GPUデータベース市場 規模・シェア分析、成長動向と予測 (2025年~2030年)
GPUデータベース市場レポートは、コンポーネント(ソリューション、およびサービス)、デプロイメント(クラウド、およびオンプレミス)、エンドユーザー(BFSI、ITおよび通信、小売およびEコマース、その他)、アプリケーション(リアルタイム分析およびBI、不正検出およびリスク分析、その他)、データモデル(カラムストア、ドキュメント/ベクトル、グラフ、およびマルチモーダル)、および地域別に分類されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
GPUデータベース市場は、複雑なクエリに対して秒以下の結果を返す大規模並列GPUエンジンの採用が加速する中で、急速な成長を遂げています。本レポートは、2019年から2030年までの市場規模、成長予測、主要なトレンド、セグメント別分析、地域別動向、および競争環境について詳細に解説しています。
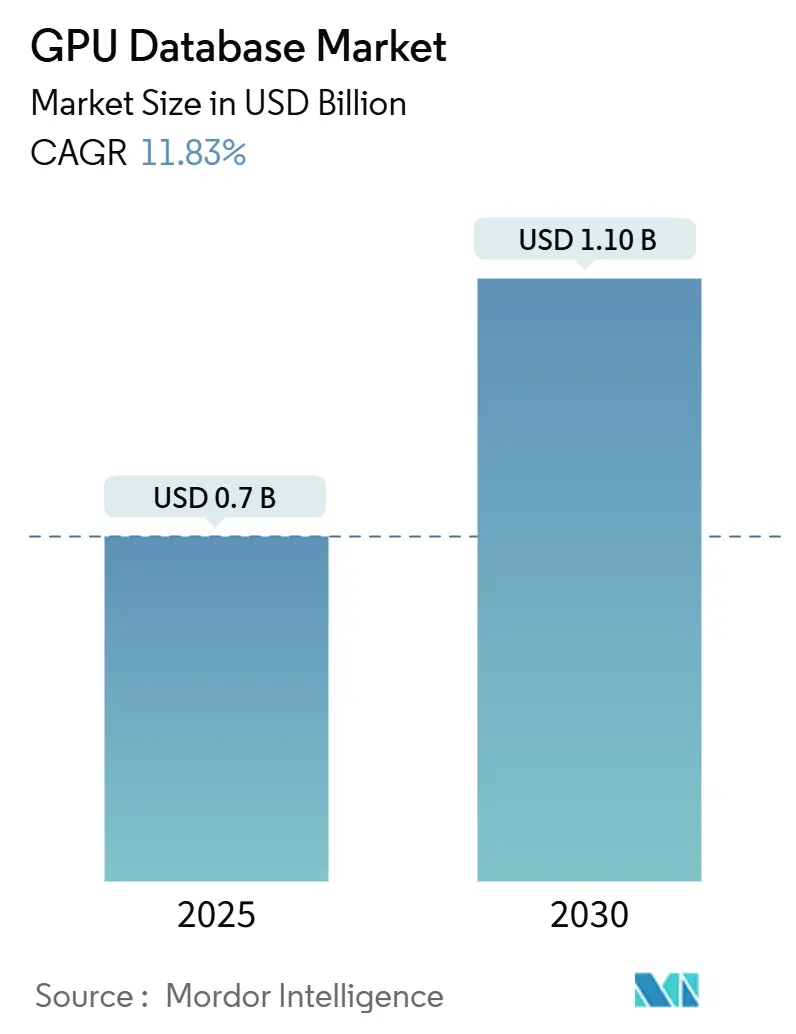
市場規模と成長予測
GPUデータベース市場は、2025年には0.78億米ドルと評価され、2030年までに1.10億米ドルに拡大すると予測されており、予測期間中の年平均成長率(CAGR)は11.83%に達する見込みです。この成長は、企業がCPUに依存した展開から、リアルタイム分析、大規模言語モデル(LLM)推論のためのベクトル検索、およびETL(抽出、変換、ロード)の遅延を解消するハイブリッドトランザクション/分析ワークロード(HTAP)をサポートするために、GPUプラットフォームへ移行していることに起因しています。
地域別では、北米が最大の市場であり、アジア太平洋地域が最も急速に成長すると予測されています。市場の集中度は中程度であり、主要プレイヤーとしてはHeavy.AI (OmniSci)、Kinetica DB Inc.、SQream Technologies、NVIDIA、Brytlyt Ltd.などが挙げられます。
主要な市場動向と洞察
成長要因 (Drivers):
* リアルタイム分析の需要増加(CAGRへの影響 +3.2%): 金融機関は、不正検出や顧客向けアプリケーションのパーソナライズのために、ミリ秒単位での継続的な分析を求めています。GPUデータベースは、時系列データストリームを並列処理し、CPUシステムでは順次処理される数百万の同時集計を実行することで、この需要に応えています。
* AI/MLワークロードの普及(CAGRへの影響 +4.1%): DatabricksがCUDAライブラリを統合しているように、共同配置されたストレージとコンピューティングは、生成AIパイプラインのデータ移動オーバーヘッドを排除します。ヘルスケア分野では、医療画像のトリアージにベクトル埋め込みが利用され、GPUの数千のコアがモデル推論を支配する行列演算に最適化されています。
* LLM推論の爆発的成長とベクトル検索DBの採用(CAGRへの影響 +2.8%): Eコマース企業は、製品とユーザーの意図をマッチングさせるためにベクトルデータベースを展開しています。GPUの並列処理は、セマンティック検索のレイテンシをインタラクティブな閾値内に保ち、RAG(Retrieval-Augmented Generation)アーキテクチャがリアルタイムのパーソナライズされたブラウジングセッションを可能にしています。
* GPU上での分析処理とトランザクション処理の融合 (HTAP)(CAGRへの影響 +1.9%): GPUクラスターは、ACID準拠の書き込みと分析結合を同時に実行し、OLTP(オンライン・トランザクション処理)とOLAP(オンライン・分析処理)の歴史的な分離を解消しています。これにより、リアルタイムの在庫スナップショットに基づく価格調整や、ライブテレマティクスを使用したフリートの再ルーティングが可能になります。
* オープンソースGPU SQLエンジンの成熟(CAGRへの影響 +1.3%): Apache Glutenのようなオープンソースプロジェクトは、SparkSQLの速度を大幅に向上させ、ライセンス費用を削減し、コストに敏感なユーザーの間での採用を拡大しています。
* エッジクラウドGPUマーケットプレイスの参入障壁低下(CAGRへの影響 +0.9%): アジア太平洋地域を中心に、エッジクラウドGPUマーケットプレイスが参入障壁を下げ、GPUアクセラレーターへのアクセスを容易にしています。
阻害要因 (Restraints):
* 高い導入コストと統合の複雑さ(CAGRへの影響 -2.7%): NVIDIA H100のような高性能GPUは高価であり、エンタープライズ展開には多数のユニットとInfiniBandファブリックが必要です。また、DBA(データベース管理者)はCUDAカーネルのチューニングに習熟するための学習曲線が急峻です。
* CUDA/OpenCLデータベース人材の不足(CAGRへの影響 -1.8%): リレーショナル最適化とGPUスレッドスケジューリングの両方を理解するエンジニアの需要は供給を大幅に上回っており、特にアジア太平洋地域ではシニアポジションの採用に数ヶ月の遅延が生じています。
* GPUサプライチェーンの変動とAIトレーニングクラスターへの割り当て(CAGRへの影響 -1.4%): GPUの供給チェーンは不安定であり、AIトレーニングクラスターへの優先的な割り当てが、他の用途でのGPUデータベース展開に影響を与える可能性があります。
* 永続的なGPUメモリ管理の標準化の未熟さ(CAGRへの影響 -0.9%): 永続的なGPUメモリ管理に関する標準がまだ成熟していないことも、市場の成長を阻害する要因の一つです。
セグメント別分析
* コンポーネント別:
* ソリューションが2024年にGPUデータベース市場シェアの68.5%を占め、収益を牽引しました。これは、CUDAコアに最適化された既製のSQL、ベクトル、グラフエンジンが企業に好まれているためです。このセグメントは2030年までに36.7%のCAGRで成長すると予測されています。
* サービスは残りのシェアを占めますが、統合の複雑さに直面する企業が増えるにつれて、同等の成長を記録しています。GPUスキーマ設計、メモリ最適化、インデックスパーティショニングにはコンサルティングが必要であり、システムインテグレーターは移行ロードマップ、CUDAトレーニング、24時間365日のパフォーマンス監視を提供しています。
* 展開モデル別:
* クラウド展開は2024年にGPUデータベース市場規模の78.3%を占め、ハイパースケーラーの投資により、時間単位で数百のH100ユニットを即座にプロビジョニングできることが反映されています。このモデルは2030年までに年間34.3%で成長すると予測されています。
* ハイブリッドパターンも出現しており、企業はクラウドトレーニングとエッジ推論を組み合わせて、レイテンシとデータ主権のリスクを低減しています。
* エンドユーザー産業別:
* BFSI(銀行、金融サービス、保険)が2024年にGPUデータベース市場シェアの25.3%を占め、マイクロ秒単位の取引マッチングやバーゼルIIIの流動性計算にストリーミング分析を利用しています。
* ヘルスケア・ライフサイエンスは、放射線医学、ゲノミクス、創薬ワークフローがGPUネイティブのデータストアに移行するにつれて、29.5%のCAGRで最も急速な拡大を遂げています。
* アプリケーション別:
* リアルタイム分析が2024年にGPUデータベース市場規模の30.2%を占め、IoTテレメトリやクリックストリームデータのための迅速なダッシュボードや異常アラートを優先しています。
* 不正検出・リスク分析は2030年までに32.8%のCAGRで成長し、グラフトラバーサルとベクトル類似性を活用して、疑わしいパターンをリアルタイムで特定します。
* データモデル別:
* カラムストアエンジンは、カラム型圧縮とスキャンに適したレイアウトがGPUメモリ帯域幅に効率的にマッピングされるため、2024年にGPUデータベース市場シェアの44.7%を維持しました。
* ベクトル/ドキュメントデータベースは、LLM展開に牽引され、40.6%のCAGRで最も急激な上昇を記録しています。Milvus、Qdrant、Weaviateなどのデータベースは、セマンティック検索のために数十億の768次元埋め込みをインデックス化しています。
地域別分析
* 北米は、ハイパースケーラーの強力な存在感と、金融サービスおよびヘルスケア分野でのGPUデータベースの早期導入により、2024年にGPUデータベース市場の38.5%を占めました。この地域は、AI/ML研究開発への多額の投資と、データ集約型アプリケーションの需要の高まりによって牽引されています。
* アジア太平洋地域は、中国とインドにおけるデジタル変革イニシアチブとクラウドインフラストラクチャの急速な拡大に牽引され、2030年までに35.1%のCAGRで最も急成長する地域として浮上しています。製造業やeコマースにおけるリアルタイム分析の需要が、この成長をさらに後押ししています。
主要な市場プレーヤー
GPUデータベース市場の主要プレーヤーには、Kinetica、OmniSci (現在はHEAVY.AI)、SQream、BlazingSQL (現在はDatabricksの一部)、Brytlyt、Neo4j、NVIDIA、IBM、Oracle、Microsoft、Google、Amazon Web Services (AWS) などがあります。これらの企業は、市場シェアを拡大するために、戦略的パートナーシップ、製品革新、M&Aに注力しています。例えば、NVIDIAは、GPUアクセラレーションをデータ分析ワークフローに統合するために、主要なデータベースベンダーと協力しています。
結論
GPUデータベース市場は、AI、機械学習、リアルタイム分析の需要の高まりにより、大幅な成長を遂げる準備ができています。技術の進歩と、さまざまな業界での採用の増加により、GPUデータベースは、データ集約型アプリケーションのパフォーマンスとスケーラビリティを向上させる上で重要な役割を果たすでしょう。
本レポートは、GPUデータベース市場に関する包括的な調査結果をまとめたものです。GPUデータベースは、グラフィックス処理ユニット(GPU)上でデータベースワークロードを実行し、構造化、半構造化、およびベクトルデータに対して超並列リアルタイム分析を提供するライセンスソフトウェアおよび関連マネージドサービスと定義されています。ベアメタルGPUサーバー、CPU中心のデータベース、グラフィックレンダリングのみに使用されるアクセラレーターは本調査の対象外です。
市場は急速な成長を遂げており、2025年には0.78億米ドルの市場規模に達し、2030年までには1.10億米ドルに成長すると予測されています。この成長を牽引する主要な要因としては、リアルタイム分析に対する需要の増加、GPUアクセラレーションを必要とするAI/MLワークロードの普及、LLM(大規模言語モデル)推論の爆発的な成長によるベクトル検索データベースの採用拡大が挙げられます。また、GPU上での分析処理とトランザクション処理(HTAP)の融合、オープンソースGPU SQLエンジンの成熟、エッジクラウドGPUマーケットプレイスによる参入障壁の低下も市場拡大に寄与しています。HTAPはETL(抽出、変換、ロード)の遅延を解消し、GPUをリアルタイム意思決定のための中心的なプラットフォームとして位置づけることで、GPUデータベースの需要を促進しています。
一方で、市場の成長を阻害する要因も存在します。高い実装コストと統合の複雑性、CUDAやOpenCLデータベースの熟練人材の不足は、特に新興市場での導入を遅らせる要因となっています。さらに、GPUサプライチェーンの不安定性やAIトレーニングクラスターへのGPU割り当て、永続GPUメモリ管理に関する標準の未熟さも課題として挙げられます。
市場は様々なセグメントにわたって分析されています。コンポーネント別では、GPU SQLエンジン、GPUベクトルデータベース、GPUグラフデータベースなどのソリューションと、関連サービスに分類されます。デプロイメントモデル別では、クラウドデプロイメントが圧倒的に優勢であり、2024年には収益シェアの78.3%を占めています。これは、ハイパースケーラーによるGPUの利用可能性と従量課金制の柔軟性によるものです。
エンドユーザー産業別では、ヘルスケア・ライフサイエンス分野が最も急速に成長しており、GPUアクセラレーションによる診断画像処理やゲノミクスワークロードの需要が高まることで、29.5%のCAGR(年平均成長率)を示すと予測されています。その他、BFSI(銀行・金融サービス・保険)、IT・通信、小売・Eコマース、政府・防衛などの産業も主要なエンドユーザーです。
アプリケーション別では、リアルタイム分析とビジネスインテリジェンス(BI)、不正検知とリスク分析、地理空間およびIoT分析、レコメンデーションとパーソナライゼーション、インフラ監視とログ分析などが主要な用途として挙げられます。データモデル別では、ベクトル/ドキュメントデータベースがLLM推論やセマンティック検索における高次元類似性クエリの効率的な処理能力により、40.6%のCAGRで急速に成長しています。カラムストア、グラフ、マルチモデルも重要なデータモデルです。
地域別では、北米、南米、欧州、中東・アフリカ、アジア太平洋の主要地域で市場が分析されており、各地域の市場規模と成長予測が詳細に示されています。
競合環境においては、Advanced Micro Devices (AMD)、Intel Corporation、IBM Corporation、Oracle Corporation、Google LLC、Amazon Web Services (AWS)、Microsoft Corporation、Hewlett Packard Enterprise (HPE)といった大手テクノロジー企業に加え、Heavy.AI (OmniSci)、Kinetica DB Inc.、SQream Technologies、Zilliz (Milvus)などの専門ベンダーが市場に参入しています。レポートでは、市場集中度、主要企業の戦略的動き、市場シェア分析、製品・サービス、および最近の動向が詳細に記述されています。
本レポートの調査方法は、クラウドアーキテクトやデータエンジニアへの一次調査、UN Comtrade、OECD Digital Economy Outlook、Eurostatなどの公開データ、Questelからの特許情報、企業報告書を用いたデスク調査を組み合わせています。市場規模の算出と予測は、GPU出荷数、アクティブなベクトル検索インスタンス、リアルタイム分析クエリの成長、クラウドGPU時間、企業AI導入などの変数に基づいた多変量回帰分析によって行われています。Mordor Intelligenceの調査は、検証済みの出荷データと現在のユーザーからのライセンス比率のクロスチェックにより、信頼性と透明性を確保しており、意思決定者が求めるバランスの取れた透明なベースラインを提供しています。
将来の展望としては、未開拓の領域や満たされていないニーズの評価を通じて、さらなる市場機会が特定されています。特に、ベクトルデータベースの急速な成長とヘルスケア・ライフサイエンス分野の拡大は、今後の市場を牽引する重要なトレンドとなるでしょう。

1. はじめに
- 1.1 調査の前提と市場の定義
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
- 4.2 市場の推進要因
- 4.2.1 リアルタイム分析の需要の高まり
- 4.2.2 GPUアクセラレーションを必要とするAI/MLワークロードの普及
- 4.2.3 LLM推論の爆発的な成長によるベクトル検索DBの採用促進)
- 4.2.4 GPU上での分析処理とトランザクション処理(HTAP)の融合)
- 4.2.5 オープンソースGPU SQLエンジンの成熟
- 4.2.6 エッジクラウドGPUマーケットプレイスによる参入障壁の低下)
- 4.3 市場の阻害要因
- 4.3.1 高い導入コストと統合の複雑さ
- 4.3.2 熟練したCUDA / OpenCLデータベース人材の不足)
- 4.3.3 GPUサプライチェーンの変動性とAIトレーニングクラスターへの割り当て
- 4.3.4 永続的なGPUメモリ管理のための未熟な標準)
- 4.4 重要な規制枠組みの評価
- 4.5 技術的展望
- 4.6 ポーターの5つの力
- 4.6.1 供給者の交渉力
- 4.6.2 買い手の交渉力
- 4.6.3 新規参入の脅威
- 4.6.4 代替品の脅威
- 4.6.5 競争上の対立
- 4.7 主要な利害関係者への影響評価
- 4.8 主要なユースケースとケーススタディ
- 4.9 市場のマクロ経済要因への影響
- 4.10 投資分析
5. 市場規模と成長予測(金額)
- 5.1 コンポーネント別
- 5.1.1 ソリューション
- 5.1.1.1 GPU SQLエンジン
- 5.1.1.2 GPUベクターデータベース
- 5.1.1.3 GPUグラフデータベース
- 5.1.1.4 その他
- 5.1.2 サービス
- 5.2.1 クラウド
- 5.2.2 オンプレミス
- 5.3.1 BFSI
- 5.3.2 ITおよび通信
- 5.3.3 小売およびEコマース
- 5.3.4 ヘルスケアおよびライフサイエンス
- 5.3.5 政府および防衛
- 5.3.6 その他の産業
- 5.4.1 リアルタイム分析およびBI
- 5.4.2 不正検出およびリスク分析
- 5.4.3 地理空間およびIoT分析
- 5.4.4 レコメンデーションおよびパーソナライゼーション
- 5.4.5 インフラ監視およびログ分析
- 5.5.1 カラムストア
- 5.5.2 ドキュメント/ベクター
- 5.5.3 グラフ
- 5.5.4 マルチモデル
- 5.6.1 北米
- 5.6.1.1 米国
- 5.6.1.2 カナダ
- 5.6.1.3 メキシコ
- 5.6.2 南米
- 5.6.2.1 ブラジル
- 5.6.2.2 アルゼンチン
- 5.6.2.3 その他の南米諸国
- 5.6.3 ヨーロッパ
- 5.6.3.1 イギリス
- 5.6.3.2 ドイツ
- 5.6.3.3 フランス
- 5.6.3.4 イタリア
- 5.6.3.5 スペイン
- 5.6.3.6 北欧諸国
- 5.6.3.7 その他のヨーロッパ諸国
- 5.6.4 中東およびアフリカ
- 5.6.4.1 中東
- 5.6.4.1.1 サウジアラビア
- 5.6.4.1.2 アラブ首長国連邦
- 5.6.4.1.3 トルコ
- 5.6.4.1.4 その他の中東諸国
- 5.6.4.2 アフリカ
- 5.6.4.2.1 南アフリカ
- 5.6.4.2.2 エジプト
- 5.6.4.2.3 ナイジェリア
- 5.6.4.2.4 その他のアフリカ諸国
6. 競合情勢
- 6.1 市場集中度
- 6.2 戦略的動向
- 6.3 市場シェア分析
- 6.4 企業プロファイル(グローバルレベルの概要、市場レベルの概要、主要セグメント、利用可能な財務情報、戦略情報、主要企業の市場ランク/シェア、製品とサービス、および最近の動向を含む)
- 6.4.1 アドバンスト・マイクロ・デバイセズ社 (AMD)
- 6.4.2 インテル コーポレーション
- 6.4.3 IBM コーポレーション
- 6.4.4 オラクル コーポレーション
- 6.4.5 グーグル合同会社
- 6.4.6 アマゾン ウェブ サービスズ社
- 6.4.7 マイクロソフト コーポレーション
- 6.4.8 ヒューレット・パッカード・エンタープライズ社
- 6.4.9 SASインスティチュート社
- 6.4.10 Heavy.AI (OmniSci)
- 6.4.11 キネティカDB社
- 6.4.12 SQreamテクノロジーズ
- 6.4.13 ブライトライト社
- 6.4.14 Zilliz (Milvus)
- 6.4.15 ブレイジングSQL
- 6.4.16 HeteroDB/PG-Strom
- 6.4.17 MapDテクノロジーズ (レガシー)
- 6.4.18 スターロックス
- 6.4.19 テラデータ コーポレーション
- 6.4.20 三菱重工業 (スペースジェット構想)
7. 市場機会と将来展望
*** 本調査レポートに関するお問い合わせ ***

GPUデータベースとは、グラフィックス処理ユニット(GPU)の持つ並列計算能力を最大限に活用し、大量のデータを高速に処理・分析するために設計されたデータベースシステムを指します。従来のデータベースシステムが主に中央処理装置(CPU)の逐次処理能力に依存していたのに対し、GPUデータベースは数千ものコアを持つGPUの並列処理アーキテクチャを利用することで、特に分析クエリや複雑な計算において圧倒的なパフォーマンスを発揮します。これは、データウェアハウス、データレイク、リアルタイム分析といった分野で、CPUベースのシステムでは処理に時間がかかりすぎるような大規模なデータセットや複雑なクエリに対して、劇的な速度向上をもたらす可能性を秘めています。
GPUデータベースにはいくつかの種類が存在します。一つは、データをGPUのメモリ上に完全にロードして処理を行う「インメモリGPUデータベース」です。これは最も高速な処理を実現しますが、GPUメモリの容量に制約されるため、扱えるデータ量に限界があります。もう一つは、データの一部をディスクやメインメモリに保持し、必要な部分だけをGPUに転送して処理する「ディスクベースGPUデータベース」や「ハイブリッド型」です。これにより、より大規模なデータセットを扱うことが可能になりますが、データ転送のオーバーヘッドが発生する可能性があります。さらに、既存のデータベースシステムにGPUアクセラレーション機能を追加する「GPUアクセラレーション型データベース」と、最初からGPUでの処理を前提に設計された「GPUネイティブ型データベース」という分類もできます。GPUネイティブ型は、データ構造やクエリ実行エンジンがGPUの特性に合わせて最適化されており、最高のパフォーマンスを引き出すことを目指しています。
GPUデータベースの主な用途は多岐にわたります。最も顕著なのは、金融取引におけるリアルタイム不正検知やリスク分析、IoTデバイスから生成される膨大なセンサーデータの即時分析など、高速な意思決定が求められる「リアルタイム分析」の分野です。また、数テラバイトからペタバイト規模のデータセットに対して複雑な集計や結合を行う「ビッグデータ分析」においても、その並列処理能力が威力を発揮します。データサイエンスや機械学習の分野では、モデル学習の前段階で行われる特徴量エンジニアリングやデータの前処理において、GPUデータベースが計算時間を大幅に短縮し、データサイエンティストの生産性向上に貢献します。その他、地理空間情報システム(GIS)における位置情報データの高速処理、科学技術計算におけるシミュレーション結果の分析、大規模データのインタラクティブな可視化など、幅広い分野での応用が期待されています。
関連技術としては、まずGPUプログラミングモデルである「CUDA(Compute Unified Device Architecture)」や「OpenCL」が挙げられます。これらはGPU上で汎用計算を実行するための基盤となります。NVIDIAが提供する「RAPIDS」は、データサイエンスワークフローをGPU上で高速化するためのライブラリ群であり、特にcuDF(GPU版Pandas)やcuML(GPU版Scikit-learn)などがGPUデータベースと密接に連携します。また、「Apache Arrow」のようなインメモリカラムナーデータフォーマットは、CPUとGPU間でのデータ転送効率を高め、異なるシステム間でのデータ共有を容易にします。GPU間の高速インターコネクト技術である「NVLink」や「PCIe」も、複数のGPUを連携させて大規模なデータ処理を行う上で不可欠です。さらに、DaskやSparkといった分散処理フレームワークも、GPUアクセラレーションをサポートすることで、GPUデータベースの能力をさらに拡張しています。多くのGPUデータベースは、分析クエリに最適な「カラムナー型データベース」の特性と、「インメモリデータベース」の高速性を兼ね備えています。
GPUデータベースが注目される市場背景には、いくつかの要因があります。第一に、インターネットの普及とIoTデバイスの増加により、データ量が爆発的に増大していることです。このビッグデータ時代において、従来のCPUベースのシステムでは処理が追いつかないケースが増えています。第二に、ビジネスにおけるリアルタイム分析の需要が高まっていることです。迅速な意思決定のためには、データを即座に分析し、洞察を得る必要があります。第三に、AIや機械学習の普及に伴い、モデル学習の前段階でのデータ前処理の重要性が増していることです。GPUデータベースは、この前処理を高速化し、AI開発のサイクルを短縮します。第四に、GPU自体の性能向上とコスト効率の改善です。汎用計算能力が飛躍的に向上し、クラウド環境でのGPUインスタンスの利用が容易になったことも、GPUデータベースの普及を後押ししています。
将来展望として、GPUデータベースはさらなる進化を遂げると予想されます。GPU技術の継続的な発展により、処理性能は向上し、コストはさらに低下するでしょう。これにより、より多くの企業や研究機関がGPUデータベースを導入しやすくなります。また、RAPIDSのようなエコシステムが成熟し、より多くのツール、ライブラリ、フレームワークが提供されることで、開発者やデータサイエンティストはGPUデータベースをより容易に活用できるようになります。ハイブリッドクラウドやマルチクラウド環境への対応も進み、柔軟なデプロイメントと運用が可能になるでしょう。AIとの融合も加速し、データベース内部でAIモデルの推論や学習を直接実行するような機能が強化される可能性があります。エッジコンピューティングの分野でも、エッジデバイス上でのリアルタイム分析のためにGPUデータベースが活用されるケースが増えるかもしれません。標準化の動きも進み、異なるGPUデータベース間での相互運用性が向上することも期待されます。これらの進化は、データ駆動型社会のさらなる発展に不可欠な要素となるでしょう。