インフィニバンド市場 規模・シェア分析 – 成長動向と予測 (2025年~2030年)
InfiniBand市場レポートは、コンポーネント(ホストチャネルアダプター[HCA]、スイッチ、ケーブルおよびトランシーバーなど)、データレート(SDR/DDR、QDR/FDR、EDRなど)、アプリケーション(ハイパフォーマンスコンピューティング、AI/MLトレーニングおよび推論など)、展開モデル(オンプレミスクラスター、クラウド/ホスト型HPC)、エンドユーザー産業(政府および防衛、学術機関および研究機関、BFSIなど)、および地域別に分類されています。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
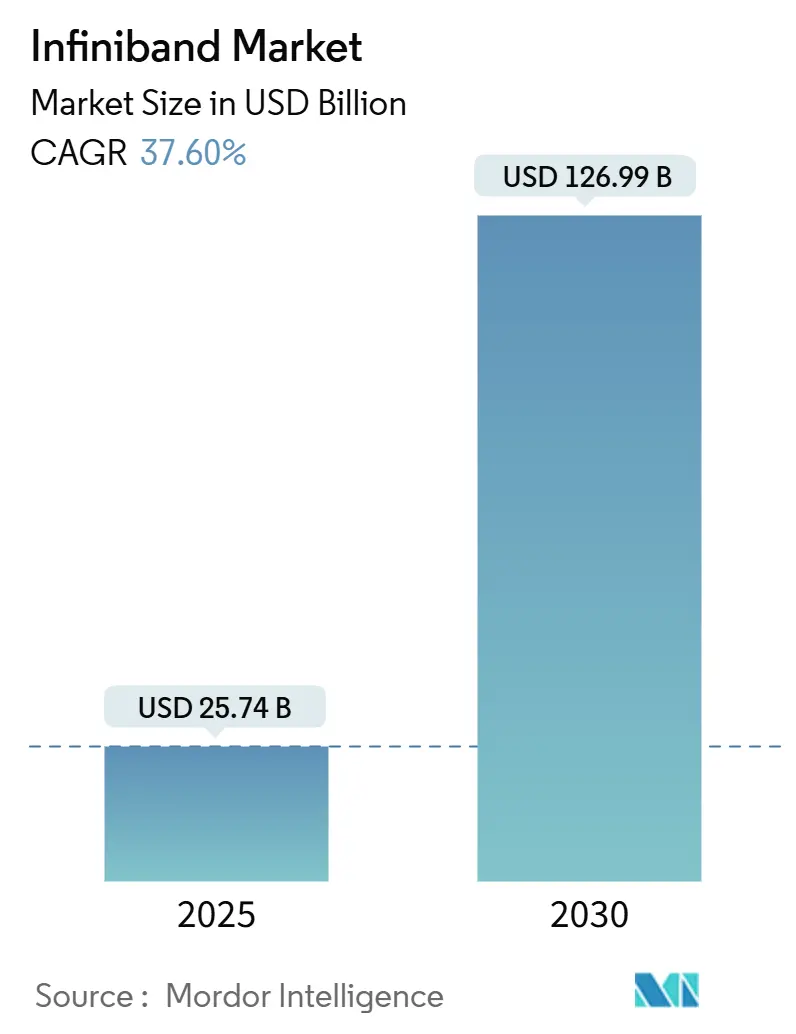
インフィニバンド市場は、2025年には257.4億米ドルと推定され、2030年までに1269.9億米ドルに達すると予測されており、予測期間(2025年~2030年)中の年平均成長率(CAGR)は37.60%に上ると見込まれています。この市場の成長は、ハイパースケールAIトレーニングクラスター、国家エクサスケールプログラム、および低遅延が求められる金融アプリケーションにおいて、イーサネットでは対応が難しい決定論的でロスレスなファブリックへの依存が高まっていることに起因しています。
現在の200 Gb/s HDRリンクから800 Gb/s XDR、そして1.6 Tb/s NDR 200への継続的な帯域幅の飛躍は、約18ヶ月ごとにGPU間トラフィックが倍増する大規模言語モデル(LLM)の複雑さにインフィニバンド市場がしっかりと対応していることを示しています。クラウドプラットフォームは、Quantum-2およびQuantum-X800スイッチをGPUスーパーポッドの「リファレンスバックボーン」として標準化しており、企業はスーパーコンピュータークラスのネットワーキングに即座にアクセスできるようになっています。短期的には、光トランシーバーおよびダイレクトアタッチ銅(DAC)ケーブルのサプライチェーンの逼迫がコスト上昇圧力となっていますが、2026年以降はシリコンフォトニクス統合により、ベンダーがコパッケージングソリューションを導入し、コストを削減し、パフォーマンスを向上させることが期待されています。この技術革新は、特に大規模なAIインフラストラクチャにおいて、より高密度でエネルギー効率の高いネットワーキングソリューションを実現し、InfiniBandの優位性をさらに強化するでしょう。長期的には、InfiniBandは、AI、HPC、およびデータ集約型アプリケーションの進化に伴い、その決定論的でロスレスな特性が不可欠となる分野で、引き続き主要な役割を果たすと見られています。市場の成長は、新たな技術の採用と、より複雑なワークロードへの対応能力によって、今後も加速していくことでしょう。
本レポートは、InfiniBand市場に関する包括的な分析を提供し、その市場定義、成長要因、抑制要因、セグメンテーション、競争環境、および将来展望を詳細に解説しています。
市場定義と調査範囲
Mordor Intelligenceの調査によると、InfiniBand市場は、高性能コンピューティング(HPC)およびAIデータセンタークラスター内で標準ベースの低遅延ファブリックを形成する、ホストチャネルアダプター(HCA)、専用スイッチ、認定された銅線または光ケーブル、および管理ソフトウェアから得られるすべての収益を対象としています。受動的な光ファイバー、イーサネットシリコン、およびサービスから引退したレガシーSDR機器は、調査対象から除外されています。
市場規模と成長予測
InfiniBand市場は、今後数年間で著しい成長を遂げると予測されています。2025年には市場規模が257.4億ドルに達し、2030年までには1269.9億ドルに拡大すると見込まれており、予測期間中の年平均成長率(CAGR)は37.60%という高い成長率が予測されています。
市場の主要な促進要因
市場の成長を後押しする主な要因は以下の通りです。
* AI/LLMクラスター導入の爆発的増加: 大規模なAIモデルや大規模言語モデル(LLM)のトレーニングと推論には、膨大なデータ処理能力と極めて低い通信遅延が不可欠であり、InfiniBandがその要件を満たしています。
* 国家エクサスケールHPCプログラムの普及: 世界各国でエクサスケールHPCシステムの開発が進められており、これらのシステムには高性能なInfiniBandファブリックが採用されています。
* InfiniBandを標準とするクラウドGPUスーパーポッド: 主要なクラウドサービスプロバイダーは、GPUスーパーポッドにおいてInfiniBandを標準的な相互接続技術として採用し、高性能なAI/MLワークロードをサポートしています。
* 低遅延金融分析への需要増加: 金融サービス分野における高頻度取引(HFT)やリアルタイム分析では、ミリ秒以下の遅延が求められ、InfiniBandが優位性を示しています。
* 国内相互接続製造への政府奨励金: 各国政府は、サプライチェーンの強靭化と技術的自立を目指し、国内での相互接続技術製造を奨励しています。
* 1.6 Tb/s (NDR200)ファブリックへのロードマップの飛躍: InfiniBand技術は、1.6 Tb/s (NDR200)といった次世代の高速ファブリックへのロードマップを明確に示しており、将来的な性能向上への期待が高まっています。
市場の主要な抑制要因
一方で、市場の成長を阻害する可能性のある要因も存在します。
* 高い設備投資と導入の複雑さ: InfiniBandシステムの導入には高額な初期投資(Capex)が必要であり、また専門的な知識と複雑な設定が求められるため、イーサネットと比較して30-50%のコスト増となる場合があり、特に中小企業にとっては導入の大きな障壁となっています。
* 800 G/1.6 T Ultra-Ethernetの急速な性能向上: BroadcomやArista Networksなどが主導するUltra-Ethernetの取り組みにより、イーサネットの性能が急速に向上し、InfiniBandとの遅延ギャップが縮小しつつあります。
* 光トランシーバーと銅DACの供給ボトルネック: 高速InfiniBandシステムに不可欠な光トランシーバーや銅製ダイレクトアタッチケーブル(DAC)の供給にボトルネックが生じることがあり、市場の拡大を妨げる可能性があります。
* 単一ベンダーロックインによるマルチベンダー認証の遅延: InfiniBand市場は特定のベンダーに集中する傾向があり、これがマルチベンダー環境での認証プロセスを遅らせ、導入の柔軟性を低下させる要因となることがあります。
主要なセグメンテーション
市場は以下の主要なセグメントに分類され、詳細な分析が行われています。
* コンポーネント別: ホストチャネルアダプター(HCA)、スイッチ、ケーブルとトランシーバー、ソフトウェアと管理ツール。
* データレート別: SDR/DDR、QDR/FDR、EDR、HDR (200 G)、NDR (400 G)、XDR (800 G)およびそれ以降。特にXDR 800 Gb/sは、年平均成長率42.22%で最も急速に成長するデータレートセグメントと予測されています。
* アプリケーション別: 高性能コンピューティング、AI/MLトレーニングと推論、エンタープライズストレージとデータベース、金融サービスとHFT、クラウドサービスプロバイダーインフラストラクチャ。AIトレーニングクラスターでは、ロスレスでサブマイクロ秒の低遅延、およびインスイッチ集団加速が、大規模な勾配同期に不可欠であるため、InfiniBandが優位性を保っています。
* 展開モデル別: オンプレミス型クラスター、クラウド/ホステッドHPC。
* エンドユーザー産業別: 政府および防衛、学術機関および研究機関、BFSI(銀行・金融サービス・保険)、製造業およびエンジニアリング、ライフサイエンス、メディアおよびエンターテイメント。
地域別の動向
地域別では、北米が2024年の市場収益の39%を占め、市場をリードしています。これは、ハイパースケールクラウドへの大規模な支出と、政府によるエクサスケールHPCプログラムへの積極的な投資によって強く牽引されています。
競争環境と主要企業
レポートでは、市場集中度、主要企業の戦略的動き、市場シェア分析が詳細に記述されています。NVIDIA (Mellanox)、Intel、Oracle、IBM、Cisco Systems、Arista Networks、Broadcom、Hewlett Packard Enterprise、Dell Technologies、Lenovo、Amazon Web Services、Microsoft Azure、Google Cloud、Huawei、Fujitsuなど、多数の主要企業が市場で活動しています。
調査方法の信頼性
Mordor Intelligenceの調査は、厳格かつ多角的な方法論に基づいており、その信頼性は高く評価されています。一次調査では、HPCクラスターアーキテクトなどへの詳細なインタビューを実施し、実世界データを検証しています。デスク調査では、Top500スーパーコンピューターリスト、米国エネルギー省の調達情報、EuroHPCの予算文書、OpenFabrics Allianceの仕様、Volzaの税関記録といった信頼性の高い公開情報源を活用しています。市場規模の算出と予測は、グローバルなHPCおよびAIサーバー支出を基にしたトップダウンアプローチと、スイッチポート出荷量やHCAボリュームのチャネルチェックによるボトムアップアプローチを組み合わせたハイブリッドモデルを採用しています。データは毎年更新され、Top500ポート数やIDCサーバー追跡データとの照合、外れ値の調査、二段階のピアレビューを通じて厳格に検証されており、クライアントに最新かつ信頼性の高い市場情報を提供しています。

1. はじめに
- 1.1 調査の前提条件と市場の定義
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
-
4.2 市場の推進要因
- 4.2.1 爆発的なAI/LLMクラスターの展開
- 4.2.2 国家的なエクサスケールHPCプログラムの普及
- 4.2.3 InfiniBandに標準化するクラウドGPUスーパーポッド
- 4.2.4 低遅延金融分析への需要の高まり
- 4.2.5 国内相互接続製造に対する政府のインセンティブ
- 4.2.6 1.6 Tb/s (NDR200) ファブリックへのロードマップの飛躍
-
4.3 市場の阻害要因
- 4.3.1 高い設備投資と実装の複雑さ
- 4.3.2 800 G/1.6 T ウルトライーサネットにおける急速な性能向上
- 4.3.3 光トランシーバーおよび銅DACの供給ボトルネック
- 4.3.4 シングルベンダーロックインによるマルチベンダー認証の遅延
- 4.4 バリュー/サプライチェーン分析
- 4.5 規制環境
- 4.6 技術的展望
-
4.7 ポーターの5つの力分析
- 4.7.1 新規参入者の脅威
- 4.7.2 買い手の交渉力
- 4.7.3 供給者の交渉力
- 4.7.4 代替品の脅威
- 4.7.5 競争の激しさ
5. 市場規模と成長予測(価値)
-
5.1 コンポーネント別
- 5.1.1 ホストチャネルアダプター (HCA)
- 5.1.2 スイッチ
- 5.1.3 ケーブルとトランシーバー
- 5.1.4 ソフトウェアと管理ツール
-
5.2 データレート別
- 5.2.1 SDR/DDR
- 5.2.2 QDR/FDR
- 5.2.3 EDR
- 5.2.4 HDR (200 G)
- 5.2.5 NDR (400 G)
- 5.2.6 XDR (800 G) およびそれ以降
-
5.3 アプリケーション別
- 5.3.1 ハイパフォーマンスコンピューティング
- 5.3.2 AI/MLトレーニングと推論
- 5.3.3 エンタープライズストレージとデータベース
- 5.3.4 金融サービスとHFT
- 5.3.5 クラウドサービスプロバイダーインフラストラクチャ
-
5.4 展開モデル別
- 5.4.1 オンプレミスクラスター
- 5.4.2 クラウド/ホスト型HPC
-
5.5 エンドユーザー産業別
- 5.5.1 政府および防衛
- 5.5.2 学術機関および研究機関
- 5.5.3 BFSI
- 5.5.4 製造業およびエンジニアリング
- 5.5.5 ライフサイエンス
- 5.5.6 メディアおよびエンターテイメント
-
5.6 地域別
- 5.6.1 北米
- 5.6.1.1 米国
- 5.6.1.2 カナダ
- 5.6.1.3 メキシコ
- 5.6.2 南米
- 5.6.2.1 ブラジル
- 5.6.2.2 アルゼンチン
- 5.6.2.3 その他の南米諸国
- 5.6.3 ヨーロッパ
- 5.6.3.1 ドイツ
- 5.6.3.2 イギリス
- 5.6.3.3 フランス
- 5.6.3.4 イタリア
- 5.6.3.5 スペイン
- 5.6.3.6 その他のヨーロッパ諸国
- 5.6.4 アジア太平洋
- 5.6.4.1 中国
- 5.6.4.2 インド
- 5.6.4.3 日本
- 5.6.4.4 韓国
- 5.6.4.5 その他のアジア太平洋諸国
- 5.6.5 中東およびアフリカ
- 5.6.5.1 中東
- 5.6.5.1.1 サウジアラビア
- 5.6.5.1.2 アラブ首長国連邦
- 5.6.5.1.3 トルコ
- 5.6.5.1.4 その他の中東諸国
- 5.6.5.2 アフリカ
- 5.6.5.2.1 南アフリカ
- 5.6.5.2.2 ナイジェリア
- 5.6.5.2.3 その他のアフリカ諸国
6. 競合情勢
- 6.1 市場集中度
- 6.2 戦略的動向
- 6.3 市場シェア分析
-
6.4 企業プロファイル(グローバルレベルの概要、市場レベルの概要、主要セグメント、利用可能な財務情報、戦略情報、主要企業の市場ランキング/シェア、製品とサービス、および最近の動向を含む)
- 6.4.1 NVIDIA (Mellanox)
- 6.4.2 Intel
- 6.4.3 Oracle
- 6.4.4 IBM
- 6.4.5 Cisco Systems
- 6.4.6 Arista Networks
- 6.4.7 Broadcom
- 6.4.8 Cornelis Networks
- 6.4.9 Hewlett Packard Enterprise
- 6.4.10 Dell Technologies
- 6.4.11 Lenovo
- 6.4.12 Amazon Web Services
- 6.4.13 Microsoft Azure
- 6.4.14 Google Cloud
- 6.4.15 Huawei
- 6.4.16 富士通
- 6.4.17 Penguin Computing
- 6.4.18 Supermicro
- 6.4.19 Inspur
- 6.4.20 GigaIO
- 6.4.21 Atos/Bull
- 6.4.22 Gigabyte Technology
- 6.4.23 QCT (Quanta)
7. 市場機会と将来展望
*** 本調査レポートに関するお問い合わせ ***

インフィニバンドは、サーバー、ストレージ、ネットワーク機器間のデータ転送を目的とした、極めて高速かつ低遅延のインターコネクト技術でございます。特に、高性能計算(HPC)や人工知能(AI)、機械学習(ML)といった分野において、その真価を発揮します。この技術は、CPUの介在なしに直接メモリ間でデータを転送するRDMA(Remote Direct Memory Access)をネイティブでサポートしており、これによりデータ転送におけるCPUオーバーヘッドを最小限に抑え、アプリケーションの実行効率を大幅に向上させることが可能です。インフィニバンドは、InfiniBand Trade Association(IBTA)によって標準化されており、その仕様は継続的に進化しております。これは単なるネットワーク技術ではなく、システム全体のパフォーマンスを最大化するためのファブリック技術として位置づけられています。
インフィニバンドは、その登場以来、継続的な技術革新により世代ごとに転送速度を向上させてまいりました。初期のSDR(Single Data Rate)が1レーンあたり2.5ギガビット/秒であったのに対し、DDR(Double Data Rate)では5ギガビット/秒、QDR(Quad Data Rate)では10ギガビット/秒と倍々で高速化が進みました。その後、FDR(Fourteen Data Rate)で14ギガビット/秒、EDR(Enhanced Data Rate)で25ギガビット/秒、HDR(High Data Rate)で50ギガビット/秒と進化し、現在主流となっているのはHDRでございます。さらに最新世代としてNDR(Next Data Rate)が登場し、1レーンあたり100ギガビット/秒を実現しており、現在その導入が進められております。これらのレーンは、通常4x、8x、12xといった形で束ねて使用され、例えばHDRの4x接続では200ギガビット/秒、NDRの4x接続では400ギガビット/秒といった非常に高い帯域幅を提供いたします。将来の世代としては、XDR(Extreme Data Rate)が計画されており、さらなる高速化が期待されております。
インフィニバンドの主要な用途は、やはり高性能計算(HPC)分野にございます。スーパーコンピュータや大規模な科学技術計算、複雑なシミュレーションなどにおいて、数千から数万の計算ノード間での高速かつ低遅延なデータ通信は不可欠であり、インフィニバンドはそのボトルネックを解消する上で中心的な役割を担っております。また、近年急速に発展している人工知能(AI)や機械学習(ML)の分野においても、インフィニバンドは極めて重要な技術でございます。特に、大規模なディープラーニングモデルの学習には、多数のGPU(Graphics Processing Unit)を連携させる必要があり、GPU間の膨大なデータ転送を効率的に行うために、インフィニバンドのGPUDirect RDMA機能が活用されております。これにより、GPUメモリとインフィニバンドアダプタ間で直接データ転送が可能となり、学習時間の短縮と計算効率の向上に大きく貢献しております。
HPCやAI/MLといった特定の高性能コンピューティング環境だけでなく、インフィニバンドはデータセンター全体における様々な用途でその価値を発揮いたします。例えば、大規模なデータ分析やリアルタイム処理が求められる環境では、サーバーとストレージ間の高速なデータアクセスが不可欠であり、インフィニバンドはストレージネットワークのバックボーンとしても利用されております。特に、NVMe over Fabrics(NVMe-oF)の基盤としてインフィニバンドを採用することで、NVMe SSDの持つ高い性能をネットワーク経由で最大限に引き出すことが可能となります。これにより、ストレージの共有化と高性能化を両立させ、データ集約型アプリケーションのパフォーマンスを向上させます。さらに、金融サービス分野における高頻度取引(HFT)のように、ミリ秒以下の超低遅延がビジネスの成否を分けるような環境においても、インフィニバンドはその卓越した低遅延性能から採用されるケースがございます。
インフィニバンドと関連する技術として、まずその核となるRDMA(Remote Direct Memory Access)が挙げられます。これはCPUを介さずにネットワークアダプタが直接リモートのメモリにアクセスする技術であり、インフィニバンドがネイティブでサポートすることで、極めて高いスループットと低いレイテンシを実現しています。RDMAをイーサネット上で実現する技術としてRoCE(RDMA over Converged Ethernet)も存在し、これはインフィニバンドの競合技術の一つと見なされることがあります。RoCEは汎用的なイーサネットインフラを利用できる利点がありますが、インフィニバンドは専用設計であるため、より高い性能と効率を提供することが多いです。また、NVMe-oF(NVMe over Fabrics)は、ネットワーク経由でNVMeストレージを利用するためのプロトコルであり、インフィニバンドはその物理層およびデータリンク層として非常に優れた選択肢となります。汎用的なデータセンターネットワークの主流であるイーサネットと比較すると、インフィニバンドは特定の高性能用途に特化しており、それぞれの技術が異なる市場ニーズに応えていると言えます。
インフィニバンド市場において、NVIDIA社(旧Mellanox Technologies)は圧倒的なシェアを誇る主要ベンダーでございます。NVIDIAは、インフィニバンドのスイッチ、ネットワークアダプタ、ケーブル、そして関連するソフトウェアスタックに至るまで、包括的なソリューションを提供しており、事実上の業界標準を確立しております。市場における競合としては、前述のRoCEを含む高速イーサネット(400GbE、800GbEなど)が挙げられます。イーサネットは汎用性とコスト効率に優れるため、多くのデータセンターで採用されておりますが、インフィニバンドはHPCやAI/MLといった、極限の性能と効率が求められるニッチな市場に特化することで、その優位性を維持しております。インフィニバンドの導入コストは、一般的なイーサネットと比較して高価になる傾向がございますが、その卓越した性能がもたらす計算効率の向上や、大規模システムのボトルネック解消効果を考慮すると、費用対効果の面で十分に正当化されることが多くございます。NVIDIAが主導する強力なエコシステムも、インフィニバンドの普及を後押ししております。
インフィニバンドの将来展望は、非常に明るいものと予測されております。特に、人工知能(AI)技術の進化と普及は、インフィニバンドの需要をさらに加速させる主要な要因となるでしょう。ディープラーニングモデルの規模が拡大し、より多くのGPUを連携させて学習を行う必要性が高まるにつれて、GPU間の高速かつ低遅延な通信を実現するインフィニバンドの重要性は増すばかりでございます。NVIDIAは、自社のGPU、DPU(Data Processing Unit)、そしてインフィニバンドを統合したプラットフォーム戦略を推進しており、これによりAIインフラストラクチャ全体の性能と効率を最大化することを目指しております。また、NDRからXDR、そしてその先の世代へと、インフィニバンドの転送速度は今後も継続的に向上していくことが確実視されております。パブリッククラウドサービスにおいても、HPCやAIワークロード向けの高性能インスタンスでインフィニバンドが採用されるケースが増えており、その適用範囲は拡大していくでしょう。高効率なデータ転送は、データセンターの消費電力削減にも貢献し、持続可能なコンピューティング環境の実現にも寄与すると考えられます。