大規模言語モデル (LLM) 市場規模と展望, 2025-2033

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
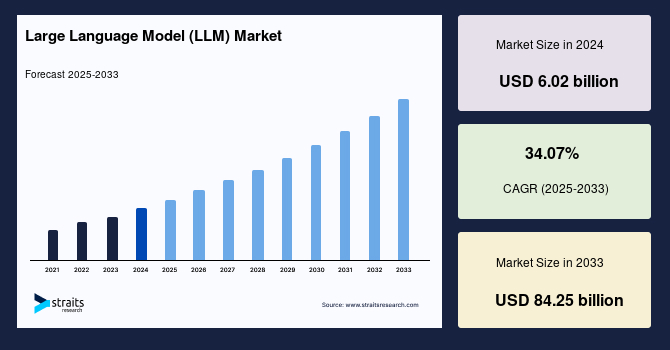
グローバルな大規模言語モデル (LLM) 市場は、2024年に60.2億米ドルと評価されており、2025年には80.7億米ドルから2033年には842.5億米ドルに成長すると予測されており、予測期間(2025年〜2033年)における年平均成長率(CAGR)は34.07%です。大規模言語モデル(LLM)は、膨大な量のテキストデータを用いて、人間のような言語を理解し生成するために訓練された高度な人工知能システムです。深層学習、特にトランスフォーマーアーキテクチャを使用して単語のシーケンスを処理し、予測することで、翻訳、要約、テキスト生成、質問応答などのタスクを可能にします。OpenAIのGPTシリーズのようなLLMは、文法、事実、推論、文脈を多様なソースから学習します。
グローバル市場の主な推進力の一つは、技術大手やAIスタートアップによる研究開発への多額の投資です。これらの投資は、モデルアーキテクチャの進化、訓練効率、展開のスケーラビリティを加速させています。さらに、クラウドベースのAIプラットフォームの台頭により、LLMの機能へのアクセスが民主化され、企業はインフラストラクチャーに多額の投資をすることなくモデルを展開し、スケールアップできるようになりました。グローバルな大規模言語モデル(LLM)市場を形成する重要なトレンドは、テキストだけでなく、画像、音声、ビデオも処理し生成できるマルチモーダル能力の急速な進化です。この開発により、ヘルスケア、マーケティング、カスタマーサービスなどの業界でより動的かつ文脈に富んだAIの対話が可能になりました。このような革新は、多様なデータ形式を処理できる統一AIプラットフォームの需要の高まりを反映しています。
産業界全体でAI駆動の自動化ツールの需要が高まっていることが、大規模言語モデル(LLM)市場の成長の主要な推進力です。組織はますますLLMを活用して反復的なタスクを合理化し、カスタマーサービスを改善し、意思決定プロセスを強化しています。産業界が運用効率の向上とコスト削減を求める中、LLM駆動の自動化ツールの採用は急増し、デジタルトランスフォーメーションの不可欠な資産としての役割を固めることが予想されます。
一方で、グローバルな大規模言語モデル(LLM)市場の主な制約の一つは、これらのモデルの訓練と展開に関連する高い計算コストとエネルギーコストです。大規模なモデルを開発するには膨大なデータセット、強力なGPU、および長時間の訓練が必要であり、しばしば大量の電力消費と環境への影響をもたらします。これらのコストは、小規模な企業が市場に参入することを妨げるだけでなく、持続可能性とカーボンフットプリントについての懸念も引き起こしています。さらに、リアルタイムアプリケーションでLLMを実行するには、継続的な処理能力が必要であり、運用経費が増加します。その結果、コスト効率とスケーラビリティは、様々な業界でのLLMの普及を広げるための主要な課題であり続けています。
大規模言語モデル(LLM)のIoTおよびロボティクスとの統合は、より賢く直感的な人間と機械のインタラクションのための変革的な機会を開いています。自然言語処理をリアルタイムのセンサーデータや自動化と組み合わせることで、LLMは機械がコマンドを文脈的に解釈し、効率的に複雑なタスクを実行することを可能にします。このような革新は、製造業、ヘルスケア、スマートホームなどの業界におけるインテリジェントな自動化の推進におけるLLMの可能性を強調しています。
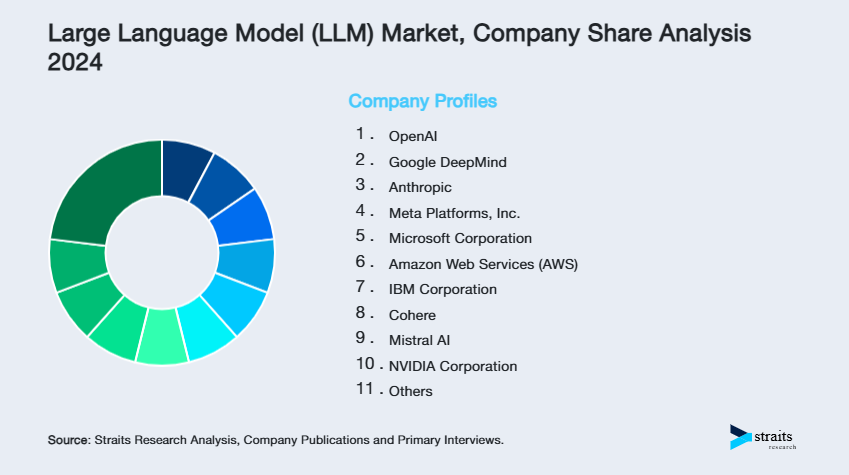
北米は、AI研究への強力な投資とOpenAI、Google、Meta、Microsoftなどの主要技術企業の存在によって、大規模言語モデル(LLM)市場でリードしています。この地域は、LLMの産業全体での無縫な展開とスケーラビリティを可能にする堅牢なクラウドインフラを有しています。例えば、MicrosoftのAzureクラウドおよびMicrosoft 365サービスへのOpenAIのGPTモデルの統合は、企業の生産性ツールにおけるLLMの積極的な採用を示しています。さらに、北米のスタートアップや大学は、自然言語理解や生成AIの進歩に貢献し、LLMの革新の最前線に立っています。倫理的AI開発に対する政府の資金提供と規制支援も、この地域がLLMエコシステムでの優位性を高めています。
米国は、OpenAI、Google、Metaなどの主要プレーヤーによって、グローバルなLLM市場をリードしています。医療、法律、教育、カスタマーサービスなどの多様なセクターでの広範な採用が市場成長を支えています。例えば、ChatGPTはMicrosoft Copilotのような企業ツールに統合されています。国の堅固なAIエコシステム、先進的なインフラ、およびベンチャーキャピタルの資金調達が、最先端の言語モデルの革新と商業化を引き続き支えています。
アジア太平洋地域は、急速なデジタルトランスフォーメーションとAI開発に対する強力な政府支援によって、大規模言語モデル(LLM)市場で顕著な成長を遂げています。中国、日本、韓国、インドなどの国々は、AIインフラストラクチャや革新に多額の投資を行っています。例えば、中国のBaiduのErnie BotやAlibabaのTongyi Qianwenは、西洋のLLMと競争するという中国の野心を示しています。インドでは、スタートアップが地域言語に焦点を当てたLLMを開発し、デジタルサービスにおける言語の壁を解消しようとしています。日本もまた、企業アプリケーションや政府用途に向けてLLMを探求しています。この地域の大規模な人口、多様な言語、および拡大するデジタル経済は、教育、カスタマーサービス、eコマース、ヘルスケアなどのセクターでのLLMの展開にとって豊かな土壌を提供しています。
中国は、Baidu(Ernie Bot)やAlibaba(Tongyi Qianwen)などの技術大手によって、LLM開発で急速に進展しています。政府は「次世代人工知能」戦略の下でAIイニシアチブを強力に支援しています。中国のLLMはますますマンダリンや地方方言に特化しており、政府サービス、eコマース、教育におけるアプリケーションを可能にしています。データ主権とデジタルインフラへの強いフォーカスが国内展開を加速させています。
生成モデルセグメントは、コンテンツ生成、チャットボット、自動化されたライティングツールにおける幅広いアプリケーションのため、大規模言語モデル市場で支配的な地位を保っています。GPTや類似のアーキテクチャを含むこれらのモデルは、人間のようなテキストを生成することが可能であり、企業がコミュニケーションを自動化し、クリエイティブなコンテンツを生成し、ユーザーエンゲージメントを向上させることを可能にします。インテリジェントなテキスト生成への需要の高まりが、このセグメントの成長を引き続き推進しています。
クラウドベースの展開は、市場をリードしており、スケーラビリティ、柔軟性、および大規模言語モデルに必要な高い計算能力を提供します。企業は、AWS、Google Cloud、Azureなどのプラットフォームを通じて、シームレスな統合、インフラストラクチャコストの削減、AI機能へのリアルタイムアクセスの恩恵を受けています。従量課金モデルと地理的な展開の簡素化が採用をさらに促進しており、クラウドベースのソリューションが多様なユースケースにおけるLLMの実装のための好ましい選択肢となっています。
大企業は、先進的なAIソリューションとインフラストラクチャに投資する能力によって、LLMの採用を支配しています。これらの組織は、プロセス自動化、顧客エンゲージメント、市場インテリジェンス、内部知識管理のためにLLMを活用しています。彼らの複雑な運用と大量のデータは、LLM統合に理想的な候補となっています。さらに、大企業はしばしばAIベンダーと協力して特定のビジネスニーズに合わせたカスタマイズLLMアプリケーションを開発しています。
NLPセグメントは、テキスト分類、翻訳、要約、感情分析における高度な機能を可能にするLLMの主要アプリケーション領域です。企業は、非構造化データからの洞察を抽出し、コミュニケーションを自動化し、ユーザーインタラクションを改善するためにNLPを活用しています。インテリジェントな言語理解への需要の増加に伴い、NLPはグローバルな言語モデル市場内での大規模な採用と革新を推進し続けています。
BFSIセクターは、大規模言語モデルを採用し、詐欺検出、カスタマーサービスの自動化、リスク評価、法令遵守のために活用しています。LLMは、文書分析を効率化し、個別化された金融アドバイスを可能にし、AI駆動のチャットボットを通じて顧客との対話を向上させます。金融機関が運用効率と顧客体験の向上を目指す中、このセクターでのLLM統合の需要は大幅に増加しています。
大規模言語モデル市場の企業は、戦略的なコラボレーション、継続的なモデルの洗練、インフラストラクチャのスケーリングを通じて、その影響範囲を拡大しています。企業は、ドメイン固有のソリューションの開発、モデル効率の向上、様々なプラットフォームへのLLMの統合を可能にするAPIの提供に注力しています。倫理的AI、多言語機能、マルチモーダル機能への投資も成長を促進しています。さらに、企業は、モデルをローカライズし、地域のデータプライバシー規制に準拠することで、グローバル市場をターゲットにしています。
アナリストによれば、ヘルスケア、金融、教育、カスタマーサービスなどの産業全体でAI駆動のソリューションへの需要が高まる中、グローバルな大規模言語モデル(LLM)市場は大きな成長の可能性を秘めています。企業は、生産性を向上させ、ワークフローを自動化し、ユーザー体験を個別化するためにLLMをますます活用しています。自然言語理解と生成能力の進歩は、さらにそのユースケースを拡大することが期待されています。しかし、市場はモデル訓練の高コスト、データプライバシーに関する懸念、バイアスや不正確な出力の可能性などの顕著な課題にも直面しています。これらの障害にもかかわらず、モデルの最適化における継続的なイノベーション、オープンソースフレームワークの採用の増加、倫理的AI開発に対する規制の強化が、市場拡大のための有利な環境を育んでいます。全体として、アナリストの見通しは楽観的であり、LLM市場はグローバルなAIの風景における変革的な力へと進化することが予測されています。
Report Coverage & Structure
大規模言語モデル (LLM) 市場レポートの構造概要
このレポートは、大規模言語モデル (LLM) 市場の包括的な分析を提供するために、いくつかの重要なセクションで構成されています。以下にその詳細を示します。
調査の概要と方法論
- 調査目的: レポートの目的と範囲を明確にします。
- 調査範囲とセグメンテーション: 市場のセグメントと調査対象の定義。
- 制限事項と仮定: 調査における制約や仮定についての説明。
- 通貨と価格設定の考慮: 市場分析における通貨と価格設定の基準。
市場機会評価
- 新興地域/国: 新たな成長の可能性がある地域や国の特定。
- 新興企業: 市場における新しい参加者の分析。
- 新興アプリケーション/エンドユース: 新たな市場用途やエンドユースの発展。
市場動向
- 市場の推進要因: 市場成長を促進する要素の分析。
- 市場警告因子: 市場のリスク要因や警告事項の評価。
- 最新のマクロ経済指標: 経済状況が市場に与える影響。
- 地政学的影響: 政治的状況が市場に与える影響。
- 技術要因: 技術革新が市場に与える影響。
市場評価
- ポーターのファイブフォース分析: 市場競争力の分析。
- バリューチェーン分析: 市場における価値の流れの評価。
規制の枠組みと地域別分析
- 規制の枠組み: 地域ごとの規制環境の分析。
- 北米、ヨーロッパ、APAC、中東・アフリカ、LATAM: 各地域における市場の詳細な分析。
ESGトレンドと市場規模分析
- ESGトレンド: 環境、社会、ガバナンスが市場に与える影響の評価。
- 大規模言語モデル (LLM) 市場サイズ分析: モデルタイプ、展開モード、組織規模、アプリケーション、エンドユーザー産業ごとの市場分析。
地域別市場分析
各地域(北米、ヨーロッパなど)における大規模言語モデル (LLM) の市場分析が含まれています。各地域の市場は、モデルタイプ、展開モード、組織規模、アプリケーション、エンドユーザー産業ごとにさらに詳細に分析されています。
このレポートは、大規模言語モデル (LLM) 市場の全体像を把握し、今後のビジネス戦略を策定するための貴重な洞察を提供します。
*** 本調査レポートに関するお問い合わせ ***

大規模言語モデル(Large Language Model、LLM)とは、人工知能の一分野であり、大量のテキストデータを基にして自然言語を理解し生成する能力を持つモデルのことを指します。これらのモデルは、通常、数十億から数百億のパラメータを持ち、広範囲の言語タスクに対応できるよう設計されています。大規模言語モデルは、機械学習の一手法であるディープラーニングを用いて構築され、特にトランスフォーマーアーキテクチャに基づいています。トランスフォーマーは、言語の文脈を掴むための自己注意機構を利用しており、これにより文脈に依存した言葉の生成が可能になります。
大規模言語モデルにはいくつかのタイプがあります。代表的なものとしては、OpenAIが開発したGPTシリーズや、Googleが開発したBERT、さらにはFacebookが開発したRoBERTaなどがあります。これらのモデルはそれぞれ異なる特性を持ち、GPTシリーズは生成タスクに強く、BERTやRoBERTaは特に文脈の理解に強みを持っています。これらのモデルは、事前学習とファインチューニングの2段階のプロセスを経て、特定のタスクに適用されることが一般的です。
大規模言語モデルの利用用途は多岐にわたります。例えば、自動翻訳、要約生成、質問応答システム、感情分析、対話システムなどが挙げられます。また、これらのモデルは、ビジネスにおいても顧客サポートの自動化やデータ分析の補助などで利用され始めています。特に、自然言語処理の分野においては、これらのモデルの登場により、精度や効率が飛躍的に向上しました。
大規模言語モデルに関連する技術としては、分散コンピューティングや大規模データ処理技術があります。これらは、モデルの学習に必要な膨大な計算資源を効率的に利用するために不可欠です。また、倫理的な側面も重要視されており、モデルのバイアスやプライバシー問題への配慮が求められています。さらに、モデルの透明性や説明可能性を高めるための研究も進められており、これにより信頼性のあるAIシステムの構築が目指されています。大規模言語モデルは、今後も技術の進化と共に、さまざまな分野での応用が期待されています。