大規模言語モデル (LLM) 市場規模・シェア分析-成長動向と予測 (2025-2030年)
大規模言語モデル市場レポートは、提供形態(ソフトウェアプラットフォームとフレームワークなど)、展開形態(クラウドなど)、モデルサイズ(70億パラメータ未満など)、モダリティ(テキスト、コードなど)、アプリケーション(チャットボットとバーチャルアシスタントなど)、エンドユーザー産業(BFSIなど)、および地域(北米、ヨーロッパ、アジアなど)別に分類されます。市場予測は、金額(米ドル)で提供されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
大規模言語モデル(LLM)市場の概要についてご説明いたします。
市場規模と成長予測
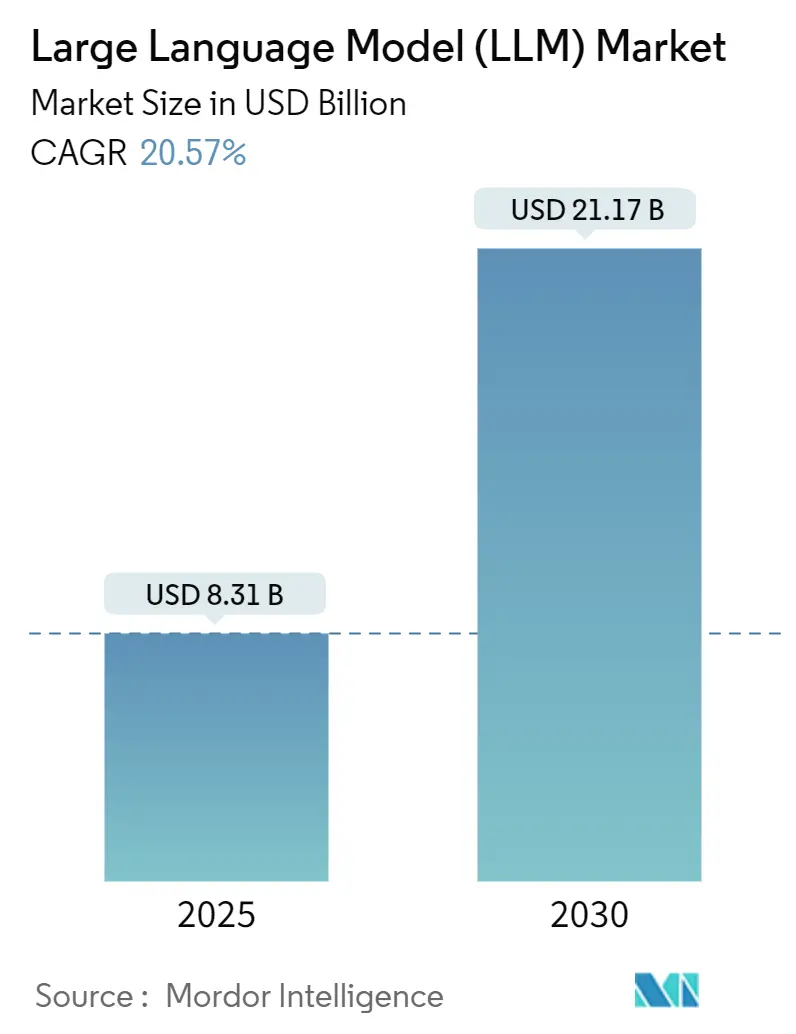
大規模言語モデル(LLM)市場は、2025年には83.1億米ドルに達し、2030年までには211.7億米ドルに成長すると予測されており、予測期間中の年平均成長率(CAGR)は20.57%と見込まれています。地域別では、北米が最大の市場であり、アジア太平洋地域が最も急速に成長する市場となるでしょう。市場の集中度は中程度です。
市場の主要動向
LLM市場は、GPU技術の革新、マルチモーダルアーキテクチャの進化、各国のAI規制、ドメイン固有APIの登場、そしてエッジ最適化された小型言語モデル(SLM)の普及といった複数の要因によって急速に変化しています。
NvidiaのBlackwellプラットフォームやAWS Trainium2のようなGPUコンピューティングの進歩は、LLMの所有コストを大幅に削減し、あらゆる規模の企業が社内またはマネージドLLMイニシアチムを導入する障壁を取り除いています。これにより、LLMの導入が加速しています。
テキスト、画像、音声を単一のパイプラインで処理するマルチモーダルアーキテクチャは、研究段階から商用提供へと移行しており、会話型AIだけでなく、デザイン、診断、広告といった幅広い分野での採用を拡大しています。
各国のAI規制、特に中国の暫定措置やEUのAI法案は、企業が地域特化型またはオンプレミスでのLLM展開を検討する動きを促しています。これにより、データ主権の確保とコンプライアンスの遵守が重視されるようになっています。
銀行やヘルスケア分野におけるドメイン固有のLLM APIは、ハルシネーション(誤情報生成)のリスクを低減し、コンプライアンスを容易にすることで、汎用モデルに代わる選択肢として注目されています。
さらに、エッジ最適化されたSLMは、スマートフォン、ウェアラブルデバイス、産業用OEMのデバイスロードマップを再構築し、チップベンダーや推論サービスプロバイダーに新たな収益源をもたらしています。これらの要因が複合的に作用し、LLM市場は集中型クラウドワークロードから、より分散され、どこにでも存在するインテリジェンスファブリックへと進化していくと予測されます。
主要な市場セグメント別分析
* 提供形態別: ソフトウェアプラットフォームが2024年の市場収益の59%を占め、LLMの実験、プロンプトチェーン、ファインチューニングの基盤となっています。アドバイザリーおよびチューニングサービスは、2030年までにCAGR 24.7%で拡大すると予測されています。
* 展開形態別: オンプレミスソリューションが2024年の市場支出の52.4%を占め、銀行や病院などがデータ主権とレイテンシー制御を優先しています。しかし、エッジ/デバイス展開は2030年までにCAGR 28.3%で最も急速に成長すると見込まれており、自律検査ドローンやフィールドサービスウェアラブルなどでの利用が拡大しています。
* モデルサイズ別: 1000億パラメータ未満のモデルが2024年の市場収益の70%を占め、コスト効率と導入の容易さから中堅企業に広く採用されています。一方、3000億パラメータを超えるモデルは、複雑な推論や科学的発見のユースケースに牽引され、CAGR 30.1%で成長すると予測されています。
* モダリティ別: テキスト中心のアーキテクチャが2024年の収益の68.3%を占めていますが、マルチモーダルモデルは2030年までにCAGR 29.8%で急増すると見込まれています。これは、顧客エンゲージメント、広告、医療診断など、テキスト以外のデータ(画像、音声など)を処理する需要が高まっているためです。
* アプリケーション別: チャットボットと仮想アシスタントが2024年の需要の26.8%を占めていますが、コード生成およびレビューツールはCAGR 25.4%で成長し、開発者の生産性向上に大きく貢献しています。
* エンドユーザー産業別: 小売およびEコマースが2024年の収益の27.2%を占めていますが、ヘルスケア分野は2030年までにCAGR 26.8%で最も急速に成長すると予測されています。臨床LLMは診断推論、文献合成、個別化された退院指示などをサポートし、患者の転帰改善に貢献しています。
地域別分析
* 北米: 2024年の市場収益の32.1%を占め、ベンチャー資金、豊富な人材、クラウドGPU供給に支えられています。富裕層管理、腫瘍学の意思決定支援、法的調査などのドメイン固有アシスタントの導入で先行しています。
* アジア太平洋: 2025年から2030年の間にCAGR 32.6%で最も速く成長すると予測されています。各国政府が主権モデルイニシアチブを支援し、中国のオンショアトレーニング義務化や日本のデジタルガーデン戦略、インドのIndiaAIミッションなどが市場を牽引しています。
* 欧州: EU AI Actの下で、データレジデンシーとスケーラビリティを両立させるハイブリッド展開が主流となっています。スペイン、フランス、イタリアなどでAI対応サーバーファームが増強されており、SaaSベンダーによる多言語チャットや請求書照合機能の統合が進んでいます。
競争環境
LLM市場の上位5ベンダーが収益の85%以上を支配しており、シリコンからソフトウェアまでを網羅する統合スタックが強みです。Nvidiaはソフトウェアオーケストレーション資産の買収により、ワンストップAIプラットフォームプロバイダーとしての地位を強化しました。MicrosoftはOpenAIとxAIとの提携を深め、モデルリスクを分散し、顧客の魅力を拡大しています。OracleはMicrosoftおよびOpenAIと連携し、マルチクラウドAIリージョンを提供しています。
オープンソースの挑戦者や地域スペシャリストも、効率的なチェックポイントを低コストで提供することで存在感を示しています。AnthropicのClaude 4は多段階推論ベンチマークを向上させ、Meta由来モデルのファインチューニングがコミュニティリーダーボードを席巻しています。韓国やドイツの通信事業者は、規制されたワークロードを獲得するため、主権AIクラウドを立ち上げています。
戦略的提携がエンタープライズRFPを決定する重要な要素となっており、リファレンスアーキテクチャ、コストシミュレーター、コンプライアンスダッシュボードを提供するベンダーが優位に立っています。エネルギー効率、サプライチェーンの回復力、透明な使用状況指標が主要サービス契約で重視されるようになり、市場の成熟を示しています。
主要企業
* Alibaba Group Holding Limited
* Amazon Web Services (AWS)
* Anthropic
* Baidu, Inc.
* Google LLC
最近の業界動向
* 2025年5月: Anthropicが多段階推論を改善したClaude 4モデルを発表しました。
* 2025年5月: MicrosoftがAnthropicとxAIの技術を統合し、AIスタックを多様化しました。
* 2025年5月: OpenAIがソフトウェア開発タスク向けエージェントCodexを発表しました。
* 2025年4月: GoogleがAIエージェント向けにAnthropicの相互運用プロトコルを採用しました。
* 2025年4月: NvidiaがフルスタックAI制御を拡大する買収を発表しました。
* 2025年3月: EY IndiaがLLAMA 3.1-8BをベースにしたBFSI向けファインチューニングLLMを発表しました。
* 2025年3月: GoogleがAnthropicに投資し、AIパートナーシップを強化しました。
* 2025年3月: NebiusとYTLがBlackwell Ultra GPUインスタンスをリリースしました。
以上が、大規模言語モデル(LLM)市場の概要となります。
Mordor Intelligenceの調査レポートは、大規模言語モデル(LLM)市場に関する包括的な分析を提供しています。本レポートにおいてLLM市場は、10億以上のパラメータを持つTransformerベースモデルのトレーニング、展開、消費を可能にするソフトウェアプラットフォーム、フレームワーク、および関連する統合・ファインチューニングサービスから生じる収益と定義されています。GPU、ASIC、サーバーの販売は本調査の範囲外とされています。
市場規模は2025年に83.1億米ドルと評価されており、2030年までに211.7億米ドルに達すると予測されています。
市場の成長を牽引する主な要因としては、以下の点が挙げられます。
* Nvidia BlackwellやAWS Trainium2といった技術革新によるGPUコンピューティングコストの急速な低下。
* 北米のBFSI(銀行・金融サービス・保険)およびヘルスケア分野における企業向けドメイン特化型LLM APIの登場。
* 中国の2024年暫定規則のような各国AI政策によるローカルトレーニングの義務化。
* 欧州のCRM/ERPシステムにおけるLLM組み込み機能によるSaaSのアップセル機会。
* グローバルなAdTechエージェンシーからのマルチモーダルコンテンツ需要の急増。
* スマートフォン向けのエッジ最適化型小型言語モデル(20億パラメータ未満)の進化。
一方で、市場の成長を阻害する要因も存在します。
* 南米の中小企業において、1Kトークンあたり0.12米ドルという推論エネルギーコストの高騰がLLM導入を制限している点。
* EU AI Actの高リスクコンプライアンスに伴う追加費用。
* アフリカ言語向けの多言語トレーニングデータ不足。
* H100 GPU供給におけるハイパースケーラーの支配によるオンプレミスHPC(高性能コンピューティング)の制約。
本レポートでは、市場を以下の主要なセグメントに分類し、詳細な分析を行っています。
* 提供形態別: ソフトウェアプラットフォーム(汎用LLMプラットフォーム、ドメイン特化型LLMソリューション)とサービス(コンサルティング、システムインテグレーション、ファインチューニング、カスタマイズ、マネージド推論、ホスティング)に分類されます。
* 展開方法別: 柔軟性とスケーラビリティを提供するクラウド(パブリック、プライベート)、データ主権とセキュリティを重視するオンプレミス/専用AIクラスター、そして低遅延とプライバシー保護に優れるエッジ/デバイス組み込み型が分析されます。
* モデルサイズ(パラメータ数)別: 70億未満の小型モデルから3000億を超える超大型モデルまで、その性能とコスト効率のバランスが評価されます。
* モダリティ別: テキスト、コード、画像、オーディオ、そしてこれらを組み合わせたマルチモーダルモデルの進化が注目されます。
* アプリケーション別: チャットボット、仮想アシスタント、コード生成、レビュー、コンテンツ・メディア生成、顧客サービス自動化、言語翻訳、ローカライゼーション、感情・意図分析、自律エージェント、RPAなど、幅広い用途がカバーされています。
* エンドユーザー産業別: BFSIやヘルスケアといった規制の厳しい分野から、小売、Eコマース、メディア、エンターテイメント、IT、通信、教育、製造、政府、防衛まで、各産業におけるLLMの導入状況と潜在的な影響が分析されます。
* 地域別: 北米、欧州、アジア太平洋、南米、中東、アフリカの主要地域および各国市場の動向が詳細に調査されています。
レポートの主要な洞察として、アジア太平洋地域が政府投資と多言語モデル需要に支えられ、2030年まで年平均成長率(CAGR)32.6%で最も急速に成長すると予測されています。また、エッジ展開は低遅延、強力なプライバシー、帯域幅コスト削減の利点から、展開セグメントで28.3%のCAGRを記録し、将来の成長を牽引すると見込まれています。産業別では、ヘルスケア分野が臨床意思決定支援、研究加速、患者エンゲージメントアプリケーションにより、26.8%のCAGRで最も積極的に投資すると予想されています。規制面では、中国の暫定措置やEU AI Actのような政策が、ローカルトレーニングを奨励し、コンプライアンスコストを上昇させ、説明可能で地域ホスト型モデルへの需要を促進するでしょう。モデルサイズに関しては、企業は費用対効果の高い推論のために1000億パラメータ未満のモデルを好む傾向にありますが、3000億パラメータを超える超大型モデルも複雑な推論タスクで優位性を保ち、30.1%のCAGRで成長しています。
競争環境においては、OpenAI、Google LLC、Anthropic PBC、Microsoft Corp.、Amazon Web Services Inc.、Meta Platforms Inc.、NVIDIA Corp.、IBM Corp.、Alibaba Group Holding Ltd.、Baidu Inc.、Tencent Holdings Ltd.、Huawei Technologies Co. Ltd.など、多数の主要企業が市場に参入しており、市場集中度、戦略的動向、市場シェア分析が実施されています。
Mordor Intelligenceは、市場規模の算出と予測において、トップダウンとボトムアップのアプローチを組み合わせた厳格な調査方法を採用しています。公開されている一次情報源やサブスクリプションデータベースからのデータ収集に加え、AI製品リーダーやクラウド運用アーキテクトなどへの一次調査を通じて、データギャップを埋め、モデルの仮定を検証しています。他社の予測との比較では、ハードウェア収益のバンドルや均一な価格設定の仮定を避けることで、より信頼性の高いベースラインを提供していると強調されています。レポートは毎年更新され、重要な資金調達ラウンド、規制変更、画期的なモデルリリースによって中間改訂が行われます。
1. はじめに
- 1.1 調査の前提条件と市場の定義
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
-
4.2 市場の推進要因
- 4.2.1 Nvidia BlackwellおよびAWS Trainium2によるGPUコンピューティングの急速なコスト低下
- 4.2.2 BFSIおよびヘルスケア(北米)におけるエンタープライズグレードのドメイン固有LLM API
- 4.2.3 国内AI政策によるローカルトレーニングの強制(例:中国暫定規則2024)
- 4.2.4 組み込みLLM機能からのSaaSアップセル機会(欧州CRM/ERP)
- 4.2.5 グローバルAdTechエージェンシーからのマルチモーダルコンテンツ需要の急増
- 4.2.6 スマートフォン向けエッジ最適化小型言語モデル(20億パラメータ未満)
-
4.3 市場の阻害要因
- 4.3.1 推論エネルギーコストの高騰(1Kトークンあたり0.12米ドル)による中小企業導入の制限(南米)
- 4.3.2 EU AI法における高リスクコンプライアンスのオーバーヘッド
- 4.3.3 アフリカ言語向け多言語トレーニングデータの不足
- 4.3.4 ハイパースケーラーによるH100 GPU供給の支配がオンプレミスHPCを制約
- 4.4 産業エコシステム分析
- 4.5 技術的展望
-
4.6 ポーターの5つの力分析
- 4.6.1 新規参入の脅威
- 4.6.2 買い手の交渉力
- 4.6.3 供給者の交渉力
- 4.6.4 代替品の脅威
- 4.6.5 競争上の対抗関係
5. 市場規模と成長予測(数値)
-
5.1 提供別
- 5.1.1 ソフトウェアプラットフォームとフレームワーク
- 5.1.1.1 汎用LLMプラットフォーム
- 5.1.1.2 ドメイン特化型LLMソリューション
- 5.1.2 サービス
- 5.1.2.1 コンサルティングとシステムインテグレーション
- 5.1.2.2 ファインチューニングとカスタマイズ
- 5.1.2.3 マネージド推論とホスティング
-
5.2 展開別
- 5.2.1 クラウド(パブリックおよびプライベート)
- 5.2.2 オンプレミス/専用AIクラスター
- 5.2.3 エッジ/デバイス組み込み
-
5.3 モデルサイズ別 – パラメータ
- 5.3.1 70億未満のパラメータ
- 5.3.2 70億~700億のパラメータ
- 5.3.3 700億~3000億のパラメータ
- 5.3.4 3000億超のパラメータ
-
5.4 モダリティ別
- 5.4.1 テキスト
- 5.4.2 コード
- 5.4.3 画像
- 5.4.4 オーディオ
- 5.4.5 マルチモーダル
-
5.5 アプリケーション別
- 5.5.1 チャットボットとバーチャルアシスタント
- 5.5.2 コード生成とレビュー
- 5.5.3 コンテンツとメディア生成
- 5.5.4 カスタマーサービス自動化
- 5.5.5 言語翻訳とローカリゼーション
- 5.5.6 感情・意図分析
- 5.5.7 自律型エージェントとRPA
-
5.6 エンドユーザー産業別
- 5.6.1 BFSI
- 5.6.2 ヘルスケアとライフサイエンス
- 5.6.3 小売とEコマース
- 5.6.4 メディアとエンターテイメント
- 5.6.5 情報技術と通信
- 5.6.6 教育
- 5.6.7 製造業
- 5.6.8 政府と防衛
-
5.7 地域別
- 5.7.1 北米
- 5.7.1.1 米国
- 5.7.1.2 カナダ
- 5.7.1.3 メキシコ
- 5.7.2 欧州
- 5.7.2.1 ドイツ
- 5.7.2.2 英国
- 5.7.2.3 フランス
- 5.7.2.4 イタリア
- 5.7.2.5 スペイン
- 5.7.2.6 その他の欧州
- 5.7.3 アジア太平洋
- 5.7.3.1 中国
- 5.7.3.2 日本
- 5.7.3.3 韓国
- 5.7.3.4 インド
- 5.7.3.5 東南アジア
- 5.7.3.6 その他のアジア太平洋
- 5.7.4 南米
- 5.7.4.1 ブラジル
- 5.7.4.2 その他の南米
- 5.7.5 中東とアフリカ
- 5.7.5.1 中東
- 5.7.5.1.1 アラブ首長国連邦
- 5.7.5.1.2 サウジアラビア
- 5.7.5.1.3 その他の中東
- 5.7.5.2 アフリカ
- 5.7.5.2.1 南アフリカ
- 5.7.5.2.2 その他のアフリカ
6. 競合情勢
- 6.1 市場集中度
- 6.2 戦略的動き
- 6.3 市場シェア分析
-
6.4 企業プロファイル(グローバル概要、市場概要、主要セグメント、財務、戦略情報、市場順位/シェア、製品とサービス、最近の動向を含む)
- 6.4.1 OpenAI LP
- 6.4.2 Google LLC
- 6.4.3 Anthropic PBC
- 6.4.4 Microsoft Corp.
- 6.4.5 Amazon Web Services Inc.
- 6.4.6 Meta Platforms Inc.
- 6.4.7 NVIDIA Corp.
- 6.4.8 IBM Corp.
- 6.4.9 Alibaba Group Holding Ltd.
- 6.4.10 Baidu Inc.
- 6.4.11 Tencent Holdings Ltd.
- 6.4.12 Huawei Technologies Co. Ltd.
- 6.4.13 Cohere Inc.
- 6.4.14 AI21 Labs Ltd.
- 6.4.15 Mistral AI SAS
- 6.4.16 Stability AI Ltd.
- 6.4.17 Databricks Inc.
- 6.4.18 Snowflake Inc.
- 6.4.19 ByteDance Ltd.
- 6.4.20 Yandex LLC
- 6.4.21 Samsung SDS Co. Ltd.
- 6.4.22 Oracle Corp.
7. 市場機会と将来の見通し
*** 本調査レポートに関するお問い合わせ ***

大規模言語モデル(LLM)は、近年急速に注目を集めている人工知能技術の中核をなす概念です。まず、その定義から詳しく見ていきましょう。
大規模言語モデルとは、膨大な量のテキストデータを学習することで、人間が話すような自然な言語を理解し、生成する能力を持つ深層学習モデルのことを指します。特に、トランスフォーマーアーキテクチャを基盤としており、数億から数兆に及ぶパラメータを持つことが特徴です。これにより、文脈を深く理解し、複雑な質問応答、文章要約、翻訳、さらには創造的な文章生成まで、多岐にわたる言語タスクを高精度で実行することが可能になります。単に単語の羅列を予測するだけでなく、言語の構造、意味、さらには常識的な知識までを学習している点が、従来の言語モデルとの決定的な違いと言えるでしょう。
次に、大規模言語モデルの種類についてご説明します。主な分類としては、そのアーキテクチャに基づいたものがあります。一つは、入力された情報をエンコードし、それを基に出力をデコードする「エンコーダー・デコーダー型」です。これは翻訳や要約など、入力と出力が異なる形式のタスクに適しています。もう一つは、過去のトークンに基づいて次のトークンを予測する「デコーダー単独型」で、GPTシリーズに代表されるように、自由なテキスト生成や対話型AIに強みを持っています。さらに、入力テキストの文脈理解に特化した「エンコーダー単独型」も存在し、BERTなどがこれに該当します。また、モデルの公開形態によっても分類され、特定の企業が開発・提供する「クローズドソースモデル」と、研究者や開発者が自由に利用・改変できる「オープンソースモデル」があり、それぞれが異なるエコシステムを形成しています。
大規模言語モデルの用途は非常に広範です。最も一般的なものとしては、チャットボットや仮想アシスタントを通じた顧客対応の自動化が挙げられます。これにより、24時間体制での問い合わせ対応や、パーソナライズされた情報提供が可能になります。また、コンテンツ生成の分野では、ブログ記事、マーケティングコピー、メール、さらにはプログラミングコードの自動生成など、多岐にわたるテキスト作成を支援します。研究開発においては、論文の要約や情報検索の効率化、データ分析の補助としても活用されています。教育分野では、個別最適化された学習教材の作成や、生徒の質問に対する即時応答など、学習体験の向上に貢献しています。さらに、多言語翻訳の精度向上や、アクセシビリティ向上のための音声認識・合成技術への応用も進んでいます。
関連技術についても触れておきましょう。大規模言語モデルの発展を支える基盤技術として、まず「トランスフォーマーアーキテクチャ」が挙げられます。これは、入力シーケンス内の異なる位置にある単語間の関係を捉える「アテンションメカニズム」を導入し、長距離の依存関係を効率的に学習することを可能にしました。また、モデルの学習には膨大な計算資源が必要となるため、NVIDIAのGPUやGoogleのTPUといった「高性能計算ハードウェア」が不可欠です。さらに、モデルの性能を向上させるためには、高品質な「大規模データセット」の収集、クリーニング、前処理が重要となります。学習後のモデルを特定のタスクやユーザーの意図に沿って調整する「ファインチューニング」や、人間のフィードバックを強化学習に組み込む「RLHF(Reinforcement Learning from Human Feedback)」も、モデルの安全性と有用性を高める上で重要な技術です。最近では、外部知識を検索して生成に活用する「RAG(Retrieval Augmented Generation)」も注目されています。
市場背景としては、2022年後半にOpenAIがChatGPTを公開して以来、大規模言語モデルへの関心と投資が爆発的に増加しました。これにより、AI技術は研究室の領域を超え、一般消費者や企業にとって身近な存在となりました。OpenAI、Google、Microsoft、Anthropic、Metaといった大手テクノロジー企業が開発競争を繰り広げ、高性能なモデルを次々と発表しています。同時に、スタートアップ企業も独自のモデルや応用サービスを開発し、市場は活況を呈しています。企業は、業務効率化、新規サービス開発、顧客体験向上などを目的に、LLMの導入を積極的に進めています。一方で、モデルの倫理的な利用、データプライバシー、著作権、誤情報の拡散といった課題も浮上しており、各国政府や国際機関による規制の議論も活発化しています。
最後に、将来展望について述べます。大規模言語モデルは今後も進化を続け、その能力は飛躍的に向上すると予測されています。特に、テキストだけでなく画像、音声、動画といった複数のモダリティを統合的に理解・生成する「マルチモーダルAI」への発展が期待されています。これにより、より人間らしい対話や、複雑な現実世界の問題解決が可能になるでしょう。また、特定の業界や用途に特化した「専門特化型LLM」が増加し、医療、法律、金融などの分野で深い専門知識を持つAIアシスタントが普及すると考えられます。モデルの小型化・軽量化も進み、スマートフォンやエッジデバイス上でも動作する「スモール言語モデル(SLM)」が登場することで、より多くの場所でAIが利用されるようになるでしょう。倫理的側面では、モデルの透明性、公平性、安全性に関する研究と技術開発がさらに進み、信頼できるAIの実現に向けた取り組みが強化されると見込まれます。大規模言語モデルは、社会のあらゆる側面を変革する可能性を秘めており、その進化は私たちの生活や働き方に計り知れない影響を与えることとなるでしょう。