシーテクノロジーベンダーの数は2017年以来ほぼ8倍に増加しています。GDPRコンプライアンスに関連する費用は、組織のスケールと複雑さによって20,500米ドルから102,500米ドルの範囲で変動します。データプライバシー規制に違反した場合、重大な法的影響を受ける可能性があります。2023年5月、Facebookの所有者であるMetaは、ヨーロッパのFacebookユーザーのデータをワシントンの諜報機関からの適切な保護措置なしにアメリカに転送したことに関連して、アイルランドのデータ保護委員会から史上最高額の12億米ドルの罰金を科されました。
ラベル付きデータセットは、自律走行車、ドローン、その他のロボットシステムの進展に不可欠であり、ナビゲーション、物体認識、意思決定に必要な情報を提供します。データ収集とラベリングサービスは、オブジェクト認識、ナビゲーション、意思決定能力を向上させるデータセットを提供することで、自律技術の進歩に大いに貢献できます。Waymo、Tesla、Cruiseは、自律走行車技術を積極的に開発しており、正確にラベル付けされたデータセットに大きく依存しています。これらのデータセットは、AIシステムが道路を効果的にナビゲートし、交通標識を解釈し、障害物を特定するためのトレーニングに不可欠です。ガートナーは、2023年までに自律運転ハードウェアを搭載した車両の数が745,705台増加すると予測しています。これは、2018年に記録された137,129台からの大幅な増加です。スタティスタは、2019年の140万台から2030年には5800万台に自律走行車の販売が増加すると予測しています。
さらに、航空測量、農業、インフラ検査、配送サービスに従事する企業は、AIアルゴリズムを搭載したドローンや無人航空機(UAV)を使用して自律飛行とデータ収集を可能にしています。ドローンAIシステムが異なる風景を特定しナビゲートし、特定のオブジェクトを検出するためのトレーニングには、航空画像、地形図、オブジェクト検出用の注釈を含むデータセットが不可欠です。マッキンゼー・アンド・カンパニーの報告によれば、2023年上半期にアジア太平洋地域は世界のドローン配送の43%を占めました。北アメリカのシェアは15%にすぎませんが、これは2022年のシェアと比較して50%の成長を示しています。アフリカは顕著な進展を示し、2023年の初めの6ヶ月で世界のドローン配送の割合が2022年の13%から32%に増加しました。したがって、自律技術の特定のニーズに合わせた優れたラベル付きデータセットを提供することに焦点を当てる企業は、この拡大する市場セグメントから利益を得る有利な位置にあります。
北アメリカは、世界のデータ収集およびラベリング市場の最大のシェアを持ち、予測期間中に23.8%のCAGRで成長すると推定されています。市場は、さまざまなセクターでのAIサービスの採用と、地域の消費者によるスマートデバイスおよびサービスの利用の増加により、重要な機会を提供しています。さらに、この地域での製造操作の大幅な増加は、技術と幅広い製品へのアクセスを向上させ、すべて手頃な価格で提供されます。2022年5月、Sumake North Americaは、自動車、電気、産業ソリューションの信頼性の高い包括的なプロバイダーとして、最新の製品であるEA-SC100ツール管理システムを発表しました。このシステムには、結果の即時視覚化のためのタッチスクリーンインターフェースと、ツールのデータ収集と設定のためのリモート管理システムが含まれています。
アジア太平洋地域は、予測期間中に24.1%のCAGRを示すと予測されています。この成長は、携帯電話やタブレットの採用の増加、データ処理技術の進展、新興市場でのソーシャルネットワーキングプラットフォームの広範な使用に起因しています。知的デバイスの普及は、データ収集と注釈の必要性を高めます。中国のセキュリティと監視システムにおける顔認識技術は、アジア太平洋地域の市場成長を促進すると予測されています。例えば、中国政府は国民がオンラインアカウントを公式の政府IDに接続することを求める実名登録に関する法律を施行しています。2022年4月、ロイターの政府記録の調査により、多くの中国企業が「一人一ファイル」と呼ばれるソフトウェアを開発したことが明らかになりました。このソフトウェアは、監視能力を向上させようとする当局からの高い需要に応じて、個人に関するデータセットをAIを使用して分類します。このシステムはデータ管理を自動化し、人間の介入の必要性を排除することで既存のソフトウェアを強化します。
さらに、2022年1月、韓国のスタートアップAIMMOは、企業が画像、ビデオ、音声、テキスト、センサーフュージョンデータを驚くべき速さと精度で読み取り、分類できるAIデータ注釈プラットフォームを開発しました。同社は、データラベリング技術を強化し、世界展開を促進するために、シリーズAラウンドで1200万米ドルの資金を調達しました。このソフトウェアは、注釈付けに関連する非効率性を排除し、顧客がAIモデルに集中できるようにします。
ヨーロッパ地域市場は、予測期間中に大幅な成長を示すと予測されています。車両障害物検出技術の継続的な進歩により、ヨーロッパの自動車産業は市場の成長を経験すると期待されています。欧州連合は、2022年7月に完全自律走行車の認可に関する法的枠組みの開発を完了しました。2019年に採択された改訂一般安全規制は、2022年7月に発効し、EUにおける自律走行車両の認可に関する法的枠組みを定めています。さらに、2021年にはフランスとドイツが、日常の交通サービスにおける自律走行車の実装に関する包括的な法的枠組みを確立しました。2018年以降、フランスは自動化された接続交通システムを道路に導入する国家計画を積極的に実施しています。ハンブルクは2030年までに約10,000台の自律シャトルを配備する予定です。これらの要因は、予測期間中の市場に影響を与えると予測されています。
画像とビデオデータは、カメラやその他の撮影装置を通じて取得される世界の視覚的な描写です。このセグメントは、データ収集とラベリングにおいて重要であり、コンピュータビジョンモデルのトレーニングの基盤を形成します。注釈付きの画像およびビデオデータセットは、オブジェクト検出、画像認識、顔認識、ビデオ分析アプリケーションの開発を促進します。正確な注釈付けには、画像またはビデオフレーム内のオブジェクト、人物、活動、その他の視覚要素の特定とラベル付けが含まれます。注釈付き画像およびビデオデータセットの品質と多様性は、自律運転やコンテンツ推奨などの幅広いタスクにおけるAIモデルの効力に直接影響します。視覚AIアプリケーションの普及が進む中で、正確にラベル付けされた画像およびビデオデータセットの需要が高まっています。
Report Coverage & Structure
レポートの構造概要
このレポートは、データ収集とラベリング市場の詳細な分析を提供し、様々なセクションに分かれています。以下に、レポートの主な構造を紹介します。
1. 総論
- エグゼクティブサマリー: 市場の概要と重要なポイントを簡潔にまとめたセクション。
- 調査範囲とセグメンテーション: 調査の対象範囲と市場の分類について説明します。
- 調査目的、限界、および仮定: 調査の目的、制約、および仮定についての記述。
- 市場の範囲とセグメンテーション: 市場の範囲と詳細な分類について説明します。
- 通貨と価格設定: 使用される通貨と価格設定の基準について。
2. 市場機会の評価
- 新興地域/国、市場参入企業、アプリケーション/エンドユーズのトレンドを含むマーケット機会の評価。
3. 市場動向
- 市場の推進要因、警告要因、最新のマクロ経済指標、地政学的影響、技術的要因についての分析。
4. 市場評価
- ポーターの5つの力分析とバリューチェーン分析を用いた市場評価。
5. 規制の枠組み
- 北米、ヨーロッパ、APAC、中東とアフリカ、LATAMの各地域における規制の概要。
6. ESGトレンドと市場サイズ分析
- 世界のデータ収集とラベリング市場の規模分析とデータタイプ別、用途別の詳細な市場紹介。
7. 地域別市場分析
- 北米、ヨーロッパ、APAC、中東とアフリカ、LATAMの各地域別に、データタイプとアプリケーション別の市場分析。
- 具体的な国(米国、カナダ、英国、ドイツ、フランス、中国、インド、日本など)の詳細分析を含む。
このレポートは、各セクションで詳細なデータと分析を提供することにより、読者が市場の全体像を把握しやすくすることを目的としています。
*** 本調査レポートに関するお問い合わせ ***

データ収集とラベリングは、機械学習や人工知能(AI)において非常に重要なプロセスです。データ収集は、アルゴリズムを訓練するために必要な情報を集める作業です。これは、インターネット、センサー、データベースなど、さまざまなソースからデータを取得することを指します。一方、データラベリングは、収集したデータに対して意味のあるタグやラベルを付与する作業です。これにより、アルゴリズムがそのデータを理解し、適切に学習することができます。
データ収集の種類には、構造化データと非構造化データがあります。構造化データは、行と列が定義された形式で保存されるデータで、例としてはExcelファイルやSQLデータベースがあります。非構造化データは、テキスト、画像、音声、動画などの形式で保存されるデータで、これには特定の構造がありません。データ収集の方法としては、ウェブスクレイピング、APIを使ったデータ取得、センサーからのデータ収集などがあります。
データラベリングは、特に教師あり学習において重要な役割を果たします。教師あり学習では、モデルがデータを理解するために、入力データとその正しい出力(ラベル)が必要です。ラベリングの方法には、手動ラベリングと自動ラベリングがあります。手動ラベリングは人間がデータに対してラベルを付ける方法で、精度が高いですが時間とコストがかかります。自動ラベリングは、他のアルゴリズムやツールを使用してラベルを付ける方法で、効率的ですが精度が手動ラベリングに劣る場合があります。
データ収集とラベリングの技術は、さまざまな分野で活用されています。たとえば、音声認識システムでは、音声データを収集し、その音声に対応するテキストをラベルとして付けます。画像認識では、画像データを収集し、それぞれの画像に何が写っているかをラベル付けします。これにより、モデルが音声や画像を理解し、適切に分類や認識を行うことが可能になります。
関連する技術としては、クラウドコンピューティングやビッグデータ技術があります。クラウドコンピューティングは、データ収集とラベリングのプロセスを効率化し、大規模なデータを扱うためのリソースを提供します。ビッグデータ技術は、膨大なデータセットを処理し、分析するためのツールや技術を指し、データ収集とラベリングの精度と効率を向上させます。
このように、データ収集とラベリングは、機械学習やAIの成功に欠かせない要素であり、技術の進化に伴い、その重要性はますます高まっています。