ビジョントランスフォーマー市場規模・シェア分析:成長トレンドと予測 (2025-2030年)
ビジョントランスフォーマー市場レポートは、コンポーネント(ハードウェア、ソフトウェア、サービス)、アプリケーション(画像分類、画像キャプション、画像セグメンテーション、物体検出など)、展開モード(クラウド、オンプレミス、エッジ)、エンドユーザー(小売・Eコマース、メディア・エンターテイメント、自動車、政府・防衛など)、および地域ごとに区分されます。市場予測は、金額(米ドル)で提示されます。

※本ページの内容は、英文レポートの概要および目次を日本語に自動翻訳したものです。最終レポートの内容と異なる場合があります。英文レポートの詳細および購入方法につきましては、お問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
Vision Transformers市場の概要
本レポートは、Vision Transformers市場の規模、シェア、成長トレンド、および2025年から2030年までの予測を詳細に分析したものです。市場は、コンポーネント(ハードウェア、ソフトウェア、サービス)、アプリケーション(画像分類、画像キャプション、画像セグメンテーション、物体検出など)、展開モード(クラウド、オンプレミス、エッジ)、エンドユーザー(小売・Eコマース、メディア・エンターテイメント、自動車、政府・防衛など)、および地域別にセグメント化されています。市場予測は、金額(米ドル)で提供されています。
市場規模と成長予測
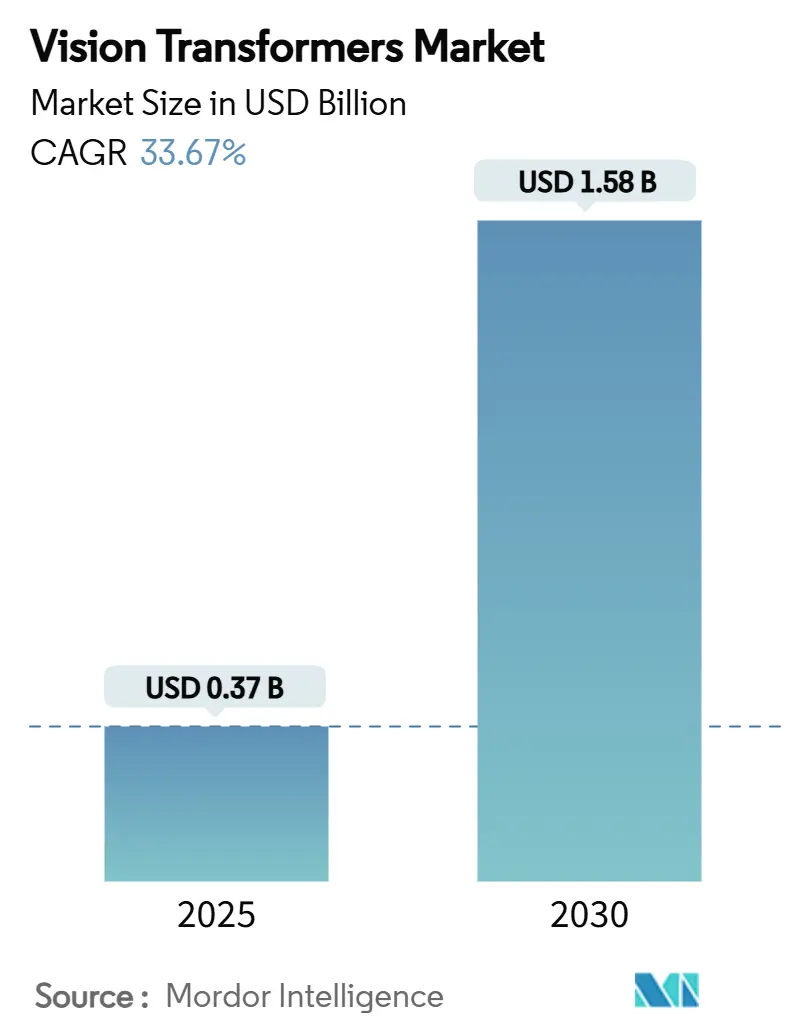
Vision Transformers市場は、2025年には0.37億米ドルに達し、2030年までに1.58億米ドルを超えると予測されており、予測期間中の年平均成長率(CAGR)は33.67%と非常に高い成長が見込まれています。これは、この期間に市場価値が327%増加することを示しています。この成長は、グローバルな画像コンテキストを捉え、従来のCNNモデルを一貫して上回るトランスフォーマーアーキテクチャによって推進されています。
市場の主要な動向と洞察
市場を牽引する要因:
1. 画像中心AIタスクにおける主流採用(CAGRへの影響度:+8.2%): 企業は複雑な視覚ワークフローにおいて顕著な精度向上を報告しており、Vision Transformersの導入が研究所の段階を超えて進んでいます。例えば、病理診断センターでは、6億3200万パラメータのモデルを展開することで、多クラスがん検出において94.11%の診断感度を達成し、意思決定支援を加速しています。製造業では、CNNが見逃しがちな微細な表面欠陥を特定するためにアテンションリッチなモデルを統合し、手動検査時間を38%削減しています。金融バックオフィスでは、ViT対応の文書解析が98%のフィールドレベル精度を達成し、紙ベースのエラーを抑制し、請求書照合を迅速化しています。これらの性能向上は、最高技術責任者(CTO)が視覚処理をトランスフォーマー基盤に移行させることを促し、市場の成長軌道を強化しています。
2. 高度なGPU、TPU、エッジAIチップの普及(CAGRへの影響度:+7.8%): ハイパースケーラーやシステムオンチップ設計者が新たなメモリ帯域幅と計算密度を解放するにつれて、ハードウェアサイクルは短縮されています。NVIDIA H200ボードは約30,000米ドルで、4.8 TB/sのスループットを提供し、700億パラメータのViTを30%少ないエポックでトレーニングすることを可能にします。同時に、MicrosoftのFlorence-2推論スタックは、Raspberry Piクラスのデバイスで15Wのエッジ動作を実証し、リソース制約のあるエンドポイントへのトランスフォーマーの関連性を拡大しています。高帯域幅メモリの不足は依然としてボトルネックですが、日本と韓国で新しいモジュールサプライヤーが規模を拡大するにつれて緩和されています。
3. 自律システムにおけるリアルタイム知覚の必要性(CAGRへの影響度:+6.9%): テスラから欧州のトラック隊列コンソーシアムに至るまでの自動運転プログラムは、計算コストを90%削減しつつコンテキスト精度を維持する軽量ViTによって駆動されるカメラのみの知覚に依存しています。防衛分野では、FPGAアクセラレーションされたViTが合成開口レーダー(SAR)フィード上での瞬時のターゲット認識を可能にし、海上哨戒機が混雑したシーンで戦闘艦と民間船を区別することを可能にしています。これらの低遅延が要求されるシナリオは、トランスフォーマーロジックを厳格な電力予算に収めるためのスパース化されたアテンションブロックと混合精度演算への需要を強調しています。
4. マルチモーダルな視覚言語トランスフォーマースタックの台頭(CAGRへの影響度:+5.4%): 開発者は、より豊かなクロスドメイン推論を可能にするために、Vision Transformersと大規模言語モデルを融合させています。Microsoftの42億パラメータのPhi-3 Visionは、マルチモーダル機能をエッジ展開可能なフットプリントに圧縮し、NVIDIAのVILAアーキテクチャはViTエンコーダーと量子化された言語デコーダーを組み合わせて、ビデオQ&Aでより大規模なベースラインを上回る性能を発揮します。画像とテキストの整合性を使用するEコマース検索エンジンは、買い物客がより関連性の高い視覚的マッチを受け取ることで、クリック率が4.95%向上しています。マルチモーダルの牽引力は、Vision Transformers市場の対象ベースを拡大し、顧客サービス、ロボティクス、コンテンツモデレーションのワークフローに影響を与えています。
市場を抑制する要因:
1. 高い計算コストと消費電力(CAGRへの影響度:-4.7%): クラウドベースのH100 GPUノードの価格は1時間あたり2.80米ドルから10.00米ドルの範囲であり、小規模企業にとっては実験が手の届かないものとなっています。データセンターのエネルギー使用量も急激に増加しており、700億パラメータのViTは単一のマルチエポックトレーニング実行中に1.2 MWhを消費する可能性があり、再生可能エネルギーオフセットを欠く施設に負担をかけています。組織は、クラウドでトレーニングし、量子化されたINT4重みをエッジアクセラレーターにエクスポートするハイブリッドパイプラインを通じてコストを軽減しています。メモリプーリングと構造化スパース性はアクティブ電力をさらに削減していますが、レガシーインフラストラクチャ全体での採用は不均一です。
2. データ集約的な事前学習要件(CAGRへの影響度:-3.2%): 基盤となるViTは、汎化するために数百万のラベル付き画像を必要とすることが多く、医療などの規制されたドメインではハードルとなります。Virchow病理モデルは、0.949 AUCを達成するために150万枚のスライドを必要としました。同様のデータ不足は、独自の画像を外部と共有できない産業検査でも見られます。合成データパイプラインは役立ちますが、過学習や幻覚を防ぐための堅牢な検証が必要です。EUのような厳格なデータ主権法を持つ地域では、国境を越えてトレーニングを連携させる際に複雑さが増し、開発サイクルが長くなり、Vision Transformers市場の成長を抑制しています。
セグメント分析
* コンポーネント別: ハードウェアが2024年の収益の55.34%を占め、計算能力の可用性が市場を支えていることを示しています。H200 GPUは、前世代よりも50%速い推論を提供し、大規模な実験を行う企業の反復時間を短縮しています。サービス層も拡大しており、クラウドベンダーはコンテナ化されたViTパイプラインをマネージドサービスとして提供し、中規模市場の採用者にとってDevOpsのオーバーヘッドを削減しています。エッジAIチップは33.73%のCAGRで成長しており、データセンタークラスのインテリジェンスを現場展開可能なプラットフォームに変換しています。
* アプリケーション別: 画像分類は2024年時点で46.98%のシェアを維持しており、製造業、小売業、医療診断におけるグローバルなピクセルコンテキストキャプチャの需要に支えられています。画像キャプションは33.87%のCAGRで最も速い成長を遂げています。EコマースポータルはViT-テキストデコーダーを組み込み、カタログメタデータを充実させ、製品の発見可能性を高める自動記述を生成しています。物体検出セグメントは、防衛および自動運転向けにトランスフォーマーバックボーンを活用しており、アテンション層がLiDARレスカメラアレイを統合して、まとまりのあるシーン理解を実現しています。
* 展開モード別: クラウドプラットフォームは、AWS、GCP、Azureの従量課金制GPUフリートのおかげで、2024年に65.74%のシェアを占めました。H200クラスターへのオンデマンドアクセスは、初期費用なしで大規模な実験を民主化しています。しかし、ロボティクス、スマートシティ、産業用IoTが100ミリ秒未満の低遅延とデータ主権推論を要求するため、エッジ展開は33.79%のCAGRで上昇しています。トレーニングはクラウド中心のままであり、蒸留または量子化されたモデルはエッジゲートウェイまたは車両計算モジュールに配置されるハイブリッドトポロジーが出現しています。
* エンドユーザー別: ヘルスケアおよびライフサイエンスは2024年の支出の28.41%を占め、放射線科、病理学、眼科でViTを活用しています。政府および防衛は33.94%のCAGRで最も速い動きを見せています。海上監視プログラムは、哨戒機にViT対応のSAR処理を統合し、船舶分類と異常検出を自動化しています。自動車OEMも、カメラのみのロボタクシーが商業化に近づくにつれて投資を拡大しています。
地域分析
* 北米: 2024年の市場価値の38.34%を占めました。GPUサプライヤー、クラウドハイパースケーラー、学術研究機関が密集しており、商業化サイクルを加速させています。AI支援診断に対するFDAの迅速承認経路も、ヘルスケア分野での導入をさらに後押ししています。
* アジア太平洋: 34.17%のCAGRで最も高い成長率を記録すると予測されています。中国の国家支援プログラムは、トランスフォーマーシリコンスタートアップに資金を投入し、2025年には980億米ドルのAI支出が見込まれています。日本は日本語ViTを優先する計算クラスターに9億6000万米ドルを計上し、インドのIndiaAIミッションは4,096 GPUのスーパークラスターに資金を提供しています。
* ヨーロッパ: 倫理的なAIを重視しています。EU AI法は、企業にエッジヘビーな展開と連合学習を促し、プライバシー保護型のViTトレーニングを支持しています。スカンジナビア諸国全体での低炭素データセンターへの補助金も、トランスフォーマーワークロードを引き付け、地域のエネルギー制約とのバランスを取っています。
競争環境
Vision Transformers市場は中程度の集中度を示しています。NVIDIAのハードウェアスタックが参入障壁を形成していますが、ソフトウェアのリーダーシップはGoogle(Universal Transformer特許)、Microsoft(Phi-3 Visionエッジモデル)、Meta(オープンソースViT派生)の間で争われています。クラウドの既存企業は、GPUとターンキーDevOpsをクロスセルし、概念実証までの時間を短縮しています。
戦略的焦点は垂直モデルに移行しており、Lockheed Martinはオンデバイスの暗号化強化を備えた防衛グレードのViTを調整し、新興の医療技術企業は病理学および放射線学ワークロードのFDA承認を追求しています。アテンションカーネルとメモリ効率の高いトランスフォーマーに関する特許訴訟は、ライセンスの複雑さを生み出し、少数のライセンサーの下でIPが統合される可能性があります。
エッジ最適化されたツールチェーンが次の戦場です。Qualcommのクロスビューアテンション特許とARMベースのNPU統合は、低電力エンドポイントでNVIDIAに対抗することを目指しており、GraphcoreとAMDは高密度データセンターシナリオをターゲットにしています。Jetson-VILAバンドルなどのシリコンベンダーとソフトウェアスタジオ間の戦略的提携が、2030年までの価値獲得を決定するでしょう。
主要な市場プレイヤー:
* NVIDIA Corporation
* Google LLC (Alphabet)
* Microsoft Corporation
* Meta Platforms Inc.
* Amazon Web Services Inc.
最近の業界動向:
* 2025年7月: Lockheed Martinは、自律型海上監視向けにViTを活用した合成開口レーダー(SAR)分析を発表し、オンボードMLOpsパイプラインを統合しました。
* 2025年7月: 中国のAIベンチャーへの海外投資は980億米ドルに達すると予測されており、スタートアップ企業はVision Transformers市場の研究開発に資金を投入しています。
* 2025年6月: SoftBankは、OpenAIと連携した超知能プログラムに332億米ドルを割り当てる計画を明らかにし、ポートフォリオ企業全体にViTを組み込むことを計画しています。
* 2024年6月: テスラは、完全自動運転ナビゲーションのためにカメラのみのViT知覚スタックを使用したロボタクシーの試験をオースティンで開始しました。
本レポートは、グローバルなVision Transformers市場に関する詳細な分析を提供しています。市場の定義、調査範囲、調査方法から、市場の現状、将来予測、競争環境、そして機会と課題までを網羅しています。
Vision Transformers市場は、2030年までに15.8億米ドルに達すると予測されており、予測期間中の年平均成長率(CAGR)は33.67%と、非常に高い成長が見込まれています。
市場成長の主要な推進要因としては、画像中心のAIタスクにおけるVision Transformersの主流化、高性能GPU/TPUおよびエッジAIチップの普及が挙げられます。また、自律システムにおけるリアルタイム認識の必要性、マルチモーダルなビジョン・言語トランスフォーマースタックの台頭、エッジ指向のスパース性および量子化技術のブレークスルーも貢献しています。さらに、オープンソースの基盤ViTモデルが参入障壁を下げていることも、市場拡大を後押ししています。
一方で、市場の成長を抑制する要因も存在します。高い計算コストと電力消費、データ集約型の事前学習要件が主な課題です。また、アテンション加速IPに関する特許の密集、トランスフォーマーによるハルシネーション(幻覚)に起因する規制上およびセキュリティ上のリスクも懸念されています。
市場は、コンポーネント(ハードウェア、ソフトウェア、サービス)、アプリケーション、展開モード、エンドユーザー、地域によって詳細にセグメント化されています。
アプリケーション別では、画像分類が2024年に46.98%のシェアを占め、ヘルスケア、製造、小売などの視覚ワークフローで広く採用されていることから、現在最も大きな支出を占めています。その他、画像キャプション、画像セグメンテーション、物体検出などが主要なアプリケーションとして挙げられます。
展開モード別では、エッジ展開が33.79%のCAGRで最も急速に成長しています。これは、レイテンシの削減、帯域幅コストの低減、データ主権コンプライアンスの容易化といった利点によるものです。クラウドおよびオンプレミス展開も引き続き重要な役割を担っています。
地域別では、アジア太平洋地域が34.17%のCAGRで最も高い成長潜在力を有しています。中国、インド、日本における大規模な政府AI投資がこの成長を牽引しています。北米、ヨーロッパ、南米、中東およびアフリカも重要な市場地域です。
エンドユーザー別では、小売・Eコマース、メディア・エンターテイメント、自動車、政府・防衛、ヘルスケア・ライフサイエンスなどが主要なセクターです。特に、小売・EコマースにおけるViTを活用したビジュアル検索、自動車分野におけるカメラベースの自律走行技術の進展、メディア企業における自動コンテンツキャプションの探索など、新たな分野での採用が拡大しています。
競争環境においては、NVIDIA Corporation、Google LLC、Microsoft Corporation、Meta Platforms Inc.、Amazon Web Services Inc.、Intel Corporation、Advanced Micro Devices (AMD)など、世界の主要なテクノロジー企業が多数参入しており、市場集中度、戦略的動向、市場シェア分析が詳細に報告されています。
高いGPU価格とエネルギー消費は、予測CAGRを約4.7パーセンテージポイント押し下げており、企業は量子化、スパース性、ハイブリッドクラウド・エッジ戦略の採用を促されています。
本レポートは、これらの市場動向、課題、機会を詳細に分析し、Vision Transformers技術の将来性と市場の成長戦略に関する貴重な洞察を提供しています。

1. はじめに
- 1.1 調査の前提と市場の定義
- 1.2 調査範囲
2. 調査方法
3. エグゼクティブサマリー
4. 市場概況
- 4.1 市場概要
- 4.2 市場の推進要因
- 4.2.1 画像中心のAIタスクにおける主流化
- 4.2.2 高度なGPU/TPUおよびエッジAIチップの普及
- 4.2.3 自律システムにおけるリアルタイム知覚の必要性
- 4.2.4 マルチモーダル視覚言語トランスフォーマースタックの台頭
- 4.2.5 エッジ指向のスパース性および量子化におけるブレークスルー
- 4.2.6 オープンソースの基盤ViTモデルによる参入障壁の低下
- 4.3 市場の阻害要因
- 4.3.1 高い計算コストと消費電力
- 4.3.2 データ量の多い事前学習要件
- 4.3.3 アテンション加速IP特許の密集
- 4.3.4 トランスフォーマーによるハルシネーションに起因する規制/セキュリティリスク
- 4.4 バリューチェーン分析
- 4.5 技術的展望
- 4.6 規制環境
- 4.7 ポーターの5つの力分析
- 4.7.1 新規参入者の脅威
- 4.7.2 供給者の交渉力
- 4.7.3 買い手の交渉力
- 4.7.4 代替品の脅威
- 4.7.5 競争上の対抗関係
5. 市場規模と成長予測(金額)
- 5.1 コンポーネント別
- 5.1.1 ハードウェア
- 5.1.2 ソフトウェア
- 5.1.3 サービス
- 5.2 アプリケーション別
- 5.2.1 画像分類
- 5.2.2 画像キャプション生成
- 5.2.3 画像セグメンテーション
- 5.2.4 物体検出
- 5.2.5 その他のアプリケーション
- 5.3 展開モード別
- 5.3.1 クラウド
- 5.3.2 オンプレミス
- 5.3.3 エッジ
- 5.4 エンドユーザー別
- 5.4.1 小売およびEコマース
- 5.4.2 メディアおよびエンターテイメント
- 5.4.3 自動車
- 5.4.4 政府および防衛
- 5.4.5 ヘルスケアおよびライフサイエンス
- 5.4.6 その他のエンドユーザー
- 5.5 地域別
- 5.5.1 北米
- 5.5.1.1 米国
- 5.5.1.2 カナダ
- 5.5.1.3 メキシコ
- 5.5.2 南米
- 5.5.2.1 ブラジル
- 5.5.2.2 アルゼンチン
- 5.5.2.3 その他の南米諸国
- 5.5.3 ヨーロッパ
- 5.5.3.1 ドイツ
- 5.5.3.2 英国
- 5.5.3.3 フランス
- 5.5.3.4 ロシア
- 5.5.3.5 その他のヨーロッパ諸国
- 5.5.4 アジア太平洋
- 5.5.4.1 中国
- 5.5.4.2 日本
- 5.5.4.3 インド
- 5.5.4.4 韓国
- 5.5.4.5 オーストラリア
- 5.5.4.6 その他のアジア太平洋諸国
- 5.5.5 中東およびアフリカ
- 5.5.5.1 中東
- 5.5.5.1.1 サウジアラビア
- 5.5.5.1.2 アラブ首長国連邦
- 5.5.5.1.3 その他の中東諸国
- 5.5.5.2 アフリカ
- 5.5.5.2.1 南アフリカ
- 5.5.5.2.2 エジプト
- 5.5.5.2.3 その他のアフリカ諸国
6. 競争環境
- 6.1 市場集中度
- 6.2 戦略的動向
- 6.3 市場シェア分析
- 6.4 企業プロファイル(グローバル概要、市場概要、主要セグメント、利用可能な財務情報、戦略情報、主要企業の市場ランキング/シェア、製品とサービス、および最近の動向を含む)
- 6.4.1 NVIDIA Corporation
- 6.4.2 Google LLC (Alphabet)
- 6.4.3 Microsoft Corporation
- 6.4.4 Meta Platforms Inc.
- 6.4.5 Amazon Web Services Inc.
- 6.4.6 Intel Corporation
- 6.4.7 Advanced Micro Devices (AMD)
- 6.4.8 Graphcore Ltd.
- 6.4.9 Qualcomm Technologies Inc.
- 6.4.10 Samsung Electronics Co.
- 6.4.11 Huawei Technologies Co.
- 6.4.12 IBM Corporation
- 6.4.13 Baidu Inc.
- 6.4.13 Tencent Holdings Ltd.
- 6.4.15 Alibaba Group Holding Ltd.
- 6.4.16 ARM Ltd.
- 6.4.17 Apple Inc.
- 6.4.18 Synopsys Inc.
- 6.4.19 Xilinx (AMD Adaptive Computing)
- 6.4.20 BrainChip Holdings Ltd.
7. 市場機会と将来の見通し
*** 本調査レポートに関するお問い合わせ ***

ビジョントランスフォーマー(Vision Transformer, ViT)は、深層学習における画像認識分野に革新をもたらしたモデルです。自然言語処理で成功したTransformerアーキテクチャを画像データに適用し、従来の畳み込みニューラルネットワーク(CNN)とは異なり、画像を固定サイズのパッチに分割し、単語のシーケンスのように扱います。各パッチは線形に埋め込まれ、位置エンコーディングが付加された後、Transformerエンコーダへ送られます。そこで自己注意(Self-Attention)メカニズムを通じて、画像全体におけるパッチ間のグローバルな関係性を捉えることが可能です。これにより、CNNの局所的な受容野の制約を超え、画像内の長距離依存関係を効率的に学習できる点が最大の特徴です。大規模データセットでの事前学習により、従来のCNNを凌駕する高い性能を発揮し、画像認識の新たな標準を確立しました。
ビジョントランスフォーマーには、基本形から派生した様々な種類が存在します。オリジナルのViTは大規模データセットでの事前学習が必須でしたが、DeiT(Data-efficient Image Transformers)は知識蒸留を導入し、少ないデータでも高性能なViTを訓練可能にしました。Swin Transformerは、計算コストとメモリ使用量の問題を解決し、物体検出やセマンティックセグメンテーションなどの密な予測タスクに適応。階層的処理とシフトウィンドウによる局所的自己注意で、計算効率を向上させつつ多スケスケール特徴を効果的に捉えることを可能にしました。
さらに、MAE(Masked Autoencoders)は、画像の一部をマスクし、残りの部分から元の画像を再構築する自己教師あり学習の手法を導入し、ラベル付きデータが少ない場合でも強力な事前学習モデルを構築できることを示しました。これらの派生モデルは、ViTの基本的なアーキテクチャの柔軟性と拡張性を示しており、様々な課題や制約に対応しながら、その適用範囲を広げています。
ビジョントランスフォーマーは、その登場以来、画像認識の分野に大きな変革をもたらしました。特に、大規模なデータと計算リソースを組み合わせることで、従来のCNNでは到達困難だった性能を達成し、多くのベンチマークでSOTA(State-of-the-Art)を更新しています。しかし、その一方で、膨大な計算コストや、CNNに比べて解釈性が低いといった課題も指摘されています。今後の研究では、これらの課題を克服し、より効率的で、かつ理解しやすいViTモデルの開発が進められることが期待されます。例えば、より軽量なアーキテクチャの設計、データ効率の良い学習方法、そしてモデルの内部動作を可視化し、その判断根拠を明確にするための研究などが挙げられます。