抽出・変換・ロード (ETL) 市場規模・シェア分析 - 成長動向と予測 (2025年~2030年)
ETL市場は、コンポーネント(ソフトウェア[ETLツールなど]、サービス[マネージドサービスなど])、導入モデル(オンプレミス、クラウド)、企業規模(中小企業、大企業)、エンドユーザー産業(BFSI、IT・通信、ヘルスケア・ライフサイエンス、小売・Eコマース、製造業など)、および地域によって区分されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
ETL(抽出、変換、ロード)市場の概要
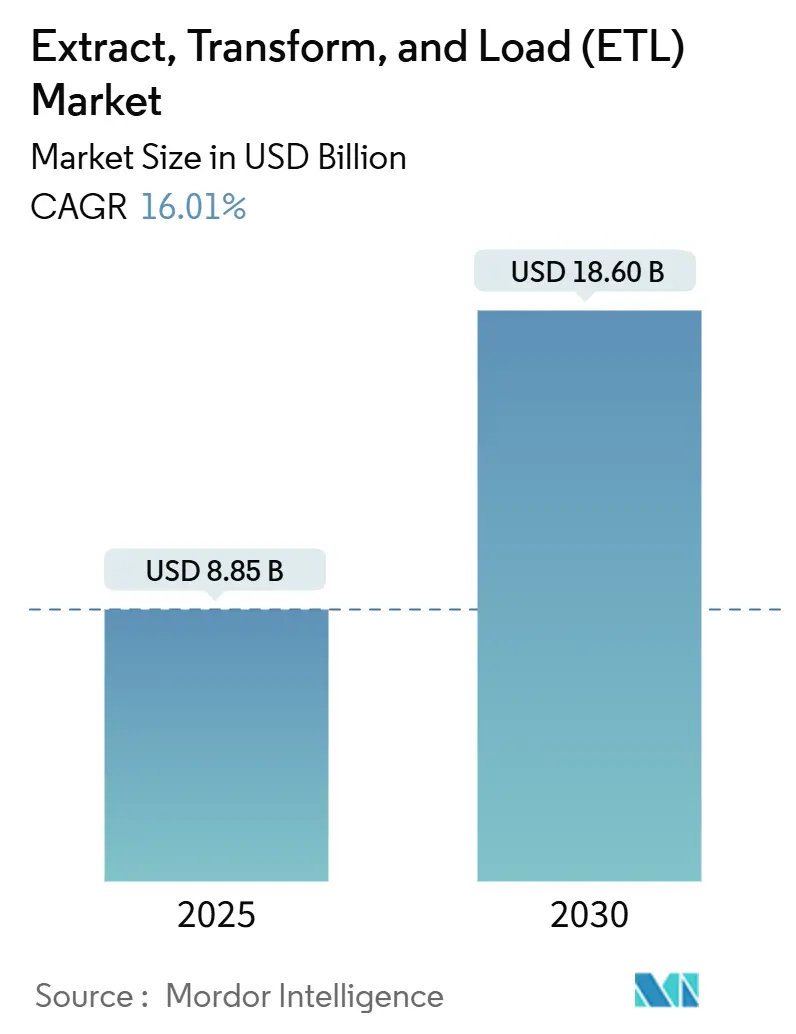
ETL(抽出、変換、ロード)市場は、2025年に88.5億米ドルと評価され、2030年までに186.0億米ドルに達すると予測されており、予測期間中の年平均成長率(CAGR)は16.01%で成長する見込みです。クラウドネイティブアーキテクチャの普及、非構造化データ量の急増、そしてノーコード統合ツールの登場が、市場の顧客基盤を拡大しています。
ソフトウェアコンポーネントは市場において優位性を保っており、企業が統合されたデータ統合スイートに集約する傾向が見られます。また、従量課金制やサーバーレス実行モデルにより、コスト構造は設備投資から運用費用へと移行しています。クラウド展開は、ハイパースケーラーが提供する弾力性のあるコンピューティング、組み込みの変換エンジン、および拡大するデータガバナンスツールキットにより、引き続きインフラ選択の主流となっています。
大企業が依然として収益の基盤を提供していますが、中小企業(SME)はツールの民主化を通じて、市場の増分成長を牽引しています。銀行、保険会社、資本市場の企業が最大の需要源を維持していますが、精密医療や電子健康記録の取り組みが勢いを増すにつれて、ヘルスケアおよびライフサイエンス分野が最も急速に成長する垂直市場となっています。
地域別では、北米が最大の市場であり、アジア太平洋地域が最も速い成長を遂げています。市場の集中度は中程度です。
主要なレポートのポイント
* コンポーネント別: ソフトウェアは2024年にETL市場シェアの71.5%を占め、サービスは2030年までにCAGR 16.7%で拡大すると予測されています。
* 展開モデル別: クラウドソリューションは2024年にETL市場規模の66.8%を占め、2030年までにCAGR 17.7%で成長する見込みです。
* 企業規模別: SMEはCAGR 18.7%で最も速い成長を遂げると予想されており、大企業は2024年に62.7%の収益シェアを維持しました。
* エンドユーザー産業別: BFSI(銀行、金融サービス、保険)が2024年に23.2%の収益でリードし、ヘルスケアおよびライフサイエンスは2030年までにCAGR 17.8%で成長すると予測されています。
* 地域別: 北米が2024年にETL市場規模の39.80%を占め、アジア太平洋地域は2030年までにCAGR 17.30%で成長する見込みです。
グローバルETL市場のトレンドと洞察
市場の牽引要因
1. クラウドネイティブアプリケーションの採用加速:
企業はモノリシックなパイプラインを解体し、マイクロサービスを採用することで、データ処理の各ステップが独立してスケーリングし、障害からの回復が速くなっています。金融機関は、オンプレミスでワークロードを保持していたものの、現在ではセキュアな仮想プライベートクラウド内でサーバーレスETLジョブを試験的に導入しています。Amazon Web Servicesは、Amazon Redshiftに変換機能を直接組み込むことで「ゼロETL」の未来を推進し、取り込みと分析間の遅延を削減しています。消費ベースの課金はコストをデータ処理量に合わせ、Informaticaのクラウド年間経常収益は従量課金制への移行後37%増加しました。データチームがハイパースケーラーへのロックインを避けるため、マルチクラウド互換性も購買決定を左右する要因となっています。
2. 非構造化・半構造化データ量の爆発的増加:
IoTテレメトリー、ソーシャルフィード、ドキュメントリポジトリが、従来のリレーショナルデータセットを凌駕しています。ヘルスケアプロバイダーは、医療画像、ゲノミクス、ウェアラブルテレメトリーを患者の360度記録に統合し、高度な正規化パイプラインを必要としています。データ量が増加するにつれて、多くの企業は専用のETLエンジンではなく、クラウドウェアハウスのコンピューティング能力を活用するELT(抽出、ロード、変換)パターンに移行しています。ベンダーは、プッシュダウンSQL変換、GPUアクセラレーションによる解析、スキーマオンリード機能を提供し、ロード時間を効率化しています。ビデオ、ログ、グラフデータに特化した専門サプライヤーも登場し、汎用プラットフォームはコネクタカタログの拡充を迫られています。
3. ノーコード/ローコードデータ統合ツールの民主化:
視覚的なドラッグ&ドロップキャンバスにより、アナリストはPythonやSQLなしでパイプラインを構築できるようになりました。SMEはこの機能を利用して、不足しているデータエンジニアを回避し、このセグメントがCAGR 18.7%を記録する一因となっています。MatillionやFivetranは、数分で展開できる事前設定済みコネクタを提供し、ユーザー層を拡大しています。階層化されたSKUは、シングルユーザーシートからエンタープライズ無制限ライセンスまであり、参入障壁を低減しています。しかし、ガバナンスチームは、ツールの無制限な普及がリネージ追跡を断片化し、ライセンスコストを膨らませる可能性があると警告しています。
4. Gen-AIによる独自のクリーンルームデータセットの需要:
生成AIプロジェクトには、内部システムから調達されたプライバシー保護されたコーパスが必要です。企業は、モデルトレーニング前に個人識別子をトークン化するためにクリーンルームを構築しています。銀行は、統計的に忠実でありながら匿名化された顧客記録を合成するETLジョブを展開し、金融プライバシー法規への準拠を保護しています。InformaticaのCLAIRE GPTは、自然言語データ品質ルールを組み込み、ポリシー違反をリアルタイムで検出します。この変化は、ETLワークフローに統合されたリネージグラフ作成、マスキング、差分プライバシーアルゴリズムの需要を高めています。
市場の阻害要因
1. ハイパースケーラーのデータ転送費用(Egress Fees)の高騰:
クラウド間のデータ転送は、分析予算の15~25%を消費する可能性があり、アーキテクチャチームはデータが存在する場所でコンピューティングをローカライズせざるを得なくなっています。Databricksは、顧客がコストをほぼリアルタイムで測定し、上限を設定できるServerless Egress Controlで対応しました。多くの組織は現在、ワークロードを単一のクラウド内に統合しており、独立したマルチクラウドETLベンダーの収益機会を縮小させています。
2. データエンジニアリング人材の深刻な不足:
データエンジニアの世界的な需要は、2025年までに200万人から230万人に増加すると予測されていますが、大学やブートキャンプはそのペースに追いつくことができません。人材不足は賃金を高騰させ、プロジェクトの期間を延長するため、企業はルーチンなパイプラインメンテナンスをマネージドサービスプロバイダーにアウトソーシングしています。プラットフォームベンダーは、AI駆動の自動マッピングやテンプレートライブラリを導入し、手動コーディング作業を削減することで、限られたスタッフへの負担を軽減しています。
セグメント分析
1. コンポーネント別: ソフトウェアの統合によるツール複雑性の軽減
ソフトウェアは2024年にETL市場収益の71.5%を占め、2030年までに年間16.7%で成長すると予測されています。組織は、抽出、変換、データ品質、監視をバンドルした統合スイートを好みます。これは、調達を簡素化し、統合リスクを低減するためです。InformaticaのIntelligent Data Management Cloudは、統合されたツールが個別のポイントソリューションの必要性をどのように排除するかを示しています。28.5%を占めるサービスは、複雑な規制対象の展開において依然として重要ですが、セルフサービス自動化の成熟に伴い、成長は鈍化しています。標準化されたソフトウェアワークフローは、リネージとアクセスポリシーを一元化することでガバナンスも向上させます。ベンダーは、SaaS、データベース、イベントストリーム用の事前構築済みコネクタを組み込み、チームがプロジェクトの立ち上げを加速できるようにしています。時間の経過とともに、機能の同等性が基本的な機能をコモディティ化し、AI駆動の最適化やドメイン固有のアクセラレーターへの差別化がシフトする可能性があります。堅牢なパートナーエコシステムと認定プログラムが、決定的な購入要因となるでしょう。
2. 展開モデル別: クラウドがオンプレミスを上回る
クラウド展開は2024年にETL市場規模の66.8%を占め、CAGR 17.7%で最も速い成長を遂げると予測されています。弾力性のあるコンピューティングとサーバーレスジョブは、キャパシティプランニングの課題を解消し、コストを使用量に合わせます。AWS Glueは、ワーカーを自動的にプロビジョニングし、ジョブ完了後にシャットダウンします。オンプレミスインストールは、規制の厳しい業界で機密性の高いワークロードを保護するために依然として利用されていますが、シェアは33.2%に留まっています。データ主権の規則によりローカル処理が必要とされる一方で、分析チームがクラウドの弾力性を求めるため、ハイブリッドパターンが牽引力を増しています。ベンダーは現在、パブリッククラウドとプライベートKubernetesクラスター向けに同一のランタイムを提供しており、顧客は自身のペースで移行できます。長期的な競争力は、環境全体で統一された監視とポリシー適用を提供できるかどうかにかかっています。
3. 企業規模別: SMEの成長が急増
大企業は、複雑なデータ資産と高い平均契約額により、2024年の収益の62.7%を維持しました。しかし、SMEはノーコードインターフェースとサブスクリプション価格設定のおかげで、年間18.7%の成長を遂げ、最も急速に拡大している層です。Fivetranの事前設定済みコネクタにより、小規模企業は数ヶ月ではなく数日でパイプラインを立ち上げることができます。ベンダーは、エントリー障壁を下げるために、限られたコンピューティング時間を含むスターターバンドルをますます提供しています。SMEが成熟するにつれて、きめ細かなガバナンスと高度な変換を提供するエンタープライズティアにアップグレードします。コミュニティフォーラムやマーケットプレイスのテンプレートは、セルフヘルプを促進し、高価なコンサルタントへの依存を減らします。ベンダーにとって、このコホートにおける「ランド・アンド・エクスパンド」戦略は、持続的な収益源を約束します。
4. エンドユーザー産業別: ヘルスケア分野の勢いが増す
BFSIは、日々のリスク計算と規制報告が決定論的なデータリネージを要求するため、2024年の収益の23.2%を占めました。しかし、ヘルスケアおよびライフサイエンスは2030年までに17.8%成長すると予測されており、最も急速に成長する垂直分野となっています。病院は、精密医療プロジェクトのために画像、ゲノミクス、ウェアラブルデータを統合し、ETLインフラストラクチャに大きな負荷をかけています。FHIRなどの相互運用性義務も採用をさらに推進しています。小売、通信、製造業も、エクスペリエンスのパーソナライズと予測メンテナンスを可能にするために支出を増やしています。製造業は、IoTセンサーデータをクラウドウェアハウスにストリーミングして機器の稼働時間を最適化しており、ETL市場が対応すべきユースケースの広範さを示しています。
地域分析
* 北米: 成熟したクラウドエコシステム、厳格なガバナンスフレームワーク、積極的なAI実験により、2024年の世界収益の39.8%を占めました。米国企業は、Amazon RedshiftやSnowflakeへのサーバーレス取り込みを日常的に試験導入しており、カナダは資源セクターの分析プロジェクトにETLを活用しています。メキシコのニアショアリングイニシアチブによる製造業のデジタル化は、ミッドマーケットソリューションへの新たな需要を生み出しています。
* アジア太平洋: 中国のEコマース、インドのITサービス規模、日本と韓国のインダストリー4.0展開に牽引され、CAGR 17.3%で最も速い成長を遂げています。クラウド採用とデジタルスキル訓練に対する政府のインセンティブが導入を加速させています。オーストラリアは鉱業分析に注力し、ASEANの新興市場は信頼性の高いデータ同期を必要とする市民サービスポータルに投資しています。
* ヨーロッパ: GDPR準拠要件に支えられ、着実な拡大を示しています。ドイツの製造業者は、サプライチェーンの可視化のためにリアルタイムETLを展開し、英国の銀行はオープンバンキングフィードを統合しています。フランスとスペインは、通信の解約率削減プログラムにETLを適用しています。
* 中東およびアフリカ: まだ初期段階ですが、サウジアラビアとアラブ首長国連邦がスマートシティ計画に関連する地域パイロットを主導しています。南アフリカの金融セクターも支出を増やしています。これらのダイナミクスがETL市場の地理的な回復力を確保しています。
競争環境
ETL市場は中程度の集中度を維持しています。Informatica、IBM、Microsoft、AWS、Google Cloud、Oracleが主要プレイヤーであり、広範なコネクタライブラリとAIを組み込んだ自動化を活用しています。InformaticaのCLAIREエンジンは、マッピングを提案し、リソース割り当てを最適化することで開発時間を短縮します。一方、ハイパースケーラーはETLをネイティブのウェアハウスサービスに統合し、独立系ベンダーに価格圧力をかけています。
戦略的な取引が市場のポジショニングを再構築しています。Salesforceによる2025年5月のInformatica買収合意は、顧客関係データと深い統合ツールを融合させ、競合他社に分析と統合能力の組み合わせを促す可能性があります。この動きは、特に顧客データ分析の分野において、より包括的なデータ管理ソリューションへの需要を加速させるでしょう。また、他の主要なクラウドプロバイダーやエンタープライズソフトウェアベンダーも、同様の戦略的提携や買収を通じて、自社のデータ統合能力を強化するよう促されるかもしれません。
市場の成長要因
ETL市場の成長は、いくつかの強力な要因によって推進されています。
* データ量の爆発的増加: 企業が生成・収集するデータの量は、構造化データと非構造化データの両方で指数関数的に増加しています。この膨大なデータを活用するためには、効率的なETLプロセスが不可欠です。
* クラウド移行の加速: 多くの組織がオンプレミスシステムからクラウドベースのデータウェアハウスやデータレイクへの移行を進めています。クラウド環境でのデータ統合には、スケーラブルで柔軟なETLソリューションが求められます。
* リアルタイム分析の需要: 意思決定の迅速化に伴い、企業はリアルタイムまたはニアリアルタイムでのデータ分析を求めています。これにより、ストリーミングデータ処理と低レイテンシのETL機能への需要が高まっています。
* AIと機械学習の普及: AIおよび機械学習モデルのトレーニングとデプロイには、高品質で準備されたデータが必要です。ETLツールは、これらのモデルに供給するためのデータをクリーンアップ、変換、統合する上で重要な役割を果たします。
* データガバナンスとコンプライアンス: GDPR、CCPAなどのデータプライバシー規制の強化により、企業はデータの出所、品質、セキュリティを厳密に管理する必要があります。ETLツールは、データリネージの追跡とコンプライアンス要件の遵守を支援します。
市場の課題
成長の機会がある一方で、ETL市場はいくつかの課題にも直面しています。
* 複雑なデータソースとフォーマット: 企業は、リレーショナルデータベース、NoSQLデータベース、SaaSアプリケーション、IoTデバイス、ソーシャルメディアなど、多様なデータソースから様々なフォーマットのデータを扱っています。これらの複雑なデータを統合することは、依然として大きな課題です。
* スキルギャップ: 高度なETLツールやデータ統合プラットフォームを効果的に利用できる専門知識を持つ人材が不足しています。特に、クラウドネイティブなETLソリューションやデータエンジニアリングのスキルは需要が高いです。
* コストとROI: 特に大規模なデータ統合プロジェクトでは、ETLツールの導入、カスタマイズ、メンテナンスには多大なコストがかかることがあります。企業は、これらの投資に対する明確なROIを求める傾向があります。
* データ品質と整合性: 不正確または不完全なデータは、誤った分析結果や意思決定につながる可能性があります。ETLプロセスにおけるデータ品質の確保と整合性の維持は、継続的な課題です。
* ベンダーロックイン: 特定のETLベンダーのソリューションに深く依存することで、将来的な移行や柔軟性が制限される可能性があります。オープンソースソリューションやハイブリッドアプローチへの関心が高まっています。
市場予測
グローバルETL市場は、予測期間中に堅調な成長を続けると予想されます。クラウドベースのETLソリューション、リアルタイムデータ統合、AIを活用した自動化が主要な成長ドライバーとなるでしょう。特に、中小企業におけるデータ活用への意識の高まりと、新興市場におけるデジタル変革の加速が、市場拡大に貢献すると見られます。
地域別では、北米と欧州が引き続き主要な市場シェアを占める一方で、アジア太平洋地域が最も高い成長率を示すと予測されます。これは、中国、インド、日本などの国々におけるデジタルトランスフォーメーションへの投資増加と、データ駆動型ビジネスモデルの採用拡大によるものです。
結論
ETL市場は、データ駆動型経済の基盤として不可欠な役割を担っています。技術革新、特にクラウド、AI、リアルタイム処理の進展により、ETLツールはよりインテリジェントで効率的、かつアクセスしやすいものへと進化しています。競争環境は激化していますが、戦略的な提携や買収を通じて、市場プレイヤーは顧客の複雑なデータ統合ニーズに対応し、持続的な成長を追求していくでしょう。企業がデータから真の価値を引き出すためには、堅牢でスケーラブルなETL戦略の採用がこれまで以上に重要となります。
このレポートは、ETL(Extract, Transform, and Load)市場に関する詳細な分析を提供しています。
1. 市場の定義と範囲
ETL市場は、多様なソースから構造化データや半構造化データを取り込み、ビジネスルールに基づいて変換し、分析や機械学習のためにクリーンなデータセットをターゲットストアにロードするソフトウェアおよびマネージドサービスを指します。本調査の対象外となるのは、スタンドアロンのリバースETLツール、インライン変換を行わない汎用iPaaSスイート、および時間・材料ベースで販売されるプロフェッショナルサービスです。
2. エグゼクティブサマリーと市場規模・成長予測
ETL市場は、2025年に88.5億米ドルの規模に達すると評価されており、2030年までに16.01%の年平均成長率(CAGR)で拡大し、186億米ドルに達すると予測されています。コンポーネント別ではソフトウェアが収益の71.5%を占め、企業が統合プラットフォームを好む傾向が示されています。また、中小企業(SMEs)は、ノーコードツールの普及とサブスクリプション型料金モデルにより、高度なデータ統合機能にアクセスしやすくなったため、最も急速に成長している顧客層です。
3. 市場の推進要因
市場の成長を牽引する主な要因は以下の通りです。
* クラウドネイティブアプリケーションの採用加速
* 非構造化データおよび半構造化データの爆発的な増加
* ノーコード/ローコードデータ統合ツールの普及
* ベンダーの利用ベース課金モデルへの移行
* 持続可能性を重視したデータ資産の合理化
* 生成AI(Gen-AI)が独自の「クリーンルーム」データセットを求める需要
4. 市場の阻害要因
一方で、市場の成長を阻害する要因も存在します。
* ハイパースケーラーのエグレス料金の高騰
* データ主権および居住地に関するコンプライアンスの課題
* データエンジニアリング人材の深刻な不足
* ツール乱立による統合支出の共食い
5. 市場のセグメンテーション
市場は以下の主要なセグメントに分類され、詳細な分析が行われています。
* コンポーネント別: ソフトウェア(ETLツール、ELTおよびストリーミング統合ツール、iPaaS)、サービス(マネージドサービス、プロフェッショナルサービス)
* 展開モデル別: オンプレミス、クラウド
* 企業規模別: 中小企業(SMEs)、大企業
* エンドユーザー産業別: BFSI、IT・通信、ヘルスケア・ライフサイエンス、小売・Eコマース、製造、メディア・エンターテイメント、政府・公共部門、その他
* 地域別: 北米(米国、カナダ、メキシコ)、南米(ブラジル、アルゼンチン、その他)、ヨーロッパ(ドイツ、英国、フランス、イタリア、スペイン、ロシア、その他)、アジア太平洋(中国、日本、インド、韓国、オーストラリア・ニュージーランド、その他)、中東・アフリカ(中東、アフリカ)
6. 競争環境
競争環境は、IBM、Oracle、Microsoft、Informatica、SAP、Talend、Amazon Web Services Inc.、Google Cloud Platform (Alphabet Inc.)、Snowflake Inc.、Salesforce (MuleSoft LLC)など、多数の主要企業によって形成されています。SalesforceによるInformaticaの買収のような戦略的動きは、CRMとデータ統合機能の組み合わせにより、スタンドアロンベンダーに機能強化や提携を促すなど、競争環境に大きな影響を与えると分析されています。
7. 調査方法論と信頼性
本レポートの調査方法は、データエンジニア、最高データ責任者(CDO)、チャネルパートナーへのインタビューやクラウドプラットフォームソリューションアーキテクトへのアンケートといった一次調査と、米国労働統計局、Eurostat、シンガポールIMDA、OECDなどの公開データ、企業財務報告書、税関データ、特許出願情報、ニュースフィードなどの二次調査を組み合わせています。市場規模の算出と予測は、グローバルなエンタープライズソフトウェア支出からETLの浸透率を適用するトップダウンアプローチと、ベンダーの予約データに基づくボトムアップアプローチを併用し、多変量回帰分析を用いて2030年までの収益を予測しています。モデルの出力は四半期ごとに外部の支出トラッカーや契約額、特許出願数と照合され、高い信頼性を確保しています。Mordor Intelligenceのレポートは、厳格なスコープ設定と年次更新により、真のETL活動に焦点を当て、信頼性の高いベースラインを提供している点が強調されています。
8. 市場機会と将来のトレンド
市場には、未開拓の領域や満たされていないニーズが存在し、将来の成長機会を示唆しています。

1. 序論
- 1.1 市場の定義と調査の前提
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
-
4.2 市場の推進要因
- 4.2.1 クラウドネイティブアプリケーション導入の加速
- 4.2.2 非構造化データおよび半構造化データ量の爆発的増加
- 4.2.3 ノーコード/ローコードデータ統合ツールの普及
- 4.2.4 ベンダーの利用ベース課金モデルへの移行
- 4.2.5 持続可能性を重視したデータ資産の合理化
- 4.2.6 独自の「クリーンルーム」データセットに対するGen-AIの需要
-
4.3 市場の阻害要因
- 4.3.1 ハイパースケーラーのデータ転送費用の高騰
- 4.3.2 データ主権および居住地コンプライアンスの課題
- 4.3.3 データエンジニアリング人材の深刻な不足
- 4.3.4 ツール乱立による統合費用のかさみ
- 4.4 主要ステークホルダーへの影響評価
- 4.5 重要な規制枠組みの評価
- 4.6 技術的展望
-
4.7 ポーターの5つの力分析
- 4.7.1 供給者の交渉力
- 4.7.2 消費者の交渉力
- 4.7.3 新規参入の脅威
- 4.7.4 代替品の脅威
- 4.7.5 競争の激しさ
- 4.8 マクロ経済要因の影響
5. 市場規模と成長予測(金額)
-
5.1 コンポーネント別
- 5.1.1 ソフトウェア
- 5.1.1.1 ETLツール
- 5.1.1.2 ELTおよびストリーミング統合ツール
- 5.1.1.3 サービスとしての統合プラットフォーム (iPaaS)
- 5.1.2 サービス
- 5.1.2.1 マネージドサービス
- 5.1.2.2 プロフェッショナルサービス
-
5.2 展開モデル別
- 5.2.1 オンプレミス
- 5.2.2 クラウド
-
5.3 企業規模別
- 5.3.1 中小企業 (SMEs)
- 5.3.2 大企業
-
5.4 エンドユーザー産業別
- 5.4.1 BFSI
- 5.4.2 ITおよび通信
- 5.4.3 ヘルスケアおよびライフサイエンス
- 5.4.4 小売およびEコマース
- 5.4.5 製造業
- 5.4.6 メディアおよびエンターテイメント
- 5.4.7 政府および公共部門
- 5.4.8 その他
-
5.5 地域別
- 5.5.1 北米
- 5.5.1.1 米国
- 5.5.1.2 カナダ
- 5.5.1.3 メキシコ
- 5.5.2 南米
- 5.5.2.1 ブラジル
- 5.5.2.2 アルゼンチン
- 5.5.2.3 その他の南米諸国
- 5.5.3 ヨーロッパ
- 5.5.3.1 ドイツ
- 5.5.3.2 イギリス
- 5.5.3.3 フランス
- 5.5.3.4 イタリア
- 5.5.3.5 スペイン
- 5.5.3.6 ロシア
- 5.5.3.7 その他のヨーロッパ諸国
- 5.5.4 アジア太平洋
- 5.5.4.1 中国
- 5.5.4.2 日本
- 5.5.4.3 インド
- 5.5.4.4 韓国
- 5.5.4.5 オーストラリアおよびニュージーランド
- 5.5.4.6 その他のアジア太平洋諸国
- 5.5.5 中東およびアフリカ
- 5.5.5.1 中東
- 5.5.5.1.1 サウジアラビア
- 5.5.5.1.2 アラブ首長国連邦
- 5.5.5.1.3 トルコ
- 5.5.5.1.4 その他の中東諸国
- 5.5.5.2 アフリカ
- 5.5.5.2.1 南アフリカ
- 5.5.5.2.2 ナイジェリア
- 5.5.5.2.3 ケニア
- 5.5.5.2.4 その他のアフリカ諸国
6. 競合情勢
- 6.1 市場集中度
- 6.2 戦略的動き
- 6.3 市場シェア分析
-
6.4 企業プロファイル(グローバルレベルの概要、市場レベルの概要、主要セグメント、利用可能な財務情報、戦略情報、主要企業の市場ランク/シェア、製品とサービス、および最近の動向を含む)
- 6.4.1 IBMコーポレーション
- 6.4.2 オラクルコーポレーション
- 6.4.3 マイクロソフトコーポレーション
- 6.4.4 インフォマティカLLC
- 6.4.5 SAP SE
- 6.4.6 タレンドS.A.
- 6.4.7 アマゾンウェブサービスInc.
- 6.4.8 Google Cloud Platform (アルファベットInc.)
- 6.4.9 スノーフレイクInc.
- 6.4.10 ファイブトランInc.
- 6.4.11 マティリオンLtd.
- 6.4.12 ヘボデータInc.
- 6.4.13 デノドテクノロジーズInc.
- 6.4.14 クリックテクノロジーズInc.
- 6.4.15 ブーミLP
- 6.4.16 ミュールソフトLLC (セールスフォース)
- 6.4.17 スナップロジックInc.
- 6.4.18 プレサイスリーホールディングスLLC
- 6.4.19 SASインスティチュートInc.
- 6.4.20 アステラソフトウェアコーポレーション
- 6.4.21 日立ヴァンタラLLC
- 6.4.22 アデプティアInc.
7. 市場機会と将来のトレンド
- 7.1 ホワイトスペースと未充足ニーズの評価
*** 本調査レポートに関するお問い合わせ ***

抽出・変換・ロード(ETL)は、データ管理と分析の分野において不可欠なプロセスであり、様々なデータソースから情報を収集し、分析に適した形式に加工し、最終的な保存先へ格納する一連の作業を指します。このプロセスは、ビジネスインテリジェンス(BI)、データウェアハウス(DWH)構築、データ分析、機械学習など、データドリブンな意思決定を支える基盤となります。
まず、ETLの各フェーズについて詳しく見ていきましょう。
「抽出(Extract)」フェーズでは、異なる形式や場所に存在する多様なデータソースから必要なデータを取得します。これらのデータソースには、リレーショナルデータベース(RDB)、NoSQLデータベース、フラットファイル(CSV、XML、JSONなど)、クラウドアプリケーション、SaaS、API、IoTデバイスからのストリーミングデータなどが含まれます。この段階では、データの完全性を保ちつつ、効率的にデータを取得することが重要です。
次に、「変換(Transform)」フェーズは、ETLプロセスの中で最も重要な部分であり、抽出された生データを分析に適した形に加工します。この加工には、データのクレンジング(重複の削除、欠損値の補完、誤ったデータの修正)、標準化(データ形式や単位の統一)、集計(複数のレコードをまとめて要約)、結合(異なるテーブルやソースからのデータを統合)、エンリッチメント(外部データとの結合による情報付加)、ビジネスルールに基づく計算などが含まれます。変換フェーズの目的は、データの品質と一貫性を確保し、ターゲットシステムでの分析やレポート作成を容易にすることです。
最後に、「ロード(Load)」フェーズでは、変換されたデータを最終的なターゲットシステムへ書き込みます。ターゲットシステムは、データウェアハウス、データマート、データレイク、あるいは分析用データベースなど多岐にわたります。ロードの方法には、既存データを完全に置き換える「フルロード」と、新規データや変更されたデータのみを追加・更新する「増分ロード」があります。大規模なデータセットの場合、効率的なロード戦略がシステムのパフォーマンスに大きく影響します。
ETLにはいくつかの種類があり、用途やアーキテクチャによって使い分けられます。
最も伝統的なのは、前述の「抽出→変換→ロード」の順で行われるバッチ処理型のETLです。これは主にデータウェアハウスへの定期的なデータ投入に用いられます。
近年では、「抽出→ロード→変換(ELT)」というアプローチも普及しています。これは、まず生データをデータレイクやクラウドデータウェアハウスにロードし、その後、ターゲットシステムの強力な処理能力を利用して変換を行うものです。ELTは、生データをそのまま保存できるため、将来的な分析ニーズに対応しやすく、また、クラウド環境でのスケーラビリティとコスト効率に優れています。
さらに、リアルタイムまたはストリーミングETLも重要性を増しています。これは、データが生成されると同時に処理・変換・ロードを行い、低遅延で即座に分析可能な状態にするものです。IoTデータ分析、不正検知、パーソナライゼーションなど、即時性が求められるユースケースで活用されます。
また、「リバースETL」という概念も登場しています。これは、データウェアハウスやデータレイクに蓄積された分析済みのデータを、CRMやマーケティングオートメーションツールなどの業務システムにフィードバックし、オペレーションの改善に役立てるものです。
ETLの主な用途は多岐にわたります。
最も代表的なのは、ビジネスインテリジェンス(BI)やデータウェアハウス(DWH)の構築です。ETLによって、企業内の散在するデータを統合し、意思決定のための信頼できる唯一の情報源(Single Source of Truth)を確立します。
また、データ分析や機械学習モデルのトレーニングに必要な高品質なデータセットを準備するためにもETLは不可欠です。データサイエンティストは、ETLによってクリーンで構造化されたデータを得ることで、分析やモデル開発に集中できます。
システム移行や統合の際にも、異なるシステム間のデータ形式を合わせるためにETLが利用されます。マスターデータ管理(MDM)においても、企業全体のマスターデータを統合・標準化し、一貫性を保つ上でETLが中心的な役割を果たします。
さらに、コンプライアンスや規制要件に対応するためのデータ監査やレポート作成においても、ETLはデータのトレーサビリティと正確性を保証するために重要です。
ETLに関連する技術や概念も数多く存在します。
ETLの主要なターゲットである「データウェアハウス」や、生データを格納する「データレイク」、特定の部門や目的に特化した「データマート」は密接に関連しています。
データの品質を維持するための「データ品質管理(DQM)」や、データの利用に関するルールを定める「データガバナンス」は、ETLプロセスと一体となって運用されます。
データの出所から最終的な利用までを追跡する「データリネージ」は、ETLによって構築されるデータパイプラインの透明性を高めます。
近年では、AWS Glue、Azure Data Factory、Google Cloud Dataflowといった「クラウドデータプラットフォーム」がETL/ELTツールとして広く利用されており、スケーラビリティとマネージドサービスを提供しています。
また、物理的なデータ移動を伴わずに複数のデータソースを統合して仮想的なデータビューを提供する「データ仮想化」は、ETLの代替または補完技術として注目されています。
ETLを取り巻く市場背景は、データの爆発的な増加とビジネスにおけるデータ活用の重要性の高まりによって形成されています。
ビッグデータの時代において、企業は日々膨大な量のデータを生成・収集しており、これらの多様なデータを統合し、分析可能な状態にすることは喫緊の課題です。
クラウドコンピューティングの普及は、ETLツールの提供形態にも大きな変化をもたらしました。オンプレミス型からクラウドネイティブなETL/ELTサービスへの移行が進み、より柔軟でスケーラブルなデータ統合が可能になっています。
データドリブン経営の重要性が認識される中で、迅速かつ正確な意思決定を支援するために、高品質なデータをタイムリーに提供するETLの役割はますます大きくなっています。セルフサービスBIツールの普及も、その前提としてETLによるデータ準備が不可欠であることを示しています。
ETLの将来展望としては、いくつかのトレンドが予測されます。
まず、人工知能(AI)や機械学習(ML)の活用がさらに進むでしょう。AI/MLは、データ品質の自動検出・修正、スキーママッピングの自動化、異常検知、ETLパイプラインの最適化などに利用され、ETLプロセスの効率性とインテリジェンスを高めます。
リアルタイム処理の需要は今後も増加し、ストリーミングETL技術はさらに進化するでしょう。これにより、より多くのビジネスユースケースで即時性の高いデータ活用が可能になります。
「データメッシュ」のような分散型データアーキテクチャの台頭は、ETLの設計と運用にも影響を与えます。各ドメインが自身のデータ製品を管理する中で、ETLプロセスもより分散化され、ドメイン固有のニーズに合わせた柔軟なデータパイプラインが求められるようになるでしょう。
ローコード/ノーコードETLツールの普及も進み、専門的な知識を持たないビジネスユーザーでもデータ統合プロセスを構築・管理できるようになることで、データ活用の民主化が加速すると考えられます。
データガバナンスとセキュリティの強化も重要なテーマです。ETLプロセス全体を通じてデータのトレーサビリティ、プライバシー保護、コンプライアンス遵守を保証するための機能がより一層求められるようになります。
このように、ETLは単なるデータ移動の技術に留まらず、データエコシステム全体の進化とともに、その役割と機能を進化させていくことでしょう。