合成データ生成市場規模と展望、2024-2032

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
合成データ生成市場に関する詳細な市場調査レポートの要約を以下に示します。
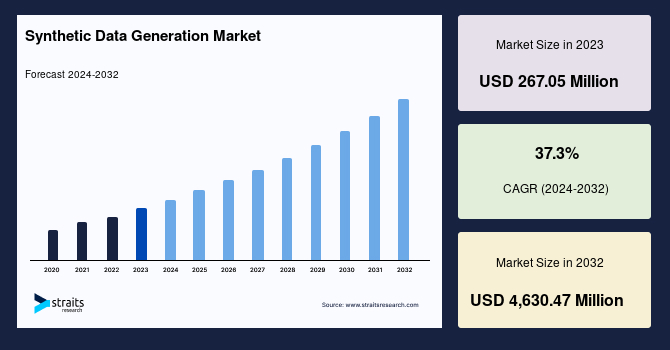
合成データ生成市場は、2023年に267.05百万米ドルの価値があり、2032年には4,630.47百万米ドルに達すると予測されており、2024年から2032年の予測期間中に37.3%のCAGRで成長すると見込まれています。合成データ生成は、実世界のデータに似た人工データを作成します。これは、元のデータと比較可能な統計的特性、パターン、関係を持つデータインスタンスを生成し、特に実データへのアクセスが制限されている、またはコストがかかる、プライバシーに敏感な状況で、実データの代替または補完として使用できます。
市場の成長を促進する要因として、データプライバシーの需要の高まり、機械学習のための大規模かつ多様なデータセットの必要性、人工知能(AI)やデータ駆動型技術の多くの産業での採用の増加が挙げられます。プライバシー保護ソリューションの普及に伴い、業界関係者の間でシミュレーションデータの需要が高まっています。また、機械学習の急成長により、合成データに注目が集まっています。AIや機械学習技術を利用することで、人工データは膨大なデータセットにアクセスします。
EUの一般データ保護規則(GDPR)やカリフォルニア州の消費者プライバシー法(CCPA)などの規制は、データプライバシーと遵守の重要性を強調しています。これらの規則は、企業に対して個人データの収集、処理、保護に関する基準を課しています。著名なデータ侵害事件は、データプライバシーとセキュリティ保護の強化の必要性を浮き彫りにしました。データ侵害を経験した企業は、重大な財務的損失や評判の損害を被ります。例えば、2017年のEquifaxのデータ侵害事件では、約1億4700万人の個人情報が漏洩し、同社はその後700百万ドルの和解金に同意しました。これらの事件は、データプライバシーの重要性と企業が機密情報を保護するために積極的な措置を講じる必要性を示しています。
合成データ生成市場のトレンドは、データ保護と遵守の重要性が高まっていることを示しており、これが市場の成長を促進しています。データ侵害や機密情報の漏洩によって、企業は財務的損失や追加の支出を被ります。インシデント対応、法医学的調査、影響を受けた人々への通知、より良いセキュリティ対策の導入などの修復作業には、相当な時間、リソース、お金の投資が必要です。これらの事故にかかる財務コストは、市場の成長と拡大の野望を妨げる可能性があります。IBMによると、データ侵害の全球平均コストは2022年に0.11百万米ドル増加し、4.35百万米ドルに達しました。この額は報告書の歴史上最高です。これはインシデント対応費用、法的手数料、規制罰金、顧客通知、評判の損害、潜在的な企業損失を含みます。リソースが限られた中小企業(SME)は、財務的影響を最も受けやすいと考えられます。
企業は業務効率を向上させるために、技術的に強化された方法を採用しています。AI、機械学習(ML)、ナノテクノロジーは合成データ生成ソリューション市場の成長を促進しています。企業は新しい技術を活用して、世界市場での存在感を確立し、追加の収入機会を生み出しています。さらに、合成データは、プライバシー、予測分析、セキュリティ、および全体的なデータ中心性といったデータ管理の問題を解決する上で重要な役割を果たします。
合成データ生成市場レポートは、今日のAIを利用した合成データ生成アルゴリズムが実データを消費し、その特性、相関関係、およびパターンを高い詳細度で学習し、その後、元のデータセットの統計的特性に一致する無限の量の完全に偽の合成データを生成することを示しています。現代の合成データセットはスケーラブルで、プライバシーに準拠し、すべての元の意味を保持しながら、機密情報の負担を除去します。このような革新は、今後数年で合成データ生成市場の成長を促進します。
北米は最大の市場シェアを占めており、予測期間中に34.26%のCAGRで成長すると予測されています。米国とカナダは、最終利用産業が詐欺検出、自然言語処理、画像データに対する関心を高めているため、魅力的な地域として浮上しています。J.P.モルガン、アメリカン・エキスプレス、アマゾン、グーグルのWaymoなどは、合成データへの投資を増やしています。例えば、アマゾンは2022年6月にラベル付き合成画像データを生成するためのAmazon SageMaker Ground Truthを導入しました。これらの業界参加者は、機械学習のトレーニング、詐欺検出のための支払いデータ、マネーロンダリング防止手法のために合成データを好むでしょう。さらに、コンピュータビジョンの拡大も、北米市場の合成データ生成の予測に良い影響を与えるでしょう。製造業、地理空間画像、物理的セキュリティが人気を集めています。例えば、2022年3月、ニューヨークとテルアビブに拠点を持つDatagenは、コンピュータビジョンチームのための合成データソリューションの開発を促進するために5000万米ドルのシリーズB資金を調達しました。また、自動運転車の普及がシミュレーションデータを地域全体で増加させています。シミュレーションデータを用いることで、自動運転車は限界ケースをテストし、事故の可能性を減少させることができるようになりました。米国などの先進経済国は、自動運転車の開発に伴う厳しいトレーニング要件に応じて、自動運転シミュレーションプラットフォームを強化しています。
アジア太平洋地域は36.84%のCAGRで成長し、最も急成長する地域になると予測されています。アジア太平洋地域では、人工知能の採用が急速に拡大しています。特に金融、小売、高技術産業においてAIの採用が進んでおり、中国のAI市場の3分の1以上を占めています。テクノロジー業界では、ByteDanceやAlibabaなど、中国の著名な企業がAI駆動の消費者向けアプリケーションを展開しており、新たな収益の創出に向けて顧客と新しい方法で関わる能力が求められています。これにより、AIアプリケーションの需要が増大しています。
ヨーロッパは32.89%のCAGRで成長すると予測されています。ドイツは合成データ生成のヨーロッパ市場の中で主導的な地位を占めています。ヨーロッパ諸国は非常に強力な電子産業を持っており、英国政府によれば、電子産業は英国経済に年間160億ポンドを貢献しています。この産業は、堅牢な知的財産権フレームワークと法的構造を持っており、迅速な製品市場投入が可能で、強力なソフトウェアセクターと大学、企業、業界からなる研究コミュニティを有しています。
中東およびアフリカ(MEA)では、人工知能(AI)およびそのさまざまな産業への応用に対する関心が高まっています。合成データ生成は、データプライバシーの懸念を解決し、AIモデルのトレーニングと開発を促進する可能性を秘めています。データプライバシーおよび遵守に関する規制は中東およびアフリカで注目を集めています。アラブ首長国連邦やサウジアラビアのような国々は、個人情報を保護するためにデータ保護法を制定しています。このデータプライバシーと遵守への注目の高まりは、合成データ生成のようなプライバシー保護ソリューションの需要を増加させる可能性があります。ラテンアメリカ諸国も他の地域と同様にプライバシー権を保護するためのデータ保護規則を制定しています。2020年にはブラジルが一般データ保護法(LGPD)を制定し、これは欧州のGDPRの原則と相関しています。これらの規則への遵守はプライバシー強化技術の発展を必要とする可能性があります。
市場は、データタイプに基づいてタブラーデータ、テキストデータ、画像動画データ、その他に分かれています。予測期間中、タブラーデータが最も多くの収益を上げると予想されています。タブラーデータとは、データベースやスプレッドシートにおいて行と列で整理された構造化データを指します。合成データ生成技術を用いることで、実世界のタブラーデータの統計的特性や関係を再現した人工タブラーセットを生成することが可能です。これはデータ増強、モデルのトレーニング、機密情報を共有する際のデータプライバシーの維持に役立ちます。画像および動画データセグメントは、データベースの拡張に対する需要が高まっているため、合成データ生成の市場シェアに大きく貢献すると予想されています。合成メディアは、元のデータの代替品として普及しています。合成画像や録音は自動車産業で非常に人気があります。
モデリングに基づいて、市場は直接モデリングとエージェントベースのモデリングに分かれています。エージェントベースのモデリングセグメントは最も多くの収益を生み出し、予測期間中に大幅な成長が見込まれています。エージェントベースのモデリングは、物理的で現実的なデータモデルを作成し、同じモデルを使用してデータを再現する能力から人気を集めています。最近では、エージェントベースのモデリングは金融分野で従来のモデルを上回り、ビジネストランザクションをシミュレートして詐欺検出システムをテスト・開発するために高い需要があります。業界参加者は、さまざまなタイプのネットワークをモデル化するためにABMを利用することが予想されます。さらに、ABMは消費者の相互作用、革新、自動車、道路のシミュレーションにおいても重要性を増しています。
提供に基づいて、市場は完全合成データ、部分合成データ、ハイブリッド合成データに分かれています。完全合成データセグメントは市場に最も貢献し、予測期間中に大幅な成長が見込まれています。完全合成データは、実世界のデータに依存せずに完全に人工的に生成されたデータセットを指します。生成されたデータには元のデータセットからの実際の観察は含まれません。生成型合成データは、生成対抗ネットワーク(GAN)や変分オートエンコーダ(VAE)などのAIモデルやアルゴリズムを使用して生成されます。このサービスは、データが限られている場合やアクセスできない場合、または実データの使用に関してプライバシーの懸念がある場合に便利です。
アプリケーションに基づいて、市場はデータ保護、データ共有、予測分析、自然言語処理、コンピュータビジョンアルゴリズム、その他に分かれています。自然言語処理(NLP)セグメントは最大の市場シェアを占め、予測期間中に大幅な成長が見込まれています。合成データは自然言語処理において急速に増加しており、新しい言語リリースの開発を促進しています。アマゾンは2019年10月に、スペイン語、ヒンディー語、ブラジルポルトガル語のAlexaのバリエーションを発表しました。会社は自然言語理解(NLU)システムのトレーニングデータを最適化し、増強するために合成データを強調しています。NLPの最近の進展は、企業の業務を加速するための合成データの必要性を加速させるでしょう。予測分析は、BFSI業界からの強力な需要によって推進される有望なアプリケーションセグメントとして浮上しています。追加の合成データを生成することで、企業は精度を向上させることができます。
このように、合成データ生成市場は、プライバシー保護のニーズやAI技術の急速な進展に伴い、ますます重要性を増しています。市場は多様なセグメントに分かれており、それぞれが独自の成長機会を提供しています。合成データ生成は、データプライバシーの問題を解決し、AIの進化を促進するための重要な要素となりつつあります。
Report Coverage & Structure
“`html
レポートの構造概要
このレポートは、合成データ生成市場に関する包括的な分析を提供しており、以下の主要なセクションに分かれています。
1. エグゼクティブサマリー
レポートの最初のセクションでは、合成データ生成市場の重要なポイントや全体の見通しが概説されています。市場のスコープやセグメンテーション、研究の目的、制約、および仮定がこの部分で明確にされています。
2. 市場機会評価
- 新興地域/国
- 新興企業
- 新興アプリケーション/エンドユーザー
このセクションでは、合成データ生成市場における新たな機会が探求され、新興地域や企業の特定が行われます。
3. 市場動向
- 市場の推進要因
- 警告要因
- 最新のマクロ経済指標
- 地政学的影響
- 技術的要因
市場のトレンドを分析し、合成データ生成の発展に影響を与える要因を評価します。
4. 市場評価
- ポーターのファイブフォース分析
- バリューチェーン分析
合成データ生成市場の競争環境と価値の流れを評価するための分析が含まれています。
5. 規制の枠組み
北米、ヨーロッパ、アジア太平洋、中東・アフリカ、ラテンアメリカの各地域における合成データ生成市場に関連する規制が詳述されています。
6. ESGトレンド
合成データ生成に関連する環境・社会・ガバナンス(ESG)のトレンドが考慮され、持続可能性の観点から市場がどのように進化しているかが示されています。
7. 地域別市場分析
北米およびヨーロッパ市場の分析が各データタイプ、モデリングタイプ、提供方法、アプリケーション、エンドユーザーに分かれて詳細に行われています。特に、米国とカナダの市場も個別に分析されています。
- 北米市場分析
- ヨーロッパ市場分析
それぞれの地域における合成データ生成の特性と市場規模が評価されています。
8. 結論
レポートは、合成データ生成市場の現在の状況と今後の展望を総括し、戦略的な意思決定に役立つ情報を提供しています。
“`
*** 本調査レポートに関するお問い合わせ ***

合成データ生成とは、人工的に生成されたデータのことを指します。このデータは、実際のデータに基づいて作成されることが多く、機械学習やデータ分析の分野で広く利用されています。合成データ生成の主な目的は、実際のデータが不足している場合や、プライバシーの保護が求められる状況において、データを補完するためです。例えば、医療データや個人情報を含むデータセットを扱う際には、実際のデータを使用することが難しい場合がありますが、合成データを使用することで、データ分析を行うことが可能になります。
合成データにはいくつかの種類があります。まず、完全にランダムに生成されたデータがあります。これは特定の分布に従って無作為に数字や文字列を生成する方法です。次に、実際のデータの特性を模倣して生成されるデータがあります。これは、統計的手法や機械学習モデルを用いて、実際のデータの分布や相関関係を学習し、それに基づいて新しいデータを生成するものです。最後に、シミュレーションを用いた合成データ生成があります。これは、特定のシナリオや条件に基づいてデータをシミュレーションし、現実世界に近いデータを作り出す方法です。
合成データ生成は、さまざまな分野で利用されています。例えば、健康管理の分野では、患者データを用いた研究や新しい治療法の開発において、合成データが活用されています。また、金融業界では、リスク分析や詐欺検出のために合成データを生成し、モデルの性能を向上させることが行われています。さらに、自動運転車の開発においては、リアルな運転状況をシミュレーションするために合成データが重要な役割を果たしています。
合成データ生成に関連する技術には、機械学習、特に生成モデルが含まれます。生成逆ネットワーク(GAN)や変分オートエンコーダ(VAE)は、合成データ生成において非常に有用な手法です。これらのモデルは、実際のデータの特徴を学習し、それを基に高品質な合成データを生成する能力を持っています。また、データ拡張技術も関連しています。これは、既存のデータを変換したり変形させたりすることで、新しいデータポイントを生成する方法であり、特に画像データの処理において広く使われています。
合成データ生成は、データの倫理的な取り扱いやプライバシー保護の観点からも重要です。実際のデータを使用する場合、個人情報の漏洩や不正利用のリスクが存在しますが、合成データを使用することで、これらのリスクを軽減することができます。従って、合成データ生成は、今後ますます重要な技術として注目されることでしょう。